
Many readers will remember the two packs of Horror Top Trumps, which were first issued in 1978. What is not commonly known is that the first pack was recalled after 3 days only to be rereleased a month later minus one card: The Scarfolk card.
The card had proved so effective that, not only could it effortlessly beat every other card, it also killed the losing player within moments of the game ending.
Learning of the inexplicable power of the card, the government immediately issued the recall, albeit not in the interest of public safety. Instead, it coerced citizens on welfare into playing the game during home assessment visits. The government also targeted enemies of the state, using the card in so-called 'black operations' at home and abroad.
In 1979, a catastrophe was narrowly avoided when the Scarfolk card was played in a game opposite a forgery of itself. Fortunately, the game's location was sparsely populated and the only victims of the resulting dark-matter explosion were a government agent, an unknown dissenter, seven ducks and, less significantly, four coachloads of orphans* who were driven to the remote site for reasons unknown.
*The orphans were children of disgraced artists, academics and other intellectuals who disappeared during the New Truth Purges of September 1977**.
** Edit: Apparently, according to fresh information, no such purges took place.
Happy Halloween/Samhain from everyone at Scarfolk Council.
The Scarfolk Annual 197x.
OUT NOW(US/Can: 10.29.2019)
Available from :Amazon (http://bit.ly/scarfolkbook), Hive, Waterstones, The Guardian Bookshop, Foyles, Wordery, Blackwells, Forbidden Planet, Barnes & Noble, Books-A-Million & others.
For more information please reread.
Just a quick note for those who, like me, need to fiddle for a few hours while the world burns. Oh wait, that’s not quite what I meant, but anyway, if you want a distraction, here’s one: the Younger Dryas Impact Hypothesis.
The basic idea, as noted in the Wikipedia link above, is that around 12,800 years ago, a bolide either fragmented above the Earth in sort of a super-Tunguska, or an asteroid hit (possibly under the Hiawatha glacier in Greenland, near where the Cape York meteorite was found. And yes, possibly the Cape York fragments are part of it). I’m personally partial to an asteroid strike because one of the (to me) more solid lines of evidence is a spike in platinum around the world dating from around 12,800 BP, found most recently in Africa, but basically on every continent except Antarctica.
This hypothesis is controversial of course–it should be, given the way normal science works. But I think it does clear up some mysteries. For example, it may explain why the megafaunal extinction happened around then in America and norther Eurasia, and not thousands of years earlier.
Anatomically modern humans were around for at least 300,000 years, and we evidently tried agriculture around 22,000 years ago near what’s now the Dead Sea. While people like to hypothesize that ancient humans were more primitive than moderns, and that’s why they stayed few in number and simple in lifestyle, but I disagree. I personally think that the reason that humans didn’t take over the Earth hundreds of thousands of years ago was that the climate in the ice age fluctuated too radically to allow the rise of civilization. There’s little point in depending on crops if they fail most years.
Anyway, during those 300,000 years, humans lived alongside big animals (megafauna), except in the Americans (settled 10,000-20,000 years ago), in Australia (settled 65,000 years ago) and New Zealand and the Pacific (settled less than 3,000 years ago–we’ll ignore this for now). My personal hypothesis before I started thinking about the Younger Dryas Impact Hypothesis was that megafaunal extinctions were due to human predation and habitat change. While that’s unambiguously true in the Polynesian Islands and Madagascar (which I hate saying), it’s not clear what happened in Australia and the Americas. In Australia, the aboriginal population first settled around 65,000 years BP, but the megafaunal die off happened “rapidly thereafter”(per the biologists) starting around 46,000 years BP. This is a classic example of why biologists need to do more math. 19,000 years of coexistence is NOT rapid. Similarly in the Americas, humans lived alongside the megafauna for at least 2,000 years, if not 8,000 years, before the megafaunal extinction started “rapidly” happening. We don’t blame Europeans or Asians for wiping out their mammoths and other megafauna (do you ever hear the Chinese criticized for wiping out the elephants and rhinos around Beijing 3,000 years ago? That was considerably more rapid.). That’s why I agree with the Native Americans and Aboriginals who say that accusations of ancient ecocide are just veiled neo-colonial attempts to justify taking their land. They’re right: thousands of years of coexistence is not a short time.
And that leaves the Younger Dryas Impact. If it happened, it presumably did not play a role in the Australian megafaunal extinction (it’s around 33,000 years too late), but it could have played a major role in the megafaunal extinctions in the northern hemisphere, and possibly into South America. All that platinum had to come from somewhere.
One criticism leveled against the impact hypothesis is questioning why the proposed impact only killed big animals, not little ones. That’s easily answered, at least if you believe Anthony Martin, author of The Evolution Underground: Burrows, Bunkers, and the Marvelous Subterranean World Beneath our Feet (BigMuddy Link, in case you want to read this really fun book). He makes a point that during extinction events, mass or otherwise, animals that can shelter underground survive disproportionately well. So if a smallish asteroid struck, especially during northern winter, it would harm everything living above the surface (e.g. the megafauna) but animals hunkered down in burrows, especially under the snow, would be proportionally less affected. That’s not quite what we see, as things like bison and moose survived the possible impact, but it’s a reasonable hypothesis that can be tested.
Anyway, you can want to dive down the rabbit hole for shelter, you can waste happy hours on something other than obsessing about national meltdowns in the US or UK. That’s one reason I’m posting this.
The other reason to post is that I don’t know of much, well any, alt-history SF that explores worlds where the impact didn’t happen and the megafauna of the Americas and Eurasia didn’t go extinct 12,800 years ago. As an alt-history, the changes are rather subtle, more about setting than plot, in a No Younger Dryas (NYD) world. But they could be fun.
I’m pretty sure that agriculture and civilization would have arisen in NYD as they did in our timeline, although possibly 1,000 years or more earlier (the Younger Dryas lasted around 1,200 years). There are multiple reasons for this confidence:
- Agriculture arose in West Africa, Ethiopia, China, India, and possibly Southeast Asia in places where there were lots of megafauna (elephants, rhinos, lions, tigers, etc.), so having big herbivores around does not preclude people inventing agriculture.
- Someone tried agriculture back during the preceding ice age at least once that we know of, and that was with a full panoply of biggish critters around. They most likely failed due to climate change, not rampaging mammoths.
What would be different in a NYD world is that mammoths, rhinos, cave lions, sabertooths, and all that ilk would either be present in modern times or recently extinct in civilized lands. This would be particularly true in the Americas, if only because the classical Mediterranean civilizations, the Medieval Europeans, and the Chinese were all pretty darn good at getting rid of their megafauna. Colonizing the New World would have been a bit more like attempts to colonize Africa than what actually happened, with the Hudson’s Bay Company equivalent trading as much in mammoth or mastodon ivory as in beaver furs, and livestock kept at night in kraals of, perhaps, spiny osage orange branches or similar, to keep the lions away.*
Anyway, it’s something for creatives to play with, if they want to distract themselves from the current chaos. Heck, you could combine NYD with the Alt-Chinese colonizing (or attempting to colonize) the west coast of North America and introducing iron-working, first generation firearms, and a full complement of Old World diseases to the peoples of the Pacific Coast. That would make things much, much weirder, especially if the Europeans colonized the east coast of the Americas centuries later in timeline, so that both the diseases and the technologies had their chance to rampage around the continent.
Have fun!
*Actually, there’s a whole post I could write about beavers as ecological engineers and about how their loss from the US just prior to European settlement has given us a really distorted idea of how this continent is supposed to work. Maybe later.
If you looked at how many people check books out of libraries these days, you would see failure. Circulation, an obvious measure of success for an institution established to lend books to people, is down. But if you only looked at that figure, you'd miss the fascinating transformation public libraries have undergone in recent years. They've taken advantage of grants to become makerspaces, classrooms, research labs for kids, and trusted public spaces in every way possible. Much of the successful funding encouraged creative librarians to experiment and scale when successful, iterating and sharing their learnings with others. If we had focused our funding to increase just the number of books people were borrowing, we would have missed the opportunity to fund and witness these positive changes.
I serve on the boards of the MacArthur Foundation and the Knight Foundation, which have made grants that helped transform our libraries. I've also worked over the years with dozens of philanthropists and investors--those who put money into ventures that promise environmental and public health benefits in addition to financial returns. All of us have struggled to measure the effectiveness of grants and investments that seek to benefit the community, the environment, and so forth. My own research interest in the begun to analyse the ways in which people are currently measuring impact and perhaps find methods to better measure the impact of these investments.
As we see in the library example, simple metrics often aren't enough when it comes to quantifying success. They typically are easier to measure, and they're not unimportant. When it comes to health, for example, iron levels might be important, but anemia isn't the only metric we care about. Being healthy is about being nourished and thus resilient so that when something does happen, we recover quickly.
Iron levels may be a proxy for this, but they aren't the proxy. Being happy is even more complicated; it involves health but also more abstract things such as feelings of purpose, belonging to a community, security, and many other things. Similarly, while I believe rigor and best practices are important and support the innovation and thinking going into these metrics when it comes to all types of philanthropy, I think we risk oversimplifying problems and thus having the false sense of clarity that quantitative metrics tend to create.
One of the reasons philanthropists sometimes fail to measure what really matters is that the global political economy primarily seeks what is efficient and scalable. Unfortunately, efficiency and scalability are not the same as a healthy system. In fact, many things that grow quickly and without constraints are far from healthy--consider cancer. Because of our belief in markets, we tend to accept that an economy has to be growing for society to be healthy--but this notion is misguided, particularly when it comes to things we consider social goods. If we examine a complex system like the environment, for instance, we can see that healthy rainforests don't grow in overall size but rather are extremely resilient, always changing and adapting.
There is more to assessing a complex system than looking at its growth, efficiency, and the handful of other qualities that can be quantified and thus measured.
As biologists know, healthy ecosystems are robust and resilient. They can tolerate reductions in certain species populations ... until they can't. Scholars in ecology and biology have tried to model the robustness and resilience of systems in an effort to understand how to build and maintain such systems. Scientists have tried to apply these models to non-biological systems like the internet and ask questions, such as "How many and which nodes can you remove from the internet before it stops functioning?" These models are different from the mathematics economists use. Instead of relying on aggregate numbers and formulae, they use network models of nodes and links to ponder dynamics among connections in the system, rather than stocks and flows of economies.
Maybe there is something to learn from biologists and ecologists--the people who study the complex and messy real world of nature--when philanthropists are thinking about how to save the planet. We know from ecology and biology, for instance, that monocultures and simple approaches tend to be weak and fragile. The strongest systems are highly diverse and iterate quickly. When the immune system goes to war against a pathogen, the body engages in an arms race of mutations, deploying a diversity of approaches and constant iteration, communication, and coordination. Scientists also are learning that the microbiome, brain, and immune system are more integrated and complex than we ever imagined; they actually understand and tackle the more complex diseases currently beyond our scientific abilities. This research is pushing biology and computational models to a whole new and exciting level.
Many diseases, just like all of the systems that philanthropy tries to address, are complex networks of connected problems that go beyond any one specific pathway or molecule. Obesity is often described as simply a matter of managing one's calories and consequently cast as a lack of willpower on the part of an overweight individual.
