It should be SO EASY to share + collaborate on Markdown text files. The AI world runs on .md files. Yet frictionless Google Docs-style collab is so hard… UNTIL NOW, and how about that for a tease.
If you don't know Markdown, it's a way to format a simple text file with marks like \*\*bold\*\* and \# Headers and - lists… e.g. here's the Markdown for this blog post.
Pretty much all AI prompts are written in Markdown; engineers coding with AI agents have folders full of .md files and that's what they primarily work on now. A lot of blog posts too: if you want to collaborate on a blog post ahead of publishing, it's gonna be Markdown. Keep notes in software like Obsidian? Folders of Markdown.
John Gruber invented the Markdown format in 2004. Here's the Markdown spec, it hasn't changed since. Which is its strength. Read Anil Dash's essay How Markdown Took Over the World (2026) for more.
So it's a wildly popular format with lots of interop that humans can read+write and machines too.
AND YET… where is Google Docs for Markdown?
I want to be able to share a Markdown doc as easily as sharing a link, and have real-time multiplayer editing, suggested edits, and comments, without a heavyweight app in the background.
Like, the "source of truth" is my blog CMS or the code repo where the prompts are, or whatever, so I don't need a whole online document library things. But if I want to super quickly run some words by someone else… I can't.
I needed this tool at the day job, couldn't find it… built it, done.
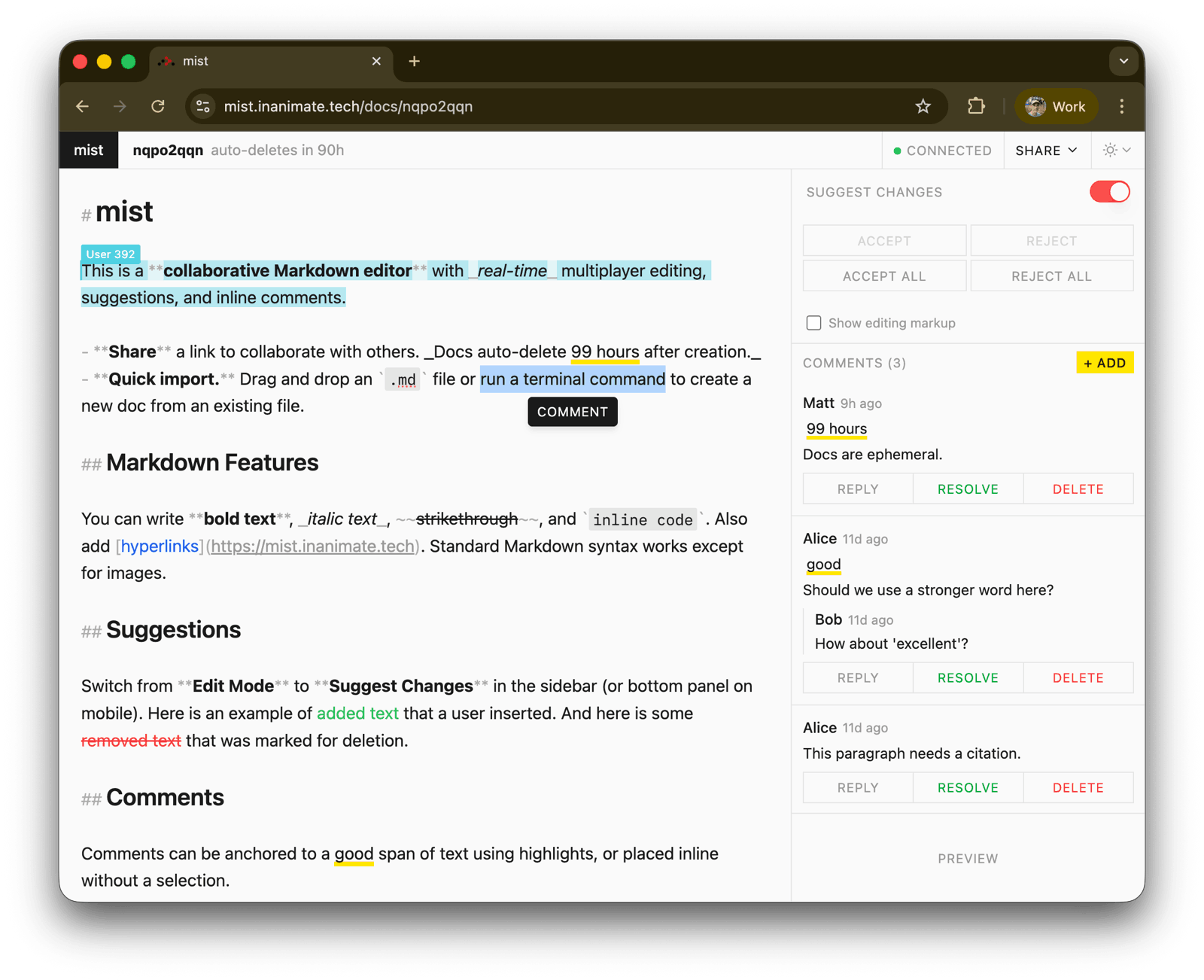
Say hi to mist!
- .md only
- share by URL
- real-time multiplayer editing
- comments
- suggest changes.
I included a couple of opinionated features…
- Ephemeral docs: all docs auto-delete 99 hours after creation. This is for quick sharing + collab
- Roundtripping: Download then import by drag and drop on the homepage: all suggestions and comments are preserved.
I'm proud of roundtripping suggested edits and comment threads: the point of Markdown is that everything is in the doc, not in a separate database, and you know I love files (2021). I used a format called CriticMark to achieve this - so if you build a tool like this too, let's interop.
Hit the New Document button on the homepage and it introduces itself.
Also!
For engineers!
Try this from your terminal:
curl https://mist.inanimate.tech -T file.md
Start a new collaborative mist doc from an existing file, and immediately get a shareable link.
EASY
Anyway -
It's work in progress. I banged it out over the w/e because I needed it for work, tons of bugs I'm sure so lmk otherwise I'll fix them while I use it… though do get in touch if you have a strong feature request which would unlock your specific use case because I'm keep for this to be useful.
So I made this with Claude Code obv
Coding with agents is still work: mist is 50 commits.
But this is the first project where I've gone end-to-end trying to avoid artisanal, hand-written code.
I started Saturday afternoon: I talked to my watch for 30 minutes while I was walking to pick my kid up from theatre.
Right at the start I said this
So I think job number one before anything else, and this is directed to you Claude, job number one before anything else is to review this entire transcript and sort out its ordering. I'd like you to turn it into a plan. I'll talk about how in a second.
Then I dropped all 3,289 words of the transcript into an empty repo and let Claude have at it.