But it is probably more accurately understood in the context of a global food system that is incentivized by financial markets to produce low cost, high-calorie, unhealthy, and addictive foods. Calorie counting as the primary way to lose weight has been a rule of thumb, but we are learning that healthy fats are fine while sugar calories cause insulin resistance, which often leads to diabetes and obesity. So solving the obesity problem is going to require much more than increasing or reducing any one single thing like calories.
It's our food system that is unhealthy, and one result is overweight individuals.
In such a complex world, what are we to do? We need respect for plurality and heterogeneity. It's not that we shouldn't measure things, but rather that we should measure different things, have different approaches and iterate and adapt. This is how nature builds resilient networks and systems. Because we as a society have an obsession with scale and other common measures of success, researchers and do-gooders have a natural tendency to want to use simple measures (as described in our blog post) and other "gold standards" to gauge the impact of the money spent and effort expended. I would urge us to instead support greater experimentation, smaller projects, more coordination and better communication. We should surely measure indicators of negative effects--blood tests to measure what may be going wrong (or right) with our bodies are very useful for instance.
We also need to consider that every change usually has multiple effects, some positive and others negative. We must constantly look for additional side effects and dynamically adapt whatever we do. Sticking with our obesity example, there is evidence that high fat, low sugar diets, generally known as ketogenic diets, are great for losing weight and preventing diabetes; the improvement can be assessed by measuring one's blood glucose levels. However, recent studies show that this diet might contribute to thyroid problems and if we adhere to one, we must monitor thyroid function and occasionally take breaks from it.
Coming up with hypotheses about causal relationships, testing them and connecting them to larger complex models of how we think the world works is an important step. In addition, asking whether we are asking the right questions and solving the right problems, rather than prematurely focusing on solutions, is key. Jed Emerson, who pioneered early attempts to monetize the economic value of social impact, makes the same point in his recent book The Purpose of Capital.
For the last 1,300 years, the Ise Shrine in Japan has been ritually rebuilt by craftspeople every 20 years. The lumber mostly comes from the shrine's forest managed in 200 year time scales as part of a national afforestation plan dating back centuries. The number of people working at Ise Shrine isn't growing, the shrine isn't trying to expand its business, and its workers are happy and healthy--the shrine is flourishing. Their primary concern is the resilience of the forest, rivers, and natural environment around the shrine. How would we measure their success and what can we learn from their flourishing as we try to manage our society and our planet?
It is heartening to see impact investors developing evidence-based methods to tackle the complex and critical challenges that face us. It's also heartening that capital markets and investors are supportive of investing, and in some cases even accepting reduced returns, in an effort to help tackle our big, complex challenges. We must, however, make changes in the way we fund potential solutions so that it supports a diversity of disciplines and approaches. That, in turn will require new methods of measurement and perhaps we can take advantage of some very old ones, such as the data from Shinto priests who have been measuring ice on a lake for resist oversimplification. If we don't, we risk wasting these funds or, even worse, amplifying existing problems and creating new ones.
I sometimes think of my computer as a very large house. I visit this house every day and know most of the rooms on the ground floor, but there are bedrooms I've never been in, closets I haven't opened, nooks and crannies that I've never explored. I feel compelled to learn more about my computer the same way anyone would feel compelled to see a room they had never visited in their own home.
GNU Readline is an unassuming little software library that I relied on for years without realizing that it was there. Tens of thousands of people probably use it every day without thinking about it. If you use the Bash shell, every time you auto-complete a filename, or move the cursor around within a single line of input text, or search through the history of your previous commands, you are using GNU Readline. When you do those same things while using the command-line interface to Postgres (psql), say, or the Ruby REPL (irb), you are again using GNU Readline. Lots of software depends on the GNU Readline library to implement functionality that users expect, but the functionality is so auxiliary and unobtrusive that I imagine few people stop to wonder where it comes from.
GNU Readline was originally created in the 1980s by the Free Software Foundation. Today, it is an important if invisible part of everyone's computing infrastructure, maintained by a single volunteer.
Feature RepleteThe GNU Readline library exists primarily to augment any command-line interface with a common set of keystrokes that allow you to move around within and edit a single line of input. If you press Ctrl-A at a Bash prompt, for example, that will jump your cursor to the very beginning of the line, while pressing Ctrl-E will jump it to the end. Another useful command is Ctrl-U, which will delete everything in the line before the cursor.
For an embarrassingly long time, I moved around on the command line by repeatedly tapping arrow keys. For some reason, I never imagined that there was a faster way to do it. Of course, no programmer familiar with a text editor like Vim or Emacs would deign to punch arrow keys for long, so something like Readline was bound to be created. Using Readline, you can do much more than just jump around—you can edit your single line of text as if you were using a text editor. There are commands to delete words, transpose words, upcase words, copy and paste characters, etc. In fact, most of Readline's keystrokes/shortcuts are based on Emacs. Readline is essentially Emacs for a single line of text. You can even record and replay macros.
I have never used Emacs, so I find it hard to remember what all the different Readline commands are. But one thing about Readline that is really neat is that you can switch to using a Vim-based mode instead. To do this for Bash, you can use the set builtin. The following will tell Readline to use Vim-style commands for the current shell:
$ set -o vi
With this option enabled, you can delete words using dw and so on. The equivalent to Ctrl-U in the Emacs mode would be d0.
I was excited to try this when I first learned about it, but I've found that it doesn't work so well for me. I'm happy that this concession to Vim users exists, and you might have more luck with it than me, particularly if you haven't already used Readline's default command keystrokes. My problem is that, by the time I heard about the Vim-based interface, I had already learned several Readline keystrokes. Even with the Vim option enabled, I keep using the default keystrokes by mistake. Also, without some sort of indicator, Vim's modal design is awkward here—it's very easy to forget which mode you're in. So I'm stuck at a local maximum using Vim as my text editor but Emacs-style Readline commands. I suspect a lot of other people are in the same position.
If you feel, not unreasonably, that both Vim and Emacs' keyboard command systems are bizarre and arcane, you can customize Readline's key bindings and make them whatever you like. This is not hard to do. Readline reads a ~/.inputrc file on startup that can be used to configure various options and key bindings. One thing I've done is reconfigured Ctrl-K. Normally it deletes from the cursor to the end of the line, but I rarely do that. So I've instead bound it so that pressing Ctrl-K deletes the whole line, regardless of where the cursor is. I've done that by adding the following to ~/.inputrc:
Control-k: kill-whole-line
Each Readline command (the documentation refers to them as functions) has a name that you can associate with a key sequence this way. If you edit ~/.inputrc in Vim, it turns out that Vim knows the filetype and will help you by highlighting valid function names but not invalid ones!
Another thing you can do with ~/.inputrc is create canned macros by mapping key sequences to input strings. The Readline manual gives one example that I think is especially useful. I often find myself wanting to save the output of a program to a file, which means that I often append something like > output.txt to Bash commands. To save some time, you could make this a Readline macro:
Control-o: "> output.txt"
Now, whenever you press Ctrl-O, you'll see that > output.txt gets added after your cursor on the command line. Neat!
But with macros you can do more than just create shortcuts for strings of text. The following entry in ~/.inputrc means that, every time I press Ctrl-J, any text I already have on the line is surrounded by $( and ). The macro moves to the beginning of the line with Ctrl-A, adds $(, then moves to the end of the line with Ctrl-E and adds ):
Control-j: "\C-a$(\C-e)"
This might be useful if you often need the output of one command to use for another, such as in:
$ cd $(brew --prefix)
The ~/.inputrc file also allows you to set different values for what the Readline manual calls variables. These enable or disable certain Readline behaviors. You can use these variables to change, for example, how Readline auto-completion works or how the Readline history search works. One variable I'd recommend turning on is the revert-all-at-newline variable, which by default is off. When the variable is off, if you pull a line from your command history using the reverse search feature, edit it, but then decide to search instead for another line, the edit you made is preserved in the history. I find this confusing because it leads to lines showing up in your Bash command history that you never actually ran. So add this to your ~/.inputrc:
set revert-all-at-newline on
When you set options or key bindings using ~/.inputrc, they apply wherever the Readline library is used. This includes Bash most obviously, but you'll also get the benefit of your changes in other programs like irb and psql too! A Readline macro that inserts SELECT * FROM could be useful if you often use command-line interfaces to relational databases.
Chet RameyGNU Readline is today maintained by Chet Ramey, a Senior Technology Architect at Case Western Reserve University. Ramey also maintains the Bash shell. Both projects were first authored by a Free Software Foundation employee named Brian Fox beginning in 1988. But Ramey has been the sole maintainer since around 1994.
Ramey told me via email that Readline, far from being an original idea, was created to implement functionality prescribed by the POSIX specification, which in the late 1980s had just been created. Many earlier shells, including the Korn shell and at least one version of the Unix System V shell, included line editing functionality. The 1988 version of the Korn shell (ksh88) provided both Emacs-style and Vi/Vim-style editing modes. As far as I can tell from the manual page, the Korn shell would decide which mode you wanted to use by looking at the VISUAL and EDITOR environment variables, which is pretty neat. The parts of POSIX that specified shell functionality were closely modeled on ksh88, so GNU Bash was going to have to implement a similarly flexible line-editing system to stay compliant. Hence Readline.
When Ramey first got involved in Bash development, Readline was a single source file in the Bash project directory. It was really just a part of Bash. Over time, the Readline file slowly moved toward becoming an independent project, though it was not until 1994 (with the 2.0 release of Readline) that Readline became a separate library entirely.
Readline is closely associated with Bash, and Ramey usually pairs Readline releases with Bash releases. But as I mentioned above, Readline is a library that can be used by any software implementing a command-line interface. And it's really easy to use. This is a simple example, but here's how you would you use Readline in your own C program. The string argument to the readline() function is the prompt that you want Readline to display to the user:
#include <stdio.h>
#include <stdlib.h>
#include "readline/readline.h"
int main(int argc, char** argv)
{
char* line = readline("my-rl-example> ");
printf("You entered: \"%s\"\n", line);
free(line);
return 0;
}
Your program hands off control to Readline, which is responsible for getting a line of input from the user (in such a way that allows the user to do all the fancy line-editing things). Once the user has actually submitted the line, Readline returns it to you. I was able to compile the above by linking against the Readline library, which I apparently have somewhere in my library search path, by invoking the following:
$ gcc main.c -lreadline
The Readline API is much more extensive than that single function of course, and anyone using it can tweak all sorts of things about the library's behavior. Library users can even add new functions that end users can configure via ~/.inputrc, meaning that Readline is very easy to extend. But, as far as I can tell, even Bash ultimately calls the simple readline() function to get input just as in the example above, though there is a lot of configuration beforehand. (See this line in the source for GNU Bash, which seems to be where Bash hands off responsibility for getting input to Readline.)
Ramey has now worked on Bash and Readline for well over a decade. He has never once been compensated for his work—he is and has always been a volunteer. Bash and Readline continue to be actively developed, though Ramey said that Readline changes much more slowly than Bash does. I asked Ramey what it was like being the sole maintainer of software that so many people use. He said that millions of people probably use Bash without realizing it (because every Apple device runs Bash), which makes him worry about how much disruption a breaking change might cause. But he's slowly gotten used to the idea of all those people out there. He said that he continues to work on Bash and Readline because at this point he is deeply invested and because he simply likes to make useful software available to the world.
You can find more information about Chet Ramey at his website.
If you enjoyed this post, more like it come out every four weeks! Follow @TwoBitHistory on Twitter or subscribe to the RSS feed to make sure you know when a new post is out.
Previously on TwoBitHistory…
Please enjoy my long overdue new post, in which I use the story of the BBC Micro and the Computer Literacy Project as a springboard to complain about Codecademy.https://t.co/PiWlKljDjK
— TwoBitHistory (@TwoBitHistory) March 31, 2019
A reply to the baseless accusations of Lee Holmes of Clones of Bruce Lee.
I've no wish to draw others into your attempt to create a spat, so I will not bother to cover all the issues raised by your brickbat on pages I do not run regardless of how obsessively you repost your rant on social media. Here no one else need be involved, unless they chose to involve themselves. So let's go through your preposterous claims. You write:
"I must say I am pretty annoyed at the reference to me in the book. The author seems to be obsessed with trying to put down other writers who have delved into this genre in some sort of attempt to make himself out as the more superior researcher."
Here's most of what I have to say about you: "Within Brucesploitation and the related Chansploitation phenomena, actors who copy and clone Bruce Lee or Jackie Chan make up one strand of these subgenres, but their importance can and has been over-stated. This is evident not just from the title of the book Here Come The Kung Fu Clones by Carl Jones, but also the UK fan site Clones of Bruce Lee run by Lee Holmes. Both Jones and Holmes treat Bruce Liang as a clone. My own view is that when Liang appears as Bruce Lee in The Dragon Lives Again (1977) he is there as an actor playing the Little Dragon in the underworld after death rather than a clone; this is emphasised by dialogue in the English dub addressing head on the fact that Liang doesn't look like Bruce Lee…. Movies such as The Black Dragon's Revenge (1975), with a narrative that revolves around a fictional investigation into the death of Bruce Lee, belong to the Brucesploitation genre without even featuring a clone so copyists are not essential to this film category. Lee Holmes on his Cloneswebsite at one time listed Black Dragon's Revenge supporting actor Charles Bonet as a Bruce Lee clone, but given this martial artist's karate leanings and rejection of kung fu, this is not a claim I take at all seriously. I would further argue that those who see figures like Bonet as clones do so because they approach Brucesploitation in thrall to the misleading idea that copyists define it. Tadashi Yamashita, sometimes called Bronson Lee after a character he played, is another example of a karateka I do not accept as a Bruce Lee clone; despite Jones and Holmes - among others - mistakenly asserting he is one."
Seeing this any intelligent reader will immediately realise that your claim that I want to pose as "the more superior researcher" is based on a basic category error. The passage above is focused more on interpretation than research and I certainly wouldn't damn myself with feint praise by claiming to be a superior theorist to you because you are not a theorist at all. Likewise your clumsy attempt at commentary on something you failed to fully understand might be cited as evidence that I am a superior writer to you; sadly your prose as quoted in the present paragraph is so clunky that this hardly requires pointing out. While I may be putting you down now for a ridiculously over-sensitive and stupid response to Re-Enter The Dragon, this was not what I was doing in the book when I laid out the differences between my positions on Brucesploitation as a genre and dominant discourse on it to date, of which your website simply provides an example. If you don't want your views of Brucesploitation to be met with anything other than agreement then you'd be best advised not to air them in public, or indeed private.
You write: "…who doesn't think that Fist of Unicorn should be categorised as Bruceploitation? This not some big revelation."
Newsflash for Lee Holmes, billions of people in the world have never heard of Fist of Unicorn or Brucesploitation, and it is therefore extremely unlikely they think a film of which they are unaware should be categorised as part of a genre they aren't familiar with. However if you look at what I say in regard to this in context then it is also obvious that I'm not claiming this as some 'big revelation' but rather deploying it as part of a broader argument: "I have seen it falsely asserted in a number of places - including Wikipedia - that Brucesploitation movies attempted to exploit interest in Bruce Lee after his death. Fist of Unicorn (1973) can and should be treated as part of the genre, and it was made and released before Lee died on 20 July 1973…" In case you want to check the Wikipedia entry, although it appears you don't bother to fact check anything very much (see below), there is an archived version of the page here: https://web.archive.org/web/20181102091239/https://en.wikipedia.org/wiki/Bruceploitation
Incidentally if you think Fist of Unicorn is Brucesploitation then you implicitly support my argument that the genre predates the Little Dragon's death, and Wikipedia - among others - was wrong to claim it is made up of movies shot after 20 July 1973. Note that this Wikipedia entry opens with various errors I am attempting to correct in Re-Enter The Dragon: "Bruceploitation (a portmanteau of Bruce Lee and exploitation) refers to the practice on the part of filmmakers in mainland China, Hong Kong, and Taiwan of hiring Bruce Lee look-alike actors ("Lee-alikes") to star in many imitation martial arts films in order to cash in on Lee's success after his death." Alongside the dating error in this opening sentence, there are the misleading assertions that Brucesploitation is characterised by look-alike actors (or clones to use the term found in the title of your website) and about the geographical areas that produced such films (which, of course, also include The Philippines, Korea, Indonesia, Japan and the USA). The claim that Brucesploitation movies are 'imitation martial arts films' is particularly silly; in my experience most of those interested in the genre currently consider them to be actual martial arts films rather than imitation fight flicks. That said, such a slippage does serve to illustrate the damage the clone fallacy does to a proper understanding of the genre.
Wikipedia entries are highly ranked by search engines and are influential, therefore misconceptions within them and the sources they draw upon and link to - including in the instance of the one on 'Bruceploitation' your website - need to be challenged, which is what I've been doing. I would also point out that this Wikipedia entry has for some time contained a link to a review of the Carl Jones book Here Come The Kung Fu Clones that I wrote and published in 2012, and that my understanding of Brucesploitation has changed since then; although I would stand by the review's premise that Jones in his book was confused about the Bruce Le filmography - this is reiterated in less detail in Re-Enter The Dragon.
You say: "I also don't think anyone has ever said that Bruce Lee A Dragon Story is the first Bruceploitation movie, it is the first Bruce Lee Bio-pic."
The top two entries of the web search I just did for Bruce Lee: A Dragon Story (1974), both addressed the matter of it being the 'first' Brucesploitation movie. I got live links for Wikipedia and Hong Kong Movie Database but I'm providing archived ones here:
"Bruce Lee: A Dragon Story… is a 1974 Bruceploitation film starring Bruce Li…. The film is notable for being the first biopic of Bruce Lee (it was released the year following his death), the debut film of notorious Lee imitator Bruce Li, and the first film in the Bruceploitation genre."https://web.archive.org/web/20190626211837/https://en.wikipedia.org/wiki/Bruce_Lee:_A_Dragon_Story
"Bruce Lee: A Dragon Story is thought to be the first entry in the extraordinary genre of what are known as "Brucesploitation" films." https://web.archive.org/web/20120710022900/http://hkmdb.com/db/movies/reviews.mhtml?id=9646&display_set=eng
You say: "…how do you know my opinions on Bruce Leung Siu-Lung or Tadashi Yamashita and how they fit into Bruceploitation? I've never published a profile on them on my site. If you wanted my opinion on them, here is a radical idea, you could have just asked me!"
I assume it is narcissism that makes you think I'd be interested in your opinions. To clarify, I couldn't give a flying fuck about your opinions on Bruce Liang (AKA Bruce Leung Siu-Lung), Tadashi Yamashita, or anything else for that matter. My book dealt with Brucesploitation as a genre and that meant I needed to address the discourse(s) that create and shape it, and unfortunately your website is a part of this and is publicly accessible. On your site you have a page dedicated to 'lesser known stars of Bruceploitation', where you mention three major clones and go on to provide a list of others who were 'impersonating The Little Dragon'. You include both Bruce Liang (AKA Bruce Leung Siu-Lung) and Tadashi Yamashita on this list and therefore effectively treat them as clones. It would have been completely redundant to ask you about this because you'd already implicitly stated your position online. In case you've forgotten what's on your own website here's an archived version of the page: https://web.archive.org/web/20190819111923/http://clonesofbrucelee.info/enter-another-dragon/
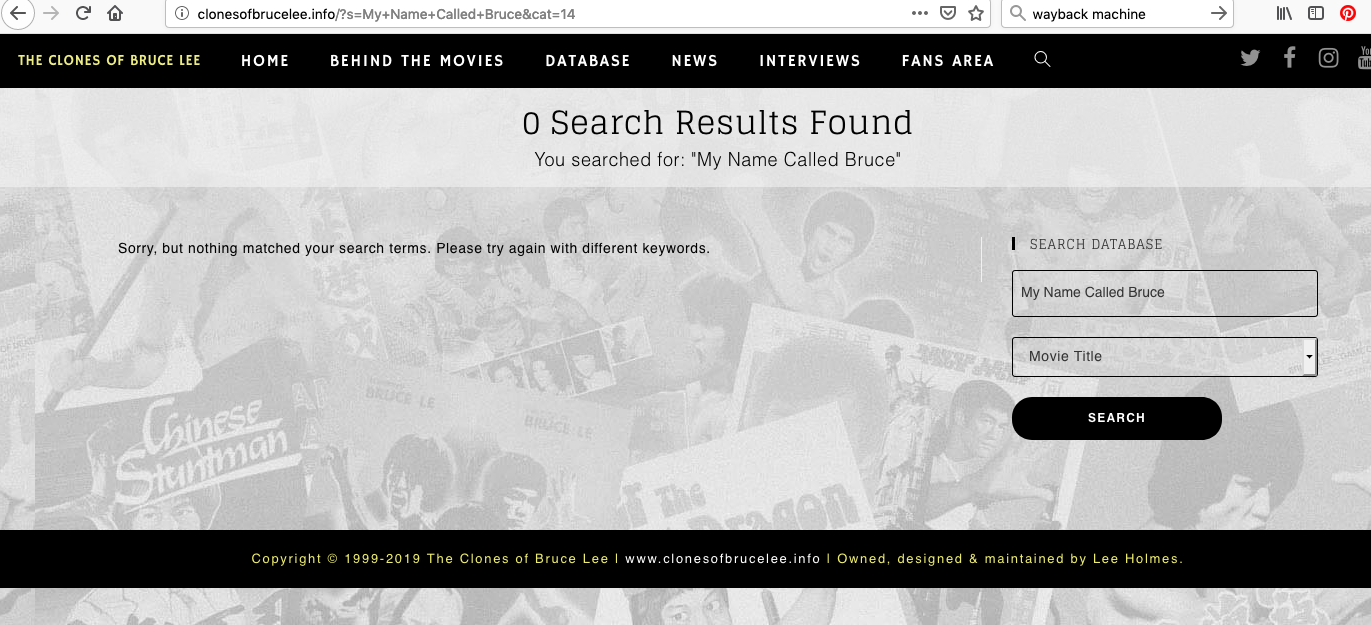
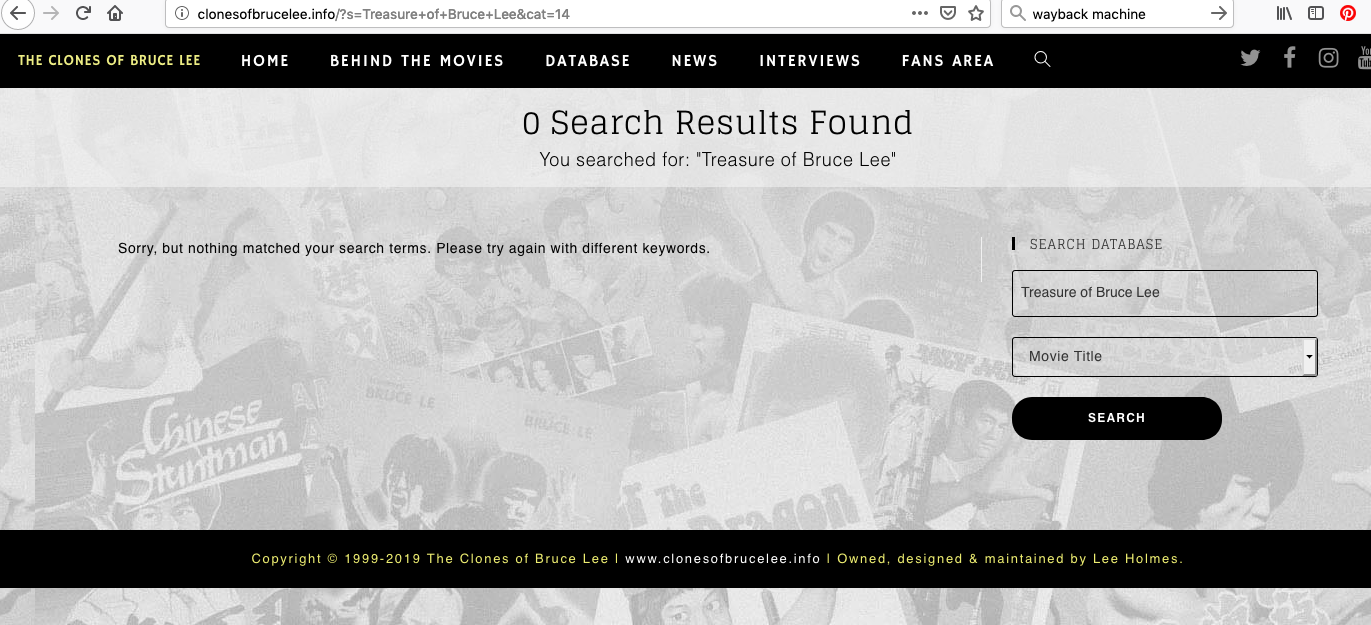
You say: "And why would anyone classify Mission Terminate as a Bruceploitation movie? It is only included on my site due to the fact that it features Bruce Le and I cover his entire filmography."