Look, although my 30 mins walk-and-talk was nonlinear and all over the place, what I asked Claude to do was highly structured: I asked it to create docs for the technical architecture, design system, goals, and ways of working, and reorganise the rest into a phased plan with specific tasks.
I kept an eye at every step, rewinded its attempt at initial scaffolding and re-prompted that closely when it wasn't as I wanted, and jumped in to point the way on some refactoring, or nudge it up to a higher abstraction level when an implementation was feeling brittle, etc.
And the tests - the trick with writing code with agents is use the heck out of code tests. Test everything load bearing (and write tests that test that the test coverage is at a sufficient level). We're not quite at the point that code is a compiled version of the docs and the test suite… but we're getting there.
You know it's very addictive using Claude Code over the weekend. Drop in and write another para as a prompt, hang out with the family, drop in and write a bit more, go do the laundry… scratch that old-school Civ itch, "just one more turn." Coding as entertainment.
The main takeaway from my Claude use is that I asked for a collaborative Markdown editor 5 months ago:
app request
- pure markdown editor on the web (like Obsidian, Ulysses, iA Writer) - with Google Docs collab features (live cursor, comments, track changes) - collab metadata stored in file - single doc sharing via URL like a GitHub gist
am I… am I going to have to make this?
My need for that tool didn't go away.
And now I have it.
Multiplayer ephemeral Markdown is not what we're building at Inanimate but it is a tool we need (there are mists on Slack already) and it is also the first thing we've shipped.
A milestone!
So that's mist.
xx
More posts tagged: inanimate (2).
Auto-detected kinda similar posts:
- The emerging patchwork upgrade to the multiplayer web (27 Sep 2021)
What mundane pleasures will I be robbed of by domestic robots?
Sometimes I feel like my job at home is putting things into machines and taking things out of machines.
I don't mean to sound unappreciative about "modern conveniences" (modern being the 1950s) because I take care of laundry and emptying the dishwasher, and I love both. We have a two drawer dishwasher so that is a conveyer belt. And I particularly love laundry. We generate a lot of laundry it seems.
There was a tweet in 2025: "woodworking sounds really cool until you find out it's 90% sanding"
And it became an idiom because 90% of everything is sanding. See this reddit thread… 90% of photography is file management; 90% of baking is measuring; etc.
So when I say that I love laundry I don't mean that I love clean clothes (everyone loves clean clothes) but I love the sanding. I love the sorting into piles for different washes, I love reading the little labels, especially finding the hidden ones; I love the sequencing so we don't run out of room on the racks, I love folding, I love the rare peak moments when everything comes together and there are no dirty clothes anywhere in the house nor clean clothes waiting to be returned. (I hate ironing. But fortunately I love my dry cleaner and I feel all neighbourhood-y when I visit and we talk about the cricket.)
Soon! Domestic robots will take it all away.
Whether in 6 months or 6 years.
I don't know what my tipping point will be…
I imagine robots will be priced like a car and not like a dishwasher? It'll be worth it, assuming reliability. RELATED: I was thinking about what my price cap would be for Claude Code. I pay $100/mo for Claude right now and I would pay $1,500/mo personally for the same functionality. Beyond that I'd complain and have to find new ways to earn, but I'm elastic till that point.
Because I don't doubt that domestic robots will be reliable. Waymo has remote operators that drop in for ambiguous situations so that's the reliability solve.
But in a home setting? The open mic, open camera, and a robot arms on wheels - required for tele-operators - gives me pause.
(Remember that smart home hack where you could stand outside and yell through the letterbox, hey Alexa unlock the front door? Pranks aplenty if your voice-operated assistant can also dismantle the kitchen table.)
So let's say I've still got a few years before trust+reliability is at a point where the robot is unloading the dishwasher for me and stacking the dishes in the cupboard, and doing the laundry for me and also sorting and loading and folding and stacking and…
i.e. taking care of the sanding.
In Fraggle Rock the Fraggles live in their underground caves generally playing and singing and swimming (with occasional visits to an oracular sentient compost heap, look the 80s were a whole thing), and also they live alongside tiny Doozers who spend their days in hard hats industriously constructing sprawling yet intricate miniature cities.
Which the Fraggles eat. (The cities are delicious.)
Far from being distressed, the Doozers appreciate the destruction as it gives them more room to go on constructing.
Me and laundry. Same same.
Being good at something is all about loving the sanding.
Here's a quote about Olympic swimmers:
The very features of the sport that the 'C' swimmer finds unpleasant, the top level swimmer enjoys. What others see as boring-swimming back and forth over a black line for two hours, say-they find peaceful, even meditative, often challenging, or therapeutic. … It is incorrect to believe that top athletes suffer great sacrifices to achieve their goals. Often, they don't see what they do as sacrificial at all. They like it.
From The Mundanity of Excellence: An Ethnographic Report on Stratification and Olympic Swimmers (1989) by Daniel Chambliss (PDF).
But remember that 90% of everything is sanding.
With domestic appliances, sanding is preparing to put things into machines and handling things when you take them out of the machines.
This "drudgery" will be taken away.
So then there will be new sanding. Inevitably!
With domestic robots, what will the new continuous repetitive micro task be? Will I have to empty its lint trap? Will I have to polish its eyes every night? Will I have to go shopping for it, day after day, or just endlessly answer the door to Amazon deliveries of floor polish and laundry tabs? Maybe the future is me carrying my robot up the stairs and down the stairs and up the stairs and down the stairs, forever.
I worry that I won't love future sanding as much as I love today sanding.
If I got to determine the school curriculum, I would be optimising for collective efficacy.
So I live in a gentrified but still mixed neighbourhood in London (we're the newbies at just under a decade) and we have an active WhatsApp group.
Recently there was a cold snap and a road nearby iced over - it was in the shade and cyclists kept on wiping out on it. For some reason the council didn't come and salt it.
Somebody went out and created a sign on a weighted chair so it didn't blow away. And this is a small thing but I LOVE that I live somewhere there is a shared belief that (a) our neighbourhood is worth spending effort on, and (b) you can just do things.
Similarly we all love when the swifts visit (beautiful birds), so somebody started a group to get swift nest boxes made and installed collectively, then applied for subsidy funding, then got everyone to chip in such that people who couldn't afford it could have their boxes paid for, and now suddenly we're all writing to MPs and following the legislation to include swift nesting sites in new build houses. Etc.
It's called collective efficacy, the belief that you can make a difference by acting together.
(People who have heard of Greta Thunberg tend to have a stronger sense of collective efficacy (2021).)
It's so heartening.
You can just do things
That phrase was a Twitter thing for a while, and I haven't done the archaeology on the phrase but there's this blog post by Milan Cvitkovic from 2020: Things you're allowed to do.
e.g.