If you cover Bruce Le's entire filmography why am I unable to find coverage of it all on your site? For example I can find nothing about Treasure of Bruce Lee or My Name Called Bruce.When I use the search engine on your site for these films it produces no results, see screenshots below. It's claims like this, which I'm unable to substantiate, that lead me to suspect you may be a habitual liar. Since I've never been able to find coverage of ALL Bruce Le's films on your site, your sorry justification isn't exactly convincing. There's nothing on the page containing the Richard Norton interview to suggest you see Mission Terminate as anything other than Brucesploitation. That page is archived here: https://web.archive.org/web/20190819112551/http://clonesofbrucelee.info/richard-norton/
Your homepage explicitly states: "This website is dedicated to Bruce Lee exploitation cinema, or 'Bruceploitation' as it has become to be known." This is at the top of the page in capital letters and it is therefore reasonable for anyone visiting the site to conclude that anything on it - such as the coverage of Mission Terminate - you consider to be Brucesploitation, unless you explicitly state otherwise. BTW: your sentence construction is shockingly bad and you really ought to rewrite the dreadful 'as it has become to be known' since this sloppy phrasing is very visible on the page. In case you've forgotten what's on your homepage there's an archived version of it here: https://web.archive.org/web/20190209093714/http://clonesofbrucelee.info/
You write: "I applaud anyone who goes to the effort to bring out a book on this genre that I love I just don't see why you think you had to include my name, and other writers (e.g. Carl Jones) in such a negative way to try make yourself and your book look better. As a fan and researcher of this genre for more than 30 years I wouldn't see the need to try and put down you in anything I write. My research into the genre consists of more than merely watching what i can find online or purchased from the poundshop and writing a basic plot line and sticking it in a book."
This self-refuting passage really made me laugh. You are attempting to put me down in your brickbat, and it is something you've written, so why pointlessly contradict yourself within it by rhetorically stating: "I wouldn't see the need to try and put down you in anything I write…" You appear incapable of making or sustaining a coherent argument or writing a well-constructed sentence. Likewise some of the absurd errors on your part addressed here rather belie your claims to have been researching 'this genre for more than 30 years'. It would appear that what you call 'research' consists mostly of spouting the first piece bullshit that enters your head and deluding yourself into thinking no one will notice you're utterly clueless. Likewise your claim that me 'putting you down' will make me or my book 'look better' is ridiculous, since you're a complete twit who is utterly incapable of making me or anyone else 'look better' by comparison. I also hope it's clear by now I wasn't putting you down in my book even if I am now. I'm doing that here to demonstrate the difference between civil critical engagement with your website - which is my stance towards it in Re-Enter The Dragon - and personalised refutation with humorous insults, which as I trust this reply illustrates is a style of address that I am also familiar with and that I can deploy as and when is necessary. It would be great if this eventually helped you to understand the difference between the two, although at present that seems rather unlikely.
You say: "And one final thought, I've never seen Bruceploitation spelt "Brucesploitation". I've no idea where you got that idea from."
No shit Sherlock! I discuss the variant spellings of Brucesploitation in Re-Enter The Dragon and if as you claim you've been researching the genre for 30 years then you really ought to have seen the spelling I use elsewhere. Either you're lying or you haven't done any serious research, or both. I'm going to give you one example of the Brucesploitation spelling being used here but you can find many more by doing a simple web search, assuming - of course - you're not too simple to use a search engine: https://www.grindhousedatabase.com/index.php/Brucesploitation
Views: 36
Rumors are circulating widely — and some news sources claim to have seen actual drafts — of a possible Trump administration executive order aimed at giving the government control over content at large social media and other major Internet platforms.
This effort is based on one of the biggest lies of our age — the continuing claims mostly from the conservative right (but also from some elements of the liberal left) that these firms are using politically biased decisions to determine which content is inappropriate for their platforms. That lie is largely based on the false premise that it’s impossible for employees of these firms to separate their personal political beliefs from content management decisions.
In fact, there is no evidence of political bias in these decisions at these firms. It is completely appropriate for these firms to remove hate speech and related attacks from their platforms — most of which does come from the right (though not exclusively so). Nazis, KKK, and a whole array of racist, antisemitic, anti-Muslim, misogynistic, and other violent hate groups are disproportionately creatures of the political right wing.
So it is understandable that hate speech and related content takedowns would largely affect the right — because they’re the primary source of these postings and associated materials.
At the scales that these firms operate, no decision-making ecosystem can be 100% accurate, and so errors will occur. But that does not change the underlying reality that the “political bias” arguments are false.
The rumored draft Trump executive order would apparently give the FCC and FTC powers to determine if these firms were engaging in “inappropriate censorship” — the primary implied threat appears to be future changes to Section 230 of the Communications Decency Act, which broadly protects these (and other) firms and individuals from liability for materials that other parties post to their sites. In fact, 230 is effectively what makes social media possible in the first place, since without it the liability risks of allowing users to post anything publicly would almost certainly be overwhelming.
But wait, it gets worse!
At the same time that these political forces are making the false claims that content is taken down inappropriately from these sites for political purposes, governments and politicians are also demanding — especially in the wake of recent mass shootings — that these firms immediately take down an array of violent postings and similar content. The reality that (for example) such materials may be posted only minutes before shootings occur, and may be widely re-uploaded by other users in an array of formats after the fact, doesn’t faze the politicians and others making these demands, who apparently either don’t understand the enormous scale on which these firms operate, or simply don’t care about such truths when they get in the way of politicians’ political pandering.
The upshot of all this is an insane situation — demands that offending material be taken down almost instantly, but also demands that no material be taken down inappropriately. Even with the best of AI algorithms and a vast human monitoring workforce, these dual demands are in fundamental conflict. Individually, neither are practical. Taken together, they are utterly impossible.
Of course, we know what’s actually going on. Many politicians on both the right and left are desperate to micromanage the Net, to control it for their own political and personal purposes. For them, it’s not actually about protecting users, it’s mostly about protecting themselves.
Here in the U.S., the First Amendment guarantees that any efforts like Trump’s will trigger an orgy of court battles. For Trump himself, this probably doesn’t matter too much — he likely doesn’t really care how these battles turn out, so long as he’s managed to score points with his base along the way.
But the broader risks of such strategies attacking the Internet are enormously dangerous, and Republicans who might smile today about such efforts would do well to imagine similar powers in the hands of a future Democratic administration.
Such governmental powers over Internet content are far too dangerous to be permitted to any administration of any party. They are anathema to the very principles that make the Internet great, and they must not be permitted to take root under any circumstances.
–Lauren–
Ethan Zuckerman thoughtful and appropriately points out that one big missing question in my recent Wired piece on measuring philanthropic impact is whether some of this positive societal change should be in the hands of government instead of philanthropists. He correctly points out that since the Reagan/Thatcher era of the 80s, we've started shrinking the role of government and have started to see big philanthropists and the private sector being called on to do what government used to do. In a post from 2013, Ethan wonders why he doesn't have rail solution to his commuting problem from Western Massachusetts. He suggests that without government, things like railway system are difficult to fund - the market isn't the best solution for many social goods.
I think the idea about whether we should be doubling down on philanthropy or fixing government and increasing government resources is a great question and probably the right one. I think the idea of fixing the government and turning the corner on the privatization is a daunting idea, but something we need to discuss.
Views: 16
Another day, another massive data breach. This time some 100 million people in the U.S., and more millions in Canada. Reportedly the criminal hacker gained access to data stored on Amazon’s AWS systems. The fault was apparently not with AWS, but with a misconfigured firewall associated with a Capital One app, the bank whose customers were the victims of this attack.
Firewalls can be notoriously and fiendishly difficult to configure correctly, and often present a target-rich environment for successful attacks. The thing is, firewall vulnerabilities are not headline news — they’re an old story, and better solutions to providing network security already exist.
In particular, Google’s “BeyondCorp” approach (https://cloud.google.com/beyondcorp) is something that every enterprise involved in computing should make itself familiar with. Right now!
BeyondCorp techniques are how Google protects its own internal networks and systems from attack, with enormous success. In a nutshell, BeyondCorp is a set of practices that effectively puts “zero trust” in the networks themselves, moving access control and other authentication elements to individual devices and users. This eliminates the need for traditional firewalls (and in most instances, VPNs) because there is no longer a conventional firewall which, once breached, gives an attacker access to all the goodies.
If Capital One had been following BeyondCorp principles, there would be 100+ million less of their customers who wouldn’t be in a panic today.
–Lauren–
I decided to write my column this month in Wired about impact investing and the opportunity to bring new perspectives to the space. As I wrote the piece and started to negotiate with my truly great editor at Wired, I got feedback that it was a bit dense, jargony and wonky. My colleague Louis Kang was doing a lot of research for the article, so I decided to move the nitty-gritty details from the Wired piece to this co-authored "explainer" essay. This essay, now a companion piece to the Wired column, is an overview of what impact investing is, describing some different ways that we currently measure impact and some of the concerns we have with these measurement methods. The Wired article discusses my observations of this field and provides some suggestions on how we might better measure impact.
- Joi
Impact Investment Metrics and Their Limitations
By Joi Ito and Louis Kang
As the pile of philanthropic money aimed at solving the world's problems grows, the desire for assessment and rigor has pushed experts to develop metrics to measure impact and success.
But our world's biggest problems -- climate change, poverty, global health, social instability -- don't easily lend themselves to measurement. Climate change, poverty, global health and social instability, for instance, are complex self-adaptive systems that are irreducible to simple metrics and mathematics. In fact, it's simple math and the hyper-efficient optimizations of the financial markets that have caused most of these problems in the first place. Consider for example, capital markets that focus much more on shareholders than other stakeholders, which has caused extraction and exploitation of natural resources; the efficient production of cheap calories that has contributed to obesity; mass consumption that has led to climate change; and Internet and social media platforms that have amplified hate speech and new forms of adversarial attacks. Are modern foundations and financial institutions armed with quants and global development principles, such as the UN's Sustainable Development Goals, enough to tackle such complex challenges? I don't think so.
Philanthropy as a concept has existed for centuries.The U.S. Internal Revenue Service began providing tax benefits for charitable gifts in the early 1900s, and since then, philanthropy has continued to grow and become more sophisticated.
At the MacArthur Foundation, where I serve on the Board of Directors, "impact investing" emerged in the early 1980s as a way to channel capital to communities plagued by underinvestment and spur the growth of revenue-generating nonprofits and social-purpose businesses. Around this time, Nobel Peace Prize winner Muhammad Yunus founded the Grameen Bank on the principle that loans are more effective than charity to disrupt poverty, and it started by offering tiny loans to impoverished entrepreneurs, which we now know as microfinance. Since then, new types of investment capital and assets, as well as financing and organizational structures and impact measurement practices, have emerged to better engage in the active creation of positive impact. Although the purpose and practice of impact investing are continuously revisited and refined, the core idea is to unlock more traditional investment capital to contribute to solving the world's problems. Today, more than 1,340 organizations manage roughly $500 billion in impact investing assets worldwide.
Many companies now proactively claim to be public benefit companies or are undergoing certification by B-Lab to qualify as B-Corps. These include Patagonia and a company that I invested in, Kickstarter. These companies claim to use, and sometimes disclose, auditable measures of their non-financial societal impact. In addition to companies like these, there is a push among more mainstream businesses to go beyond mere measures of financial success and assess their societal or environmental impacts with a "triple bottom line." Although impact investing has largely been seen as a philanthropic activity, which by definition is prone to accepting little or no return on investment, many traditional impact funds and investors now assert that they are designing investment practices to achieve market level returns on investments and meet positive impact targets. According to one Global Impact Investing Network (GIIN) report, 49 such funds have, on average, achieved an 18.9 percent return on equity-based impact investments in emerging markets. Recently, we've seen more established institutional investors, such as Goldman Sachs, KKR and Bain Capital, to name a just a few now active in the impact investing scene.
Texas Pacific Group (TPG) has created an impact investment fund called the Rise Fund with the help of The Bridgespan Group. The Rise Fund has devised a method that attempts to calculate the economic value of impact called the Impact Multiple of Money, or IMM. IMM is one of a growing number of models and protocols, each of which comes with pros and cons, used to assess non-financial impact. The Rise/Bridgespan method generates an economic estimate of the social impact of an investment by first estimating the number of people impacted by it using relevant scientific studies and multiplying that number by the U.S. "value of life" of $5.4 million, as calculated by the U.S. Department of Transportation to quantify "the additional cost that individuals would be willing to bear for improvements in safety (that is, reductions in risks)." This dollar value of the investment's impact is then adjusted by multiplying it by something called the "probability of impact realization," which is an estimated probability of achieving the expected impact calculated based on a review of relevant scientific studies. Using this number, Rise then projects the investment's Net Present Value, or NPV, using an estimated annual discount set by itself. Finally, the NPV is multiplied by the percent of the company's overall equity owned by Rise to figure out how much of the impact Rise is accountable for, which is then divided by the investment amount to determine the IMM (see this HBR case about an alcoholism program that is part of the Rise Fund as an example). For example, if Rise invested $10 million for 50 percent of the equity in a venture, when the NPV is $100 million, Rise determines $50M ($100 million multiplied by 50 percent) is the value of the impact for which it can claim credit. So its IMM would be five times its investment, or $50 million divided by $10 million, the amount it spent to make the investment. In this example, the IMM was five times its investment, exceeding the three times minimum IMM for the Rise Fund.
Robin Hood, which claims to be New York's largest poverty-fighting organization, takes a similar approach to the IMM. It uses a Benefit-Cost Ratio (BCR) to "assign a dollar figure to the amount of philanthropic good that a grant does" and focuses solely on improving the Quality-Adjusted Life Year (QALY). Robin Hood's metrics are demonstrated over 163 different cases, which can be found here. For example, the BCR of Robin Hood's support for a substance abuse treatment program was calculated by first counting the number of individuals who received the treatment as reported by their grantee. Robin Hood staff then estimated three factors: what percent of these individuals received the treatment solely because of their support; how much the QALY was reduced due to substance abuse, and how much the QALY was improved due to intervention. Suppose the treatment program reached 1,000 people, and Robin Hood estimates that it is only accountable for 10 percent of them. Of those 100 people, QALY reduction due to substance abuse is 10 percent and QALY improvement due to intervention is 20 percent. Robin Hood multiplies 100 by 10 percent, then by 20 percent and finally $50,000 (the QALY value as determined by its staff) to argue that the BCR of the program is approximately $100,000.
Not all of the new approaches attempt to measure impact using a dollar value. My college classmate and collaborator on many projects, Pierre Omidyar, has been an influential leader in impact investing through the work of his organization, the Omidyar Network (ON). The ON funds companies and intermediaries that also provide some social benefit. Over the years, the ON has developed and articulated a variety of methodologies to describe how it measures and categorizes opportunities and risks in funding socially beneficial companies. It has also recently experimented with Acumen's "lean data" approach which seeks to allow rapid iteration in social enterprises in the same way start-ups iterate. Acumen has developed software tools to survey beneficiaries of impact investments and calculate an average Net Promoter Score (NPS), which reflects a combination of many factors. NPS is a method originally developed to measure customer satisfaction in marketing. Via Acument's platform, the ON surveyed 36 investees and 11,500+ customers the investees reached across 18 countries, meaning it received an NPS score of 42 (For comparison, Apple's NPS is 72). And with its surveying capability, the ON contends that its investments improved the quality of life of about 74 percent of its customers.
Having reviewed various impact measurement techniques that are practiced today, now ask yourself: IMMs, BCRs, and NPSs -- do these numbers truly reflect what impact means? Understanding impact through measurement has importance, but we must be careful not to oversimplify complex systems into reducible metrics and lose sight of the intricate dynamics of the world. "Of course, many of us who want to see impact investing attain real scale would welcome the simplicity of an 'Impact Earnings Per Share' calculation or other simplified way to compare relative impact of competing investment opportunities -- but being able to advance a simple metric and having a metric framework that actually helps us assess our true impact and value contribution are two different things," Jed Emerson, who invented the framework Social Return on Investment (SROI), recently told me. "As we know from the history of economics and finance, a single metric can't reflect more nuanced aspects of value or impact. Simplified metrics tell us how we are thinking today but not what we truly seek to know."
Impact measurement is still a nascent field. Understanding impact is fragmented, sometimes misguided, and often inadequate. This makes evaluating and generating impact highly inefficient. We need more clarity and transparency, as well as robust scholarship to study and maximize the impact of philanthropy and impact investing. To address this, I've started to discuss and develop new methods to measure impact. My early thoughts and suggestions are introduced in this upcoming Wired article.
I would like to suggest a new word.
Anthropocosmos, n. and adj. Chiefly with "the." The epoch during which human activity is considered to be a significant influence on the balance, beauty, and ecology of the entire universe.
Based on ...
Anthropocene, n. and adj. Chiefly with "the." The era of geological time during which human activity is considered to be the dominant influence on the environment, climate, and ecology of the earth. --The Oxford English Dictionary
As we become painfully aware of the extent to which human activity is influencing the planet and its environment, we are also accelerating into the epoch of space exploration. Not only will our influence substantially affect the future of this blue dot we call Earth, but also our never-ending desire to explore and expand our frontiers is extending humanity's influence on the cosmos. I think of it as the Anthropocosmos, a term that captures the idea of how we must responsibly consider our role in the universe in the same way that Anthropocene expresses our responsibility for this world.
The struggle to protect the commons--the public spaces and resources we all depend on, like the oceans or Central Park--is not a new problem. Shepherds grazing sheep on shared land without consideration for other flocks will soon find grass growing thin. We already know that farming and the timber industry deplete the forests, and the destruction of that commons in turn affects the commons that is the air we breathe. These are versions of the same problem--the tragedy of the commons. It suggests that, left unchecked, self-interest can deplete resources that support the common good.
Joi Ito is an Ideas contributor for WIRED, and his association with the magazine goes back to its inception. He is coauthor with Jeff Howe of Whiplash: How to Survive Our Faster Future and director of the MIT Media Lab.
The early days of the internet were an amazing example of people and organizations from a variety of sectors coming together to create a global commons that was self-governed and well-managed by those who built it. Similarly, we're now in an internet-like moment in which we can imagine an explosion of innovation in space, our ultimate commons, as nongovernment groups, companies, and individuals begin to drive progress there. We can learn from the internet--its successes and failures--to create a generative and well-managed ecosystem in space as we grow into our responsibility as stewards of the Anthropocosmos.
Like the internet, space exploration has been mostly a government-vs.-government race and a government-with-government collaboration. The internet started out as Arpanet, which was funded by the Department of Defense's Advanced Research Projects Agency and operated by the military until 1990. A great deal of anxiety and deliberation went into the decision to allow commercial and nonresearch uses of the network, much as NASA extensively deliberated over opening the doors to "public-private partnership" leading up to the Commercial Crew Program launch in 2010. This year is the 50th anniversary of the Apollo 11 mission that put men on the moon, a multibillion-dollar effort funded by US taxpayers. Today, the private space industry is robust, and private firms compete to deliver payloads, and soon, put people into orbit and on the moon.