- "Say I don't know"
- "Tape over annoying LED lights"
- "Buy goods/services from your friends"
I read down the list saying to myself, yeah duh of course, to almost every single one, then hit certain ones and was like - oh yeah, I can just do that.
I think collective efficacy is maybe 50% taking off the blinkers and giving yourself (as a group) permission to do things.
But it's also 50% belief that it's worth acting at all.
And that belief is founded part in care, and part in faith that what you are doing can actually make a difference.
For instance:
A lot of my belief in the power of government comes from the fact that, back in the day, London's tech scene was not all that. So in 2009 I worked with Georgina Voss to figure out the gap, then in 2010 bizarrely got invited on a trade mission to India with the Prime Minister and got the opportunity to make the case about east London to them, and based on that No. 10 launched Tech City (which we had named on the plane), and that acted as a catalyst on the work that everyone was already doing to get the cluster going, and then we were off to the races. WIRED magazine wrote it up in 2019: The story of London's tech scene, as told by those who built it (paywall-busting link).
So I had that experience and now I believe that, if I can find the right ask, there's always the possibility to make things better.
That's a rare experience. I'm very lucky.
ALTHOUGH.
Should we believe in luck?
Psychologist Richard Wiseman, The Luck Factor (2003, PDF):
I gave both [self-identified] lucky and unlucky people a newspaper, and asked them to look through it and tell me how many photographs were inside. On average, the unlucky people took about two minutes to count the photographs whereas the lucky people took just seconds. Why? Because the second page of the newspaper contained the message "Stop counting - There are 43 photographs in this newspaper."
"Lucky people generate their own good fortune via four basic principles."
They are skilled at creating and noticing chance opportunities, make lucky decisions by listening to their intuition, create self-fulfilling prophesies via positive expectations, and adopt a resilient attitude that transforms bad luck into good.
I insist that people are not born lucky. I am sure that luck can be trained.
You can just be lucky?
(Well, not absolutely, I'm privileged too, but maybe let's recalibrate luck from where it is now, that's what I'm saying.)
When I was a kid I used to play these unforgivingly impossible video games - that's what home video games were like then. No open world play, multiple ways to win, or adaptive difficulty. Just pixel-precise platform jumps and timing.
Yet you always knew that there was a way onto the next screen, however long it took.
It taught a kind of stubborn optimism.
Or, in another context, "No fate but what we make."
Same same.
All of which makes me ask:
Could we invent free-to-plan mobile games which train luckiness?
Are there games for classrooms that would cement a faith in collective efficacy for kids?
Or maybe it's proof by demonstration.
I'm going into my kid's school in a couple of weeks to show them photos of what it looks like inside factories. The stuff around us was made by someone; it's not divine in origin; factories are just rooms.
I have faith that - somehow - this act will help.
You couldn't go a week in the 80s as a kid in Britain without someone saying "Oompa-Loompa stick it up your jumper."
You did this action too, pumping your hand to make a weird bulge under your jumper through a hoop made with one arm and a pretend arm made from an empty sleeve.
Entertainment before the internet!
(I never know if "jumper" is a word outside the UK? A sweater, a pullover.)
It's funny how these things come into your head after honestly decades. I think it's about having a kid of a certain age that erupts memories of being that age yourself.
Free association was developed by Freud in the 1890s and is a sort of interior Wikipedia rabbit-holing. It's a kind of divination of the self that reveals personal truths, inaccessible before you begin pulling the thread: "the logic of association is a form of unconscious thinking."
So I remembered this phrase and the admittedly peculiar trick (which is still entertaining as it happens) and went digging and it's not to do with Oompa-Loompas (Charlie and the Chocolate Factory was published in 1964) but actually spelt "umpa, umpa."
It was a common phrase apparently and was notably a song by The Two Leslies (I'd never heard of them) from 1935.
Here it is (YouTube). Listen!
A jolly comic song in classic BBC Received Pronunciation!
B-side, also on that YouTube: "Miss Porkington Would Like Cream Puffs."
A weird era in the UK.
In the shadow of the first war. So much loss, the vanishing of the old aristocracy and the rise of the middle class. Tensions rising ahead of the second war (the Nazis had already opened the concentration camps but nobody knew).
Also the transition to radio from the era of music hall and "variety," what the BBC would later term "light entertainment."
Then I listened to the lyrics.
And Umpa, Umpa opens with a bleak verse about the workhouse??
'Twas Christmas Day at the workhouse and you know how kind they are
Umpa, umpa, stick it up your jumper
Tra-la-la-la-la-la-la
The grub was drub, the meat was tough, the spuds had eyes like [prawns]
They said they were King Edwards but they looked more like King Kong's
The master said "this pud is good" and a pauper shouted "ah!"
Umpa, umpa, stick it up your jumper
Tra-la-la-la-la-la-la.
The workhouse system was quite the way of doing things.
They were established in 1631 as a way to "set poorer people to work" and, via the New Poor Law of 1834, evolved into a organised system of welfare and punishment that helped destitute people only if they entered a workhouse, where they were put to work in a fashion that was deliberately "generally pointless." The system was finally abolished in 1930.
So punative but I get the impression that somehow they saw it as a kindness?
I read the Wikipedia page on Workhouses and then on Boards of guardians - the workhouses were locally organised, run by "guardians" elected only by the landowners who paid the poor tax.
What made The Two Leslies think of workhouses for their song?
So Jung talks about synchronicity, moments of coincidence in the world or acausal interconnectedness, and my feeling is that by being attuned to and following these threads then you might dowse the collective unconsciousness (also an idea from Jung) and perhaps read the mind of society itself.
Now my kid goes to a club in Peckham on the weekends and there's a grand and beautiful old building that we pass on the way.
I've always noticed it.
It has a sundial at the top which has a slogan: "DO TODAY'S WORK TODAY"
I loved it, took a photo, posted on Insta.
Maybe this could be a motto for me? I thought.
I looked it up.
You guessed it, it was the HQ of the local Board of Guardians and once upon a time ran the local workhouses.
Here's a history of the Camberwell workhouses. (Camberwell and Peckham are neighbouring neighbourhoods.)
I say "ran" the workhouses.
Here are quotes about Peckham workhouses from the late 1800s:
it was used as a workhouse where the city paupers were farmed.
And
The master of the workhouse received a given sum per head for 'farming' his disorderly crew.
"Farmed."
Sundial mottos are always a little dark.
The Board of Governors sundial that I saw is listed in the British Sundial Society database and there's a whole book of sundial mottos called, well, A Book of Sundial Mottos (1903) which you can find on archive.org:
without . shadow . nothing
time . is . the . chrysalis . of . eternity
the . scythe . of . time . carries . a . keen . edge
as . the . hour . that . is . past, . so . life . flies
But even so, in the context of workhouses, Do Today's Work Today hits different.
Not to get too heavy but Albeit macht frei, Works Sets You Free, right? Auschwitz was opened in 1940.
An attitude that cynically connects work and redemption. Perhaps something in the air in the 1930s, these slogans don't come out of nowhere. Maybe that's what The Two Leslies were picking up on when they wrote their bit, without knowing it, with the Second World War still in the future, and the discovery of the camps even deeper into the future unknown, somehow the thread of that knowledge was there in 1935, something unsayable that the collective unconscious none-the-less found a way to say.
Umpa, umpa.
More posts tagged: dowsing-the-collective-unconscious (11).
AI agents do things for you, semi-autonomously, and one question is how we coordinate with them.
By "do things for you" I mean
- Claude Code that writes code while you contemplate life
- Claude Cowork, released this week, that does "knowledge work" tasks after you point it at your folder of docs (I just used it to collate income by source for my tax return after feeding it a folder of PDF bank statements, big time save)
- Research a trip away for you… find and book a restaurant for you… run your drop-shipping side hustle social media channels for you… (but the question is how the agent discovers the tools to use (2024))
- A robot that can tidy my front room which I'm sure we'll get at some point (2024)
(btw I use the heck out of Claude Code, despite there being better pure coding models available, proving that the difference is in the quality of the agent harness,_ i.e. how it approaches problems, and Anthropic has nailed that.)
By "coordinate" what I mean is: once you've stated your intent and the agent is doing what you mean (2025), or it's listened to you and made a suggestion, and it has actioned the tasks for that intent then how do you
- have visibility
- repair misunderstandings
- jump in when you're needed
- etc.
Hey did you know that
15 billion hours of time is spent every year by UK citizens dealing with administration in their personal lives.
Such as: "private bills, pensions, debt, services, savings and investments" (and also public services like healthcare and taxes).
It's called the time tax.
I was chatting with someone last week who has a small collection of home-brew agents to do things like translating medical letters into plain language, and monitoring comms from his kid's school.
It feels like small beans, agents that do this kind of admin, but it adds up.
Every agent could have its own bespoke interface, all isolated in their own windows, but long-term that doesn't seem likely.
See, agents have common interface requirements. Apps need buttons and lists and notifications; agents need… what?
What is particular to agents is that they need progress bars not notifications (2023): after decades of making human-computer interaction almost instantaneous, suddenly we have long-running processes again. "Thinking…"
Agents sequence tasks into steps, and they pause on some steps where clarification is needed or, for trust reasons, you want a human in the loop: like, to approve an email which will be sent in the user's name, or a make a payment over a certain threshold, or simply read files in a directory that hasn't been read before.
Claude Code has nailed how this works re: trust and approvals. Let's say you're approving a file edit operation. The permission is cleverly scoped to this time only, this session, or forever; and to individual files and directories.
Claude Code has also nailed plans, an emerging pattern for reliability and tracking progress: structured lists of tasks as text files.
Ahead of doing the work, Claude creates a detailed plan and stores it in one of its internal directories.
You can already entice Claude to make these plans more visible - that's what I do, structuring the work into phases and testing for each phase - and there's discussion about making this a built-in behaviour.
Want to see a sample plan file? It's just some context and a list of to-dos. Check out My Claude Code Workflow And Personal Tips by Zhu Liang.
So… if agents all use plans, put all those plans in one place?
Another quality that is particular to agents is that when you're running multiple agents each running down its personal plan, and you have a bunch of windows open and they're all asking for permissions or clarifications or next instructions, and it feels like plate spinning and it is a ton of fun.
Task management software is a great way to interact with many plans at once.
Visually, think of a kanban board: columns that show tasks that are upcoming, in progress, for review and done (and the tasks can have subtasks).
Last week on X, Geoffrey Litt (now at Notion) showed a kanban board for managing coding agents: "When an agent needs your input, it turns the task red to alert you that it's blocked!"
There's something in the air. Weft (open source, self-hosted) is
a personal task board where AI agents work on your tasks. Create a task, assign it to an agent, and it gets to work. Agents can read your emails, draft responses, update spreadsheets, create PRs, and write code.
It is wild. Write something like "Create a cleaned up Google Doc with notes from yesterday's standup and then send me an email with the doc link" and then an agent will write actual code to make the doc, summarise the notes, connect to your Gmail etc.
This is great in that you can instruct and then track progress in the same place, you can run many tasks simultaneously and async, and when you jump in to give an approach then you can immediately see all the relevant context.
Ok great self-driving to-do lists.
But wouldn't it be great if all my agents used the same task manager?
Is it really worth special-casing the AI agent here?
Linear is a work to-do list. Sorry, a team collaboration tool oriented around tickets.
Linear for Agents is smart in that they didn't launch any agents themselves, they simply built hooks to allow AI agents to appear like other users, i.e. the agent has an avatar; you can tag it etc:
Agents are full members of your Linear workspace. You can assign them to issues, add them to projects, or @mention them in comment threads.
(Agents are best seen as teammates (2023).)
In the general case what we're talking about is a multiplayer to-do list which AI agents can use too.
Really this is just the Reminders app on my iPhone?
Long term, long term, the Schelling point for me, my family, and future AI agents is a task manager with well-scoped, shared to-do lists that I already look at every day.
Apple is incredibly well placed here.
Not only do they have access to all my personal context on the phone, but it turns out they have a great coordination surface too.
So Apple should extend Reminders to work with agents, Linear for Agents style. Let any agent ask for permission to read and write to a list. Let agents pick up tasks; let them add sub-tasks and show when something is blocked; let me delegate tasks to my installed agents.
Then add a new marketplace tab to discover (and pay for) other agents to, I don't know, plan a wedding, figure out my savings, help with meal planning, chip away at some of that billions of hours of time tax.
The Reminders app is a powerful and emerging app runtime (2021) - if Apple choose to grab the opportunity.
Auto-detected kinda similar posts:
- Mapping the landscape of gen-AI product user experience (19 Jul 2024)
- Let me recruit AI teammates into Figma (26 Oct 2022)
- Observations on Siri, Apple Intelligence, and hiding in plain sight (11 Jun 2024)
- No apps no masters (9 Aug 2024)
- Diane, I wrote a lecture by talking about it (20 Mar 2025)
This chart from the back of Ursula Le Guin's Always Coming Home lives forever in my head:

Always Coming Home is a collection of texts from the Kesh, a society in far future Northern California which is also, I guess, a utopian new Bronze Age I suppose? A beautiful book.