The state of the development of the space industry reminds me of where the internet was in the early '90s. The cost of putting a satellite into orbit has gone from supercomputer-level costs and design cycles to just a few thousand dollars, similar to the cost of a fully loaded personal computer. In many ways, SpaceX, Blue Origin, and Rocket Lab are like UUNET and PSINet1 --the first commercial internet service providers--doing more efficiently what government-funded research networks did in the past.
1 Disclosure: I was at one point an employee of PSINet and the CEO of PSINet Japan.
When these private, for-profit ISPs took over the process of building out the internet into a global network, we saw an explosion of innovation--and a dot-com bubble, followed by a crash, and then another surge following the crash. When we were connecting everyone to the internet, we couldn't imagine all the possible things--good and bad--that it would bring. In the same way, space development will most likely expand far beyond the obvious--mining, human settlements, basic research--to many other ideas. The question now is, how can we direct the self-interested businesses that will undoubtedly power entrepreneurial expansion, growth, and innovation in space toward the shared, long term health of the space commons?
In the early days of the internet, everyone pitched in like people tending a community garden. We were a band of jolly pirates on a newly discovered island paradise far away from the messiness of the real world. In "A Declaration of the Independence of Cyberspace," John Perry Barlow even declared cyberspace a new place, saying "We are forming our own social contract. This governance will arise according to the conditions of our world, not yours." His utopian idea, which I shared at the time, is now echoed by some of today's spacebound entrepreneurs who dream of settling Mars or deploying terraforming pods on planets across the galaxy.
While it wasn't obvious how life on the internet would play out when we were building the early infrastructure, back then academics, businesses, and virtually anyone else who was interested worked on its standards and resource allocation. We created governance mechanisms in communities like ICANN for coordination and dispute resolution, run by people dedicated to the protection and flourishing of the internet commons. In short, we built the foundations on which everyone could develop businesses and communities. At least in the beginning, the internet effectively harnessed the self-interest of commercial players and money from the markets to develop open protocols, free for everyone to use, that the communities designed. In the early 1990s, the internet was one of the best examples of a well-managed commons, with no one controlling it and everyone benefiting from it.
A quarter-century on, cyberspace hasn't evolved into the independent, self-organized utopia that Barlow envisioned. As the internet "democratized," new users and entrepreneurs who weren't involved in the genesis of the internet joined. It was overrun by people who didn't think of themselves as pirate gardeners tending the sacred network that supported this idealistic cyberspace--our newly created commons. They were more interested in products and services created by companies, and these companies often didn't care as much about ideals as in making returns for their investors. On the early internet, for example, people ran their own web servers, and fees for connectivity were always flat--sometimes simply free--and almost all content was shared. Today, we have near-monopolies, walled garden services; the mobile internet is metered and expensive; and copyright is vigorously enforced. From the perspective of this internet pioneer and others, cyberspace has become a much less hospitable place for users as well as developers, a tragedy of the commons.
Such disregard for the commons, if allowed to continue into planetary orbit and beyond, could have tangibly negative consequences. The decisions we make in the sociopolitical, economic, and architectural foundations of Earth's near-space cocoon will directly impact daily life on the surface--from debris falling in populated areas to advertisements that could block our view of the skies. A piece of space junk has already hit a woman in Oklahoma and an out-of-control Chinese space station caused a lot of anxiety and luckily fell harmlessly into the Pacific Ocean.
So I think the rules and governance models for space are extremely important to understand to mitigate known problems such as space debris, set precedents for the unknown, and managing the race to lunar settlements. We already have the Outer Space Treaty, which governs our efforts and protects our resources in space as a shared commons. The International Space Station is a great example of a coordinated effort by many competing interests to develop standards and work together on a common project that benefits all participants.
However, recent announcements by Vice President Mike Pence of an "America First" agenda for the moon and space fail to acknowledge the fact that the US pursues space exploration and science with deep coordination and interdependence with other countries. As new opportunities are emerging for humans to develop economic activities and communities in orbit around the Earth, on asteroids, and beyond, nationalistic actions by the Trump administration could undermine the opportunity to pursue a multiple stakeholder, internationally coordinated approach to designing future human space activities and ensure that space benefits all humankind.
As space becomes more commercial and pedestrian like the internet, we must not allow the cosmos to become a commercial and government free-for-all with disregard for the commons and shared values. In a recent Wall Street Journal article, Media Lab PhD student and director of the Media Lab Space Exploration Initiative2 Ariel Ekblaw suggested we need a new generation of "space planners" and "space architects" to coordinate such expansive growth while enabling open innovation. Through such communities, we can build the space equivalents of ICANN and the Internet Engineering Task Force, in coordination with international policy and governance guidance from the UN Office for Outer Space Affairs.
Disclosure : I am one of the two principal investigators on this initiative.
I am hopeful that Ariel and a new generation of space architects can learn from our successes and failures in protecting the internet commons and build a better paradigm for space, one that will robustly self-regulate and allow growth and generative creativity while developing strong norms that help us with our environmental and societal issues here on Earth. Already there are positive signs: SpaceX recently decided to fly low to limit space debris.
Fifty years ago, America "won" the moonshot. Today, we must "win" the Earthshot. The internet connected our world like never before, and as the iconic 1968 Earthrise photo shows, space helps us see our world like never before. Serving as responsible stewards of these crucial commons profoundly expands our circles of awareness. My dear friend Margarita Mora often asks, "What kind of ancestors do we want to be?" I want to be an ancestor who helped make the Anthropocene and the Anthropocosmos periods of history when humans helped the universe flourish with life and prosperity.
Many forms of Government have been tried, and will be tried in this world of sin and woe. No one pretends that democracy is perfect or all-wise. Indeed, it has been said that democracy is the worst form of Government except all those other forms that have been tried from time to time.
--Winston Churchill
I was on the board of the International Corporation for Names and Numbers (ICANN) from 2004 to 2007. This was a thankless task that I viewed as something like being on jury duty in exchange for being permitted to use the internet, upon which much of my life was built. Maybe people hate ICANN because it seems so bureaucratic, slow, and political, but I will always defend it as the best possible solution to something that is really hard--resolving the problem of allocating names and numbers for the internet when every country and every sector in the world has reasons for believing that they deserve a particular range of IP addresses or the rights to a domain name.
I view the early architecture of the internet as the most successful experiment in decentralized governance. The internet service providers and the people who ran the servers didn't need to know how the whole thing ran, they just needed to make sure that their corner of the internet was working properly and that people's email and packets magically found their way around the internet to the right places. Almost everything was decentralized except one piece--the determination of the unique names and numbers that identified every single unique thing connected to the internet. So it makes sense that this is the thing that was the hardest thing to do for the open and decentralized idealists there.
After Reuters picked up the news on May 20 that ICANN handed over the top level domain (TLD) .amazon to Jeff Bezos' Amazon.com, pending a 30 day comment period, Twitter and the broader internet turned into a flurry of conversations criticizing the ICANN process. It brought out all of the usual conspiracy theorists and internet governance pundits, which brought back old memories and reminded me how some things are still the same, even though much on the internet is barely recognizable from the early days. And while it made me cringe and wish that the people of the Amazon basin had gotten control of that TLD, I agree with ICANN's decision. I remembered my time at ICANN and how hard it was to make the right decisions in the face of what, to the public, appeared to be obviously wrong.
Originally, early internet pioneer Jon Postel ran the root servers that managed the names and numbers, and he decided who got what. Generally speaking, the rule was first come first serve, but be reasonable about the names you ask for. A move to design a more formal governance process for managing these resources began as the internet became more important and included institutions such as the Berkman Center, where I am a faculty associate. The death of Jon Postel accelerated the process and triggered a somewhat contentious move by the US Commerce Department and others to step in to create ICANN.
ICANN is a multi-stakeholder nonprofit organization originally created under the US Department of Commerce that has since transitioned to become a global multi-stakeholder community. Its complicated organizational structure includes various supporting organizations to represent country-level TLD organizations, the public, businesses, governments, the domain name registrars and registries, network security, etc. These constituencies are represented on the board of directors that deliberates on and makes many of the key decisions that deal with names and numbers on the internet. One of the keys to the success of ICANN was that it wasn't controlled by governments like the United Nations or the International Telecommunications Union (ITU), but that the governments were just part of an advisory function--the Government Advisory Council (GAC). This allowed many more voices at the table as peers than traditional intergovernmental organizations.
The difficulty of the process is that business and intellectual property interests believe international trademark laws should govern who gets to control the domain names. The "At Large" community, which represented users, has other views, and the GAC represents governments who have completely different views on how things should be decided. It's like playing with a Rubik's cube that actually doesn't have a solution.
The important thing was that everyone was in the room when we made decisions and got to say their say and the board, which represented all of the various constituents, would vote and ultimately make decisions after each of the week-long deliberation sessions. Everyone walked away feeling that they had their say and that in the end, they were somehow committed to adhere to the consensus-like process.
When I joined the board, my view was to be extremely transparent about the process and to stick to our commitments and focus on good governance, even if some of the decisions made us feel uncomfortable.
During my tenure, we had two very controversial votes. One was the approval of the .xxx TLD. Some governments, such as Brazil, thought that it would be a kind of "sex pavilion" that would increase pornography on the internet. The US conservative Christian community engaged in a letter-writing campaign to ICANN and to politicians to block the approval. The ICM Registry, the company proposing the domain, suggested that .xxx would allow them to create best practices including preventing copyright infringement and other illegal activity and create a way to enforce responsible adult entertainment.
It was first proposed in 2000 by the ICM Registry and resubmitted in 2004. They received a great deal of pushback and continued to fight for approval. In 2008, ICM filed an application with the International Centre for Dispute Resolution and the domain came up for vote again in 2009, when I was on the board. The proposal was struck down in a 9 to 5 vote against the domain--I voted in the minority, in favor of the proposal, because I didn't feel that we should deviate from our process and allow political pressure to sway us. Eventually, in 2011, ICANN approved the .xxx generic top-level domain.
In 2005 we approved .cat for Catalan, which also received a great deal of criticism and pushback because the community worried that it would be the beginning of a politicization of TLDs by various separatist movements and that ICANN would become the battleground for these disputes. But this concern never really manifested.
Then, on March 10, 2019, the board of ICANN approved the TLD .amazon, against the protests of the Amazon Cooperation Treaty Organization and the governments of South America representing the Amazon Basin. The vote was the result of seven years of deliberations and process, with governments arguing that a company shouldn't get the name of geographic region and Jeff Bezos' Amazon arguing that it had complied with all of the required processes.
When I first joined MIT, we owned what was called net 18. In other words, any IP address that started with 18. The IP addresses 18.0.0.1 through 18.255.255.254 were all owned by MIT. You could recognize any MIT computer because its IP address started with 18. MIT, one of the early users of the internet, was allocated a whole "class A" segment of the internet which adds up to 2,147,483,646 IP addresses--more than most countries. Clearly this wasn't "fair," but it was consistent with the "first come first serve" style of early internet resource allocation. In April 2017, MIT sold 8 million of these addresses to Amazon and broke up our net 18, to the sorrow of many of us who so cherished this privilege and status. This also required us to renumber many things at MIT and turn our network into a much more "normal" one.
Although I shook my fist at Amazon and capitalism when I heard this, in hindsight the elitist notion that MIT should have 2 billion IP addresses was also wrong and Amazon probably needed the addresses more.
So it was with similar ire that I read the tweet that said that Amazon got .amazon. I've been particularly involved in the protection of the rights of indigenous people through my conservation and cultural activities and my first reaction was that, yet again, Western capitalism and colonialism were treading on the rights of the vulnerable.
But then I remembered those hours and hours of deliberation and fighting over .xxx and the crazy arguments about why we couldn't let this happen. I also remember fighting until I was red in the face about how we needed to stick to our principles and our self-declared guidelines and not allow pressure from US politicians and their constituents to sway us.
While I am not close to the ICANN process these days, I can imagine the pressure that they must have come under. You can see the foot-dragging and years of struggle just reading the board resolution approving .amazon.
So while it annoys me, and I wish that .amazon went to the people of the Amazon basin, I also feel like ICANN is probably working and doing its job. The job of ICANN is to govern the name space in an open and inclusive process and to steward this process in the best, but never perfect, way possible. And if you really care, we are in that 30 day public comment period so speak up!
This column is the second in a series about young people and screens. Read the first post, about connected parenting, here.
When I was in high school, I emailed the authors of the textbooks we used so I could better question my teachers; I spent endless hours chatting with the sysadmins of university computer systems about networks; and I started threads online for many of my classes where we had much more robust conversations than in the classroom. The first conferences I attended as a teenager were conferences with mostly adult communities of online networkers who eventually became my mentors and colleagues.
I cannot imagine how I would have learned what I have learned or met the many, many people who've enriched my life and work without the internet. So I know first-hand how, today, the internet, online games, and a variety of emerging technologies can significantly benefit children and their experiences.
That said, I also know that, in general, the internet has become a more menacing place than when I was in school. To take just one example, parents and other industry observers share a growing concern about the content that YouTube serves up to young people. A Sesame Street sing-along with Elmo leads to one of those weird color ball videos leading to a string of clips that keeps them glued to screens, with increasingly stranger-engaging content of questionable social or educational value, interspersed with stuff that looks like content, but might be some sort of sponsored content for Play-Doh. The rise of commercial content for young people is exemplified by YouTube Kidfluencers, which markets itself as a tool that gives brands using YouTube "an added layer of kid safety," and their rampant marketing has many parents up in arms.
In response, Senator Ed Markey, a longtime proponent of children's online privacy protections, is cosponsoring a new bill to expand the Children's Online Privacy Protection Act (COPPA). It would, among other things, extend protection to children from age 12 to 15 and ban online marketing videos targeted at them. The hope is that this will compel sites like YouTube and Facebook to manage their algorithms so that they do not serve up endless streams of content promoting commercial products to children. It gets a little complicated, though, because in today's world, the kids themselves are brands, and they have product lines of their own. So the line between self-expression and endorsements is very blurry and confounds traditional regulations and delinations.
The proposed bill is well-intentioned and may limit exposure to promotional content, but it may also have unintended consequences. Take the existing version of COPPA, passed in 1998, which introduced a parental permission requirement for children under 13 to participate in commercial online platforms. Most open platforms responded by excluding those under 13, rather than take on the onerous parental permission process and challenges of serving children. This drove young people's participation underground on these sites, since they could easily misrepresent their age or use the account of a friend or caregiver. Research and everyday experience indicates that young people under 13 are all over YouTube and Facebook, and busy caregivers, including parents, are often complicit in letting this happen.
That doesn't mean, of course, that parents aren't concerned about the time their young people are spending on screens, and Google and Facebook have responded, respectively, with the kid-only "spaces" on YouTube and Messenger.
But these policy and tech solutions ignore the underlying reality that young people crave contact with bigger young people and grown-up expertise, and that mixed-age interaction is essential to their learning and development.
Not only is banning young people from open platforms an iffy, hard-to-enforce proposition, it's unclear whether it is even the best thing for them. It's possible that this new bill could damage the system like other well-intentioned efforts have in the past. I can't forget the overly stringent Computer Fraud and Abuse Act. Written a year after the movie War Games, the law made it a felony to break the terms of service of an online service, so that, say, an investigative journalist couldn't run a script to test on Facebook to make sure the algorithm was doing what they said it was. Regulating these technologies requires an interdisciplinary approach involving legal, policy, social, and technical experts working closely with industry, government, and consumers to get them to work the way we want them to.
Given the complexity of the issue, is the only way to protect young people to exclude them from the grown-up internet? Can algorithms be optimized for learning, high-quality content, and positive intergenerational communication for young people? What gets less attention rather than outright restriction is how we might optimize these platforms to provide joy, positive engagement, learning, and healthy communities for young people and families.
Children are exposed to risks at churches, schools, malls, parks, and anywhere adults and children interact. Even when harms and abuses happen, we don't talk about shutting down parks and churches, and we don't exclude young people from these intergenerational spaces. We also don't ask parents to evaluate the risks and give written permission every time their kid walks into an open commercial space like a mall or grocery store. We hold the leadership of these institutions accountable, pushing them to establish positive norms and punish abuse. As a society, we know the benefits of these institutions outweigh the harms.
Based on a massive EU-wide study of children online, communication researcher Sonia Livingstone argues that internet access should be considered a fundamental right of children. She notes that risks and opportunities go hand in hand: "The more often children use the internet, the more digital skills and literacies they generally gain, the more online opportunities they enjoy and—the tricky part for policymakers—the more risks they encounter." Shutting down children's access to open online resources often most harms vulnerable young people, such as those with special needs or those lacking financial resources. Consider, for example, the case of a home- and wheelchair-bound child whose parents only discovered his rich online gaming community and empowered online identity after his death. Or Autcraft, a Minecraft server community where young people with autism can foster friendships via a medium that often serves them better than face-to-face interactions.
As I was working on my last column about young people and screen time, I spent some time talking to my sister, Mimi Ito, who directs the Connected Learning Lab at UC Irvine. We discussed how these problems and the negative publicity around screens were causing caregivers to develop unhealthy relationships with their children while trying to regulate their exposure to screens and the content they delivered. The messages caregivers are getting about the need to regulate and monitor screen time are much louder than messages about how they can actively engage with young people's online interests. Mimi's recent book, Affinity Online: How Connection and Shared Interest Fuel Learning, features a range of mixed-age, online communities that demonstrate how young people can learn from other young people and adult experts online. Often it's the young people themselves that create communities, enforce norms, and insist on high-quality content. One of the cases, investigated by Rachel Cody Pfister, as her PhD work at the University of California, San Diego, is Hogwarts at Ravelry, a community of Harry Potter fans who knit together on Ravelry, an online platform for fiber arts. A 10-year-old girl founded the community, and members ranged from 11 to 70-plus at the time of Rachel's study.
Hogwarts at Ravelry is just one of a multitude of examples of free and open intergenerational online learning communities of different shapes and sizes. The MIT Media Lab, where I work, is home to Scratch, a project created in the Lifelong Kindergarten group. Millions of young people around the world are part of a safe, creative, and healthy space for creative coding. Some Reddit groups like /r/aww for cute animal content, or a range of subreddits on Pokemon Go, are lively spaces of intergenerational communication. Like with Scratch, these massive communities thrive because of strict content and community guidelines, algorithms optimized to support these norms, and dedicated human moderation.
YouTube is also an excellent source of content for learning and discovering new interests. One now famous 12-year-old learned to dubstep just by watching YouTube videos, for example. The challenge is squaring the incentives of free-for-all commercial platforms like YouTube with the needs of special populations like young people and intergenerational sub-communities with specific norms and standards. We need to recognize that young people will make contact with commercial content and grown-ups online, and we need to figure out better ways to regulate and optimize platforms to serve participants of mixed ages. This means bringing young people's interests, needs, and voices to the table, not shutting them out or making them invisible to online platforms and algorithms. This is why I've issued a call for research papers about algorithmic rights and protections for children together with my sister and our colleague and developmental psychologist, Candice Odgers. We hope to spark an interdisciplinary discussion of issues among a wide range of stakeholders to find answers to questions like: How can we create interfaces between the new, algorithmically governed platforms and their designers and civil society? How might we nudge YouTube and other platforms to be more like Scratch, designed for the benefit of young people and optimized not for engagement and revenue but instead for learning, exploration, and high-quality content? Can the internet support an ecosystem of platforms tailored to young people and mixed-age communities, where children can safely learn from each other, together with and from adults?
I know how important it is for young people to have connections to a world bigger and more diverse than their own. And I think that developers of these technologies (myself included) have a responsibility to design them based on scientific evidence and the participation of the public. We can't leave it to commercial entities to develop and guide today's learning platforms and internet communities—but we can't shut these platforms down or prevent children from having access to meaningful online relationships and knowledge, either.
Views: 27
When the Ridgecrest earthquake reached L.A. yesterday evening (no damage this far from the epicenter from that quake or the one the previous day) I was “in” a moving elevator under attack in the “Vader Immortal” Oculus Quest VR simulation. I didn’t realize that there was a quake at all, everything seemed part of the VR experience (haptic feedback in the hand controllers was already buzzing my arms at the time).
The only oddity was that I heard a strange clinking sound, that at the time had no obvious source but that I figured was somehow part of the simulation. Actually, it was probably the sound of ceiling fan knob chains above me hitting the glass light bulb fixtures as the fan was presumably swaying a bit.
Quakes of this sort are actually very easy to miss if you’re not sitting or standing quietly (I barely felt the one the previous day and wasn’t immediately sure that it was a quake), but I did find my experience last night to be rather amusing in retrospect.
By the way, “Vader Immortal” — and the Quest itself — are very, very cool, very much 21st century “sci-fi” tech finally realized. My thanks to Oculus for sending me a Quest for my experiments.
–Lauren–
Views: 19
So there’s yet another controversy surrounding YouTube and videos that include young children — this time concerns about YouTube suggesting such videos to “presumed” pedophiles.
We can argue about what YouTube should or should not be recommending to any given user. There are some calls for YT to not recommend such videos when it detects them (an imperfect process) — though I’m not convinced that this would really make much difference so long as the videos themselves are public.
But here’s a more fundamental question:
Why the hell are parents uploading videos of young children publicly to YouTube in the first place?
This is of course a subset of a more general issue — parents who apparently can’t resist posting all manner of photos and other personal information about their children in public online forums, much of which is going to be at the very least intensely embarrassing to those children when they’re older. And the Internet rarely ever forgets anything that was ever public (the protestations of EU politicians and regulators notwithstanding).
There are really only two major possibilities concerning such video uploads. Either the parents don’t care about these issues, or they don’t understand them. Or perhaps both.