This chart is in in the appendix. It reminds me that
- we bucket stories of types like journalism and history as "fact" and types like legend and novels as "fiction," this binary division
- whereas we could (like the Kesh) accept that no story is clearly fact nor fiction, but instead is somewhere on a continuum.
Myth often has more truth in it than some journalism, right?
There's a nice empirical typology that breaks down real/not real in this paper about the characters that kids encounter:
To what extent do children believe in real, unreal, natural and supernatural figures relative to each other, and to what extent are features of culture responsible for belief? Are some figures, like Santa Claus or an alien, perceived as more real than figures like Princess Elsa or a unicorn? …
We anticipated that the categories would be endorsed in the following order: 'Real People' (a person known to the child, The Wiggles), 'Cultural Figures' (Santa Claus, The Easter Bunny, The Tooth Fairy), 'Ambiguous Figures' (Dinosaurs, Aliens), 'Mythical Figures' (unicorns, ghosts, dragons), and 'Fictional Figures' (Spongebob Squarepants, Princess Elsa, Peter Pan).
(The Wiggles are a children's musical group in Australia.)
btw the researchers found that aliens got bucketed with unicorns/ghosts/dragons, and dinosaurs got bucketed with celebrities (The Wiggles). And adults continue to endorse ghosts more highly than expected, even when unicorns drop away.
Ref.
Kapit'any, R., Nelson, N., Burdett, E. R. R., & Goldstein, T. R. (2020). The child's pantheon: Children's hierarchical belief structure in real and non-real figures. PLOS ONE, 15(6), e0234142. https://doi.org/10.1371/journal.pone.0234142
What I find most stimulating about this paper is what it doesn't touch.
Like, it points at the importance of cultural rituals in the belief in the reality of Santa. But I wonder about the role of motivated reasoning (you only receive gifts if you're a believer). And the coming of age moment where you realise that everyone has been lying to you.
Or the difference between present-day gods and historic gods.
Or the way facts about real-ness change over time: I am fascinated by the unicorn being real-but-unseen to the Medieval mind and fictional to us.
Or how about the difference between Wyatt Earp (real) and Luke Skywalker (not real) but the former is intensely fictionalised (the western is a genre and public domain, although based on real people) whereas Star Wars is a "cinematic universe" which is like a genre but privately owned and with policed continuity (Star Wars should be a genre).
I struggle to find the words to tease apart these types of real-ness.
Not to mention concepts like the virtual (2021): "The virtual is real but not actual" - like, say, power, as in the power of a king to chop off your head.
So I feel like reality is fracturing this century, so much.
Post-truth and truthiness.
The real world, like cyberspace, now a consensual hallucination - meaning that fiction can forge new realities. (Who would have guessed that a post on social media could make Greenland part of the USA? It could happen.)
That we understand the reality that comes from dreams and the subjectivity of reality…
Comedians doing a "bit," filters on everything, celebrities who may not exist, body doubles, conspiracy theories that turn out to be true, green screen, the natural eye contact setting in FaceTime…
Look, I'm not trained in this. I wish I were, it has all been in the academic discourse forever.
Because we're not dumb, right? We know that celebs aren't real in the same sense that our close personal friends are real, and - for a community - ghosts are indeed terrifically true, just as the ghost in Hamlet was a consensus hallucination made real, etc.
But I don't feel like we have, in the mainstream, words that match our intuitions and give us easy ways to talk about reality in this new reality. And I think we could use them.
Hello! This is my summary of 2025 and the "start here" post for new readers. Links and stats follow…
According to Fathom, my most trafficked posts of 2025 were (in descending order):
- Context plumbing (29 Nov)
- Extending AI chat with Model Context Protocol (and why it matters) (11 Feb)
- Reflections on 25 years of Interconnected (19 Feb)
- tl;dr I ran a marathon at the weekend and it was hard (4 Apr)
- The destination for AI interfaces is Do What I Mean (8 Aug)
Here are all the most popular posts: 20 most popular in 2025.
Even more AI than last year.
My personal faves aren't always the ones that get the most traffic…
- Homing pigeons fly by the scent of forests and the song of mountains
- Keeping the seat warm between peaks of cephalopod civilisation
- Diane, I wrote a lecture by talking about it
Also MAGA fashion, pneumatic elevators, and what the play Oedipus is really about.
Check out my speculative faves from 2025.
Also check out the decade-long Filtered for… series.
Links and rambling interconnectedness. I like these ones.
Posts in 2025 include:
- Filtered for minimum viable identity (2 Feb) about how theory of mind is attributed
- Filtered for the rise of the well-dressed robots (28 Mar) about robot fashion
- Filtered for hats (29 May) about hats, freedom and smurfs
- Filtered for bottom-up global monitoring (1 Aug) on cool global sensor networks.
And more.
Here's the whole Filtered for… series. 2025 posts at the top.
Looking back over 2025, I've been unusually introspective.
Possibly because I hit my 25th anniversary with this blog? (Here are my reflections and a follow-up interview.)
Or something else, who knows.
Anyway here's a collection from this year:
- Strava when you're not as quick as you used to be (30 Jan)
- tl;dr I ran a marathon at the weekend and it was hard (10 Apr)
- Copyright your faults (25 Jul)
- It all matters and none of it matters (4 Aug)
- Parables involving gross bodily functions (10 Oct)
In other writing, I…
- wrote a short series about AI consciousness
- took a trip to Shenzhen, China where I'm completing my manufacture of Poem/1
- started talking about Inanimate, my new startup and where most of my attention + design/engineering energy is going rn.
A talk I did in June for a WIRED event has just broken a million views. Watch AI Agents: Your Next Employee, or Your Next Boss (YouTube).
PREVIOUSLY!
- My top posts in 2024
- My most popular posts in 2023 and other lists
- My most popular posts in 2022 and other lists
- My most popular posts in 2021 and other lists
- My most popular posts in 2020 and other lists
Other ways to read:
- Receive new posts as an email newsletter.
- Subscribe to the RSS feed using your newsreader.. (RSS is great. Learn about what it is and how to get started.)
Or just visit the website: interconnected.org/home.
If you read a post you like, please do pass it along and share on the discords or socials or whatever new thing.
I like email replies. I like it when people send me links they think I'll enjoy (they're almost always correct). I especially like hearing about how a post has had a flapping-of-the-butterfly's-wings effect somehow, whether personally or at work.
I like talking to people most of all. I started opening my calendar for Unoffice Hours over 5 years ago. 400+ calls later and it's still the highlight of my week. Learn more and book a time here.
You should totally start a blog yourself.
Here are my 15 personal rules for blogging.
If you're interested in my tech stack, here's the colophon.
But really, use whatever tech makes it easy for you to write. Just make sure your blogging or newsletter platform lets you publish your posts with an RSS feed. That's a great marker that you own your own words.
Stats for the stats fans.
- 2025: 61 posts (58,160 words, 549 links)
- 2024: 60 posts (62,670 words, 586 links)
- 2023: 68 posts (69,067 words, 588 links)
- 2022: 96 posts (104,645 words, 712 links)
- 2021: 128 posts (103,682 words, 765 links)
My current streak: I've been posting weekly or more for 301 weeks.
Looking back over 2025, I'm increasingly straddling this awkward divide:
- long posts about AI on applications (like using transcription to write posts) or context plumbing or prompting for multiplayer turn-taking or thoughts about Claude code
- and everything else.
Where "everything else" is everything from policy suggestions on the need for a strategic fact reserve to going to algoraves to my other speculative faves this year.
Whereas the more bloggy spitball thoughts (which I love, and this is mainly what I wrote in 2020/21/22) are now relegated to occasional compilation posts a.k.a "scraps" - it would be great to give these more space but that doesn't seem to be where my time is going.
I don't know what to do about this.
I don't know if I need to do anything about this.
One of the big reasons that I write here is that it's my public notebook and so it's this core sample that cuts across everything that I'm thinking about, which is indeed a weird admixture or melange, and that's precisely the value for me because that's how new ideas come, even if that makes this blog hard to navigate and many visitors will just bounce off.
All of which makes me appreciate YOU all the more, dear reader, for sticking with.
Happy 2026.
More posts tagged: meta (20).
Auto-detected kinda similar posts:
- From the archives, w/e 4 June (4 Jun 2021)
- Previously: eye contact and puppy slugs (w/e 25 June) (25 Jun 2021)
- Previously: Spreadsheet parties, chatbots, William Gibson's jacket (w/e 18 June) (18 Jun 2021)
- Interconnected is 20 years old today (19 Feb 2020)
I'm away with family this week so here are some more scraps from my notes (previously).
Disney is considering a reboot of the Indiana Jones franchise. Goodness knows how many Jurassic Park movies there are.
We need to create new IP.
Culture creates new ideas downstream. Without new IP, it's like trying to feed yourself by eating your own arm.
So: moratorium on re-using IP in movies. The UK makes heavy use of movie subsidies. We should use this to disincentivise anything sits inside an existing franchise. If a movie's success is likely more to do with existing mindshare than its content, don't support it.
Radically reduce copyright down to 10 years or something. More than that: invent a new super-anti-copyright which actively imposes costs on any content which is too close to any existing content in an AI-calculated vibes database or something.
i.e. tax unoriginality.
The past is a foreign country that we should impose tariffs on.
There's a kind of face that we don't get anymore.
Neil Armstrong, Christopher Reeve as Superman, Keir Dullea as Dave Bowman in 2001.
I don't know how to characterise it: open, emotionally imperturbable. happy. Where did it go?
I'm at the cricket today and England are losing. It's an interesting feeling to be with, losing, especially while 90,000 people in the stadium (plus some visiting fans) are yelling for the winners - Australia, at this point.
I have zero memory for where cutlery goes in the cutlery drawer. I don't consciously look when I take things out but if everything was moved around, it wouldn't make any difference. On the occasions that all the knives, forks and spoons have been used and I'm unloading the dishwasher (which I do daily), I cannot for the life of me remember which sections they go in, so I return them in any old order. Raw extended mind.
A few weeks ago I was on a zoom call where someone had a standing mirror in their room in the background. I've never seen that before. It kept me weirdly on edge throughout like it violated some previously unstated video call feng shui or something.
(I had another call in which the person's screen was reflected in a shiny window behind them and so I could see my own face over their shoulder. But that seemed fine. This was not the same.)
My disquiet came because the mirror was angled such that it showed an off-screen part of the room. I could see beyond the bounds; it broke the container.
More posts tagged: scraps-from-the-scraps-file (3).
Why Were All the Bells in the World Removed? The Forgotten Power of Sound and Frequency (Jamie Freeman).
Church bells: "something strange happened in the 19th and 20th centuries: nearly all of the world's ancient bells were removed, melted down, or destroyed."
(I don't know whether that's true, but go with it for a second.)
Why? Mainstream historians attribute this mass removal to wars and the need for metal, but when you dig deeper, the story doesn't add up.
An explanation:
Some theorists believe that these bells were part of a Tartarian energy grid, designed to harmonise human consciousness, balance electromagnetic fields, and even generate free energy. Removing the bells would have disrupted this energy network, cutting us off from an ancient technology we no longer understand.
Tartarian?
Tartarian Empire (Wikipedia):
2.Tartary, or Tartaria, is a historical name for Central Asia and Siberia. Conspiracy theories assert that Tartary, or the Tartarian Empire, was a lost civilization with advanced technology and culture.
Risky Wealth: Would You Dare to Open the Mysterious Sealed Door of Padmanabhaswamy Temple? (Ancient Origins).
"The Padmanabhaswamy Temple is a Hindu temple situated in Thiruvananthapuram, Kerala, a province on the southwestern coast of India."
It has a mysterious Vault B with an as-yet-unopened sealed door.
One of the legends surrounding Vault B is that it is impossible at present to open its door. It has been claimed that the door of the vault is magically sealed by sound waves from a secret chant that is now lost. In addition, it is claimed that only a holy man with the knowledge of this chant would be capable of opening the vault's door.
Maybe the chant was intended to tap Tartarian energies.
3.Claims that former US military project is being used to manipulate the weather are "nonsense" (RMIT University).
HAARP is a US research program that uses radio waves to study the ionosphere (Earth's upper atmosphere) and cannot manipulate weather systems.
PREVIOUSLY:
Artificial weather as a military technology (2020), discussing a 1996 study from the US military, "Weather as a Force Multiplier: Owning the Weather in 2025."
4.What conspiracy theorists get right (Reasonable People #42, Tom Stafford).
Stafford lists 4 "epistemic virtues" of conspiracy theorists:
- "Listening to other people"
- "A healthy skepticism towards state power"
- "Being sensitive to hidden coalitions"
- "Willing to believe the absurd"
As traits in a search for new truths, these are good qualities!
Where is goes wrong is "the vices of conspiracy theory seem only to be the virtues carried to excess."
Let's try to keep the right side of the line folks.
More posts tagged: filtered-for (120).
My new fave thing to go to is live coding gigs, a.k.a. algoraves.
There are special browser-based programming languages like strudel where you type code to define the beats and the sound, like mod synth in code, and it plays in a loop even while you're coding. (The playhead moves along as a little white box.)
As you write more code and edit the code, you make the music.
So people do gigs like this: their laptop is hooked up to (a) speakers and (b) a projector. You see the code on the big screen in real-time as it is written and hear it too.
Here's what it looks like (Instagram).
That pic is from a crypt under a church in Camberwell at an event called Low Stakes | High Spirits.
(There are more London Live Coding events. I've been to an AlgoRhythm night too and it was ace.)
It helps that these beeps and boops are the kind of music I listen to anyway.
But there is something special about the performer performing right there with the audience and vibing off them.
Like all art, there's some stuff you prefer and some not so much, and sometimes you'll get some music that is really, really what you're into and it just builds and builds until you're totally transported.
So you take a vid or a pic of what's going on, wanting to capture the moment forever, and what you see when you're going back through your photo library the next day is endless pics of a bunch of code projected on the wall and you're like, what is this??
You have to be there.
(I suppose though it also means you can try out some of the code for yourself? View Source but for live music?)
Actually that's art isn't it.
All art galleries are a bit weird eh. Each time you visit, there are a hundred paintings scattered in rooms and you walk through like uh-huh, uh-huh, ok, that's nice, uh-huh, ok. Then at random one of them skewers you through your soul and you're transfixed by the image for life.
Often what happens is the musician is not alone!
There is also live coding software for visuals e.g. hydra. (hydra is browser-based too so you can try it right now.)
So the person live coding visuals sits right next to the person live coding music, with the music and the visuals projected side-by-side on adjacent big screens. Code overlaid on both.
The visuals don't necessarily automatically correspond to the music. There may be no microphone involved.
The visuals person and the music person are jamming together but really not off each other directly; both are doing their thing but steering in part by the audience, which itself is responding to the music and visuals together.
So you get this strange loop of vibes and it's wonderful.
I hadn't expected to see comments in code.
At the last night I went to, the musician was writing comments in the code, i.e. lines of code that start with // so they are not executed but just there.
The comments like the rest of the code are projected.
There were comments like (not verbatim because this is from memory):
// i'll make it faster. is this good?
And:
// my face is so red rn this is my first time
So there's this explicit textual back-channel to the audience that people can read and respond to, separately to the music itself.
And I love the duality there, the two voices of the artist.
You get something similar at academic conferences?
I feel like I must have mentioned this before but I can't find it.
One of my great joys is going to academic conferences and hearing people present work which is at the far reaches of my understanding. Either sciences/soft sciences or humanities, it's all good.
My favourite trope is when the researcher self-glosses.
So they read out their paper or their written lecture, and that's one voice with a certain tone and authority and cadence.
Then every couple of paras they shift their weight on their feet, maybe tilt their head, then add an extended thought or a side note, and their voice becomes brighter and more conversational, just for the duration of that sidebar.
Then they drop back into the regular tone and resume their notes.
Transcribed, a talk like this would read like a single regular essay.
But in person you're listening to the speaker in dialogue with themselves and it's remarkable, I love it, it adds a whole extra dimension of meaning.
If you're an academic then you'll know exactly what I mean. I've noticed these two voices frequently although culture/media studies is where I spot it most.
In Samuel Delaney's Stars in My Pocket Like Grains of Sand (Amazon) - one of my favourite books of all time - there is a species called evelmi and they have many tongues.
I swear there is a scene in which an evelm speaks different words with different tongues simultaneously.
(I can't find it for you as I only have the paperback and it's been a while since my last re-read.)
But there's a precision here, right? To chord words, to triangulate something otherwise unreachable in semantic space or to make a self-contradicting statement, either playfully or to add depth and intention.
Anyway so I love all these dualities at these live coding nights: the music and visuals, the code and the comments, the genotype which I read and the phenotype which I hear
It's an incredibly welcoming scene here in London - lots of young people of course who doing things that are minimum 10x cooler than anything I did at that age, and older people too, everyone together.
You know:
Last week the local pub had a band singing medieval carols and suddenly I got that adrift in time, atemporal feeling of knowing that I'm in the company of listeners who have been hearing these same songs for hundreds of years, an audience that is six hundred years deep.
(There was also a harp. Gotta love a harp.)
I never think of myself as a live music person but give me some folk or choral or modern classical or opera and I'm lost in it.
Or, well, electronica, but that's more about the dancing.
Or the time that dude had a 3D printed replica of a Neanderthal bone flute, the oldest known musical instrument from 50,000 years ago if I remember it right, and he improv'd ancient music led by the sound of the instrument itself as we drove through the Norwegian fjords and holy shit that was a transcendent moment that I will remember forever.
More posts tagged: 20-most-popular-in-2025 (20).
I left a loose end the other day when I said that AI is about intent and context.
That was when I said "what's context at inference time is valuable training data if it's recorded."
But I left it at that, and didn't really get into why training data is valuable.
I think we often just draw a straight arrow from "collect training data," like ingest pages from Wikipedia or see what people are saying to the chatbot, to "now the AI model is better and therefore it wins."
But I think it's worth thinking about what that arrow actually means. Like, what is the mechanism here?
Now all of this is just my mental model for what's going on.
With that caveat:
To my mind, the era-defining AI company is the one that is the first to close two self-accelerating loops.
Both are to do with training data. The first is the general theory; the second is specific.
Training data for platform capitalism
When I say era-defining companies, to me there's an era-defining idea, or at least era-describing, and that's Nick Srnicek's concept of Platform Capitalism (Amazon).
It is the logic that underpins the success of Uber, Facebook, Amazon, Google search (and in the future, Waymo).
I've gone on about platform capitalism before (2020) but in a nutshell Srnicek describes a process whereby
- these companies create a marketplace that brings together buyers and sellers
- they gather data about what buyers want, what sellers have, how they decide on each other (marketing costs) and how decisions are finalised (transaction costs)
- then use that data to (a) increase the velocity of marketplace activity and (b) grow the marketplace overall
- thereby gathering data faster, increasing marketplace efficiency and size faster, gathering data faster… and so on, a runaway loop.
Even to the point that in 2012 Amazon filed a patent on anticipatory shipping in 2012 (TechCrunch) in which, if you display a strong intent to buy laundry tabs, they'll put them on a truck and move them towards your door, only aborting delivery if you end up not hitting the Buy Now button.
And this is also kinda how Uber works right?
Uber has a better matching algorithm than you keeping the local minicab company on speed dial on your phone, which only works when you're in your home location, and surge pricing moves drivers to hotspots in anticipation of matching with passengers.
And it's how Google search works.
They see what people click on, and use that to improve the algo which drives marketplace activity, and AdSense keyword cost incentivises new entrants which increases marketplace size.
So how do marketplace efficiency and marketplace size translate to, say, ChatGPT?
ChatGPT can see what success looks like for a "buyer" (a ChatGPT user).
They generate an answer; do users respond well to it or not? (However that is measured.)
So that usage data becomes training data to improve the model to close the gap between user intent and transaction.
Right now, ChatGPT itself is the "seller". To fully close the loop, they'll need to open up to other sellers and ChatGPT itself transitions to being the market-maker (and taking a cut of transactions).
And you can see that process with the new OpenAI shopping feature right?
This is the template for all kinds of AI app products: anything that people want, any activity, if there's a transaction at the end, the model will bring buyers and sellers closer together - marketplace efficiency.
Also there is marketplace size.
Product discovery: OpenAI can see what people type into ChatGPT. Which means they know how to target their research way better than the next company which doesn't have access to latent user needs like that.
So here, training data for the model mainly comes from usage data. It's a closed loop.
But how does OpenAI (or whoever) get the loop going in the first place?
With some use cases, like (say) writing a poem, the "seed" training data was in the initial web scrape; with shopping the seed training data came as a result of adding web search to chat and watching users click on links.
But there are more interesting products…
How do product managers triage tickets?
How do plumbers do their work?
You can get seed training data for those products in a couple ways but I think there's an assumption that what happens is that the AI companies need to trick people out of their data by being present in their file system or adding an AI agent to their SaaS software at work, then hiding something in the terms of service that says the data can be used to train future models.
I just don't feel like that assumption holds, at least not for the biggest companies.
Alternate access to seed training data method #1: just buy it.
I'll take one example which is multiplayer chat. OpenAI just launched group chat in ChatGPT:
We've also taught ChatGPT new social behaviors for group chats. It follows the flow of the conversation and decides when to respond and when to stay quiet based on the context of the group conversation.
Back in May I did a deep dive into multiplayer AI chat. It's really complicated. I outlined all the different parts of conversational turn taking theory that you need to account for to have a satisfying multiplayer conversation.
What I didn't say at the end of that post was that, if I was building it, the whole complicated breakdown that I provided is not what I would do.
Instead I would find a big corpus of group chats for seed data and just train the model against that.
And it wouldn't be perfect but it would be good enough to launch a product, and then you have actual live usage data coming in and you can iteratively train from there.
Where did that seed data come from for OpenAI? I don't know. There was that reddit deal last year, maybe it was part of the bundle.
So they can buy data.
Or they can make it.
Alternate access to seed training data #2: cosplay it.
Every so often you hear gossip about how seed training data can be manufactured… I remember seeing a tweet about this a few months ago and now there's a report:
AI agents are being trained on clones of SaaS products.
According to a new @theinformation report, Anthropic and OpenAI are building internal clones of popular SaaS apps so that they can train AI agents how to use them.
Internal researchers are giving the agents cloned, fake versions of products like Zendesk and Salesforce to teach the agents how to perform the tasks that white collar workers currently do.
The tweet I ran across was from a developer saying that cloning business apps for the purpose of being used in training was a sure-fire path to a quick acquisition, but that it felt maybe not ok.
My point is that AI companies don't need sneak onto computers to watch product managers triaging tickets in Linear. Instead, given the future value is evident, it's worth it to simply build a simulation of Linear, stuff it with synthetic data, then pay fake product managers to cosplay managing product inside fake Linear, and train off that.
Incidentally, the reason I keep saying seed training data is that the requirement for it is one-off. Once the product loop has started, the product creates it own. Which is why I don't believe that revenue from licensing social network data or scientific paper is real. There will be a different pay-per-access model in the future.
I'm interested in whether this model extends to physical AI.
Will they need lanyards around the necks of plumbers in order to observe plumbing and to train the humanoid robots of the future?
Or will it be more straightforward to scrape YouTube plumbing tutorials to get started, and then build a simulation of a house (physical or virtual, in Unreal Engine) and let the AI teach itself?
What I mean is that AI companies need access to seed training data, but where it comes from is product-dependent and there are many ways to skin a cat.
That's loop #1 - a LLM-mediated marketplace loop that (a) closes on transactions and (b) throws off usage data that improves market efficiency and reveals other products.
Per-product seed training data is a one-off investment for the AI company and can be found in many ways.
This loop produces cash.
Coding is the special loop that changes everything
Loop #2 starts with a specific product from loop #1.
A coding product isn't just a model which is good at understanding and writing code. It has to be wrapped in an agent for planning, and ultimately needs access to collaboration tools, AI PMs, AI user researchers, and all the rest.
I think it's pretty clear now that coding with an agent is vastly quicker than a human coding on their own. And not just quicker but, from my own experience, I can achieve goals that were previously beyond my grasp.
The loop closes when coding agents accelerate the engineers who are building the coding agents and also, as a side effect, working on the underlying general purpose large language model.
There's an interesting kind of paperclip maximisation problem here which is, if you're choosing where to put your resources, do you build paperclip machines or do you build the machines to build the paperclip machines?
Well it seems like all the big AI companies have made the same call right now which is to pile their efforts into accelerating coding, because doing that accelerates everything else.
So those are the two big loops.
Whoever gets those first will win, that's how I think about it.
I want to add two notes on this.
On training data feeding the marketplace loop:
Running the platform capitalism/marketplace loop is not the only way for a company to participate in the AI product economy.
Another way is to enable it.
Stripe is doing this. They're working hard to be the default transaction rails for AI agents.
Apple has done this for the last decade or so of the previous platform capitalism loop. iPhone is the place to reach people for all of Facebook, Google, Amazon, Uber and more.
When I said before that AI companies are trying to get closer to the point of intent, part of what I mean I that they are trying to figure out a way that a single hardware company like Apple can't insert itself into the loop and take its 30%.
Maybe, in the future, device interactions will be super commoditised. iPhone's power is that is bundles together an interaction surface, connectivity, compute, identity and payment, and we have one each. It's interesting to imagine what might break that scarcity.
On coding tools that improve coding tools:
How much do you believe in this accelerating, self-improving loop?
The big AI research labs all believe - or at least, if they don't believe, they believe that the risk of being wrong is worse.
But, if true, "tools that make better tools that allow grabbing bigger marketplaces" is an Industrial Revolution-like driver: technology went from the steam engine to the transistor in less than 200 years. Who knows what will happen this time around.
Because there's a third loop to be found, and that's when the models get so good that they can be used for novel R&D, and the AI labs (who have the cash and access to the cheapest compute) start commercialising wheels with weird new physics or whatever.
Or maybe it'll stall out. Hard to know where the top of the S-curve is.
Auto-detected kinda similar posts:
- Mapping the landscape of gen-AI product user experience (19 Jul 2024)
- The need for a strategic fact reserve (17 Jan 2025)
- Let me recruit AI teammates into Figma (26 Oct 2022)
- Who will build new search engines for new personal AI agents? (20 Mar 2024)
- An AI hardware fantasy, and an IQ erosion attack horror story (10 Nov 2023)