Various display apps and web pages exist that will automatically display YT videos that have few or no current views from around the world. There’s an endless stream of these. Thousands. Millions? Typically these seem as if they have been automatically uploaded by various camera and video apps, possibly without any specific intentions for the uploading to occur. Many of these involve schools and children.
So a possible answer to my question above may be that many YT users — including parents of young children — are either not fully aware of what they are uploading, or do not realize that the uploads are public and are subject to being suggested to strangers or found by searching.
This leads us to another question. YT channel owners already have the ability to set their channel default privacy settings and the privacy settings for each individual video.
Currently those YT defaults are initially set to public.
Should YT’s defaults be private rather than public?
Looking at it from a user trust and safety standpoint, we may be approaching such a necessity, especially given the pressure for increased regulatory oversight from politicians and governments, which in my opinion is best avoided if at all possible.
These questions and their ramifications are complex to say the least.
Clearly, default channel and videos privacy would be the safest approach, ensuing that videos would typically only be shared to specific other users deemed suitable by the channel owner.
All of the public sharing capabilities of YT would still be present, but would require the owner to make specific decisions about the channel default and/or individual video settings. If a channel owner wanted to make some or all of their videos public — either to date or also going forward, that would be their choice. Full channel and individual videos privacy would only be the original defaults, purely as a safety measure.
Finer-grained settings might also be possible, not only including existing options like “unlisted” videos, but also specific options to control the visibility of videos and channels in search and suggestions.
Some of the complexities of such an approach are obvious. More controls means the potential for more user confusion. Fewer videos in search and suggestions limits visibility and could impact YT revenue streams to both Google and channel owners in complex ways that may be difficult to predict with significant accuracy.
But in the end, the last question here seems to be a relatively simple one. Should any YouTube uploaders ever have their videos publicly available for viewing, search, or suggestions if that was not actually their specific and informed intent?
I believe that the answer to that question is no.
Be seeing you.
–Lauren–
www.stewarthomesociety.org/blog
The main part of my website is here:
www.stewarthomesociety.org
And my censored YouTube profile is there:
http://www.youtube.com/stewarthome
YouTube actually removed a parody of a Fluxus film for violating their rules. This was a countdown from 10 to 1, no images in it at all, just numerals. Presumably the problem was the joke title 10 Erotic Movies - it had more than twenty thousand hits before being taken down by the authoritarians who run that platform. If YouTube won't allow a film like this, then Web 2.0 is a joke and we need to move on to Web 2.1, where we control the sites we're posting on!
However, you can listen to my punk rock slop and spoken word schlock, and even get free downloads, here:
http://www.last.fm/music/Stewart+Home
A few weeks ago I was asked to make some remarks at the MIT-Harvard Conference on the Uyghur Human Rights Crisis. When the student organizer of the conference, Zuly Mamat, asked me to speak at the event, I wasn't sure what I would say because I'm definitely not an expert on this topic. But as I dove into researching what is happening to the Uyghur community in China, I realized that it connected to a lot of the themes I have run up against in my own work, particularly the importance of considering the ethical and social implications of technology early on in the design and development process. The Uyghur human rights crisis demonstrates how the technology we build, even with the best of intentions, may be used to surveil and harm people. Many of my activities these days are focused on the prevention of misuse of technology in the future, but it requires more than just bolting ethicists onto product teams - I think it involves a fundamental shift in our priorities and a redesign of the relationship of the humanities and social sciences with engineering and science in academia and society. As a starting point, I think it is critically important to facilitate conversations about this problem through events like this one. You can view the video of the event here and read my edited remarks below.
Hello, I'm Joi Ito, the Director of the MIT Media Lab. I'm probably the least informed about this topic of everyone here, so first of all, I'm very grateful to all of the people who have been working on this topic and for helping me get more informed. I'm broadly interested in human rights, its relationship with technology and our role as Harvard and MIT and academia in general to intervene in these types of situations. So I want to talk mainly about that.
One of the things to think about not just in this case, but also more broadly, is the role of technology in surveillance and human rights. In the talks today, we've heard about some specific examples of how technology is being used to surveil the Uyghur community in China, but I thought I'd talk about it a little more generally. I specifically want to address the continuing investment in and ascension of the engineering and sciences in the world through ventures like MIT's new College of Computing, in terms of their influence and the scale at which they're being deployed. I believe that thinking about the ethical aspects of these investments is essential.
I remember when J.J. Abrams, one of our Director's Fellows and a film director for those of you who don't know, visited the Media Lab. We have 500 or so ongoing projects at the Media Lab and he asked some of the students, "Do you do anything that involves things like war or surveillance or things that you know, harm people?" And all of the students said, "No, of course we don't do that kind of thing. We make technology for good." And then he said, "Well let me re-frame that question, can you imagine an evil villain in any of my shows or movies using anything here to do really terrible things?" And everybody went, "Yeah!"
What's important to understand is that most engineers and scientists are developing tools to try to help the world, whether it's trying to model the brains of children in order to increase the quality and the effectiveness of education, or using sensors to help farmers grow crops. But what most people don't spend enough time thinking about is the dual use nature of the technology - the fact that technology can easily be used in ways that the designer did not intend.
Now, I think there are a lot of arguments about whose job it is to think about how technology can be used in unexpected and harmful ways. If I took the faculty in the Media Lab and put them on a line where at one end, the faculty believe we should think about all the social implications before doing anything, and at the other end they believe we should just build stuff and society will figure it out, I think there would be a fairly even distribution along the line. I would say that at MIT that's also roughly true. My argument is that we actually have to think more about the social implications of technology before designing it. It's very hard to un-design things, and I'm not saying that it's an easy task, and I'm not saying that we have to get everything perfect, but I think that having a more coherent view of the world and these implications is tremendously important.
The Media Lab is a little over 30 years old, and I've been there for 8 years, but I was very involved in the early days of the Internet. The other day, I was describing to Susan Silbey, the current faculty chair at MIT, how when we were building the Internet we thought if we could just provide a voice to everyone, if we could just connect everyone together, we would have world peace. I really believed that when we started, and I was expressing to Susan how naïve I feel now that the Internet has become something that's more akin to the little girl in the Exorcist, for those of you who have seen the movie. But Susan, being an anthropologist and historian said, "Well when you guys talked about connecting everybody together, we knew. The social scientists knew that it was going to be a mess."
One of the really important things I learned from my conversation with Susan was the extent to which the humanities have thought about and fought about a lot of these things. History has taught us a lot of these things. I know that it's somewhat taboo to invoke Nazi Germany in too many conversations, but if you look at the data that was collected in Europe to support social services, much of it was later used by the Nazis to roundup and persecute the Jews. And it's not exactly the same situation, but a lot of the databases that we're creating to help poor and disadvantaged families are also being used by the immigration services to find and target people for deportation.
Even the databases and technology that we use and create for the best of intentions can be subverted depending on who's in charge. So thinking about these systems is tremendously important. At MIT, we are, and I think that Zuly mentioned some of the specifics, working with tech companies that are working directly on surveillance technology or are in some way creating technologies that could be used for surveillance in China. Again thinking about the ethical issues is very important. I will point out that there are whole disciplines that work in this, STS, science technology in society, that's really what they do. They think about the impact of science and technology in society. They think about it in a historical context and provide us with a framework for thinking about these things. Thinking about how to integrate anthropology and STS into both the curriculum and the research at MIT is tremendously important.
The other thing to think about is allowing engineers more freedom to explore the application and impact of their work. One of the problems with scholarship is that many researchers don't have the freedom to fully test their hypotheses. For example, in January, Eric Topol tweeted about his paper that showed that of the 15 most impactful machine learning and medicine papers that had been published, none of them had been clinically validated. Many cases, in machine learning, you get some data, you tweak it and you get a very high effectiveness and then you walk away. Then the clinicians come in and they say "oh, but we can't replicate this, and we don't have the expertise" or "we tried it but it doesn't seem to work in practice." We're not providing, if you're following an academic path, the proper incentives for the computer scientists to integrate with and work closely with the clinicians in the field. One of the other challenges that we have is that our reward systems and the incentives that are in place don't encourage technologists to explore the social implications of the tech they produce. When this is the case, you fall a little bit short of actually getting to the question, "well, what does this actually mean?"
I co-teach a course at Harvard Law School called the Applied Challenges in Ethics and Governance of Artificial Intelligence, and through that class we've explored some research that considers the ethical and social impact of AI. To give you an example, one Media Lab project that we discussed was looking at risk scores used by the criminal justice system for sentencing and pre-trial assessments and bail. The project team initially thought "oh, we could just use a blockchain to verify the data and make the whole criminal sentencing system more efficient." But as the team started looking into it, they realized that the whole criminal justice system was somewhat broken. And as they started going deeper and deeper into the problem, they realized that while these prediction systems were making policing and judging possibly more efficient, they were also taking power away from the predictee and giving it to the predictor.
Basically, these automated systems were saying "okay, if you happen to live in this zip code, you will have a higher recidivism rate." But in reality, rearrest has more to do with policing and policy and the courts than it does with the criminality of the individual. By saying that this risk score can accurately predict how likely it is that this person will commit another crime, you're attributing the agency to the individual when actually much of the agency lies with the system. And by focusing on making the prediction tool more accurate, you end up ignoring existing weaknesses and biases in the overall justice system and the cause of those weaknesses. It's reminiscent of Caley Horan's writing on the history of insurance and redlining. She looks at the way in which insurance pricing, called actuarial fairness, became a legitimate way to use math to discriminate against people and how it took the debate away from the feminists and the civil rights leaders and made it an argument about the accuracy of algorithms.
The researchers who were trying to improve the criminal risk scoring system have completely pivoted to recommending that we stop using automated decision making in criminal justice. Instead they think we should use technology to look at the long term effects of policies in the criminal justice system and not to predict the criminality of individuals.
But this outcome is not common. I find that whether we're talking about tenure cases or publications or funding, we don't typically allow our researchers to end up in places that contradict the fundamental place where they started. So I think that's another thing that's really important. How do we create both research and curricular opportunities for people to explore their initial assumptions and hypotheses? As we think about this and this conversation, we should ask "how can we integrate this into our educational system?" Our academic process is really important and I love that we have scholars that are working on this, but how we bring this mentality to engineers and scientists is something that I'd love to think about and maybe in the Breakout Sessions we can work on that.
Now I want to pivot a little bit and talk about the role of academia in the Uyghur crisis. I know there are people who view this meeting as provocative or political and it reminds me of the March for Science that we had several years ago. I gave a talk at the first March for Science. Before the talk, when I was at a dinner table with a bunch of faculty (I won't name the faculty), someone said, "Why are you doing that? It's very political. We try not to be political, we're just scientists." And I said, "Well when it becomes political to tell the truth, when being supportive of climate science is political, when trying to support fundamental scientific research is political, then I'm political." So I don't want to be partisan, but I think if the truth is political, then I think we need to be political.
And this is not a new concept. If you look at the history of MIT, or just the history of academic freedom (there's the Statement of Principles on Academic Freedom and Tenure) you will find a bunch of interesting MIT history. In the late 40s and 50s, during the McCarthy period, society was going after communists and left wing people out of the fear of Communism. And many institutions were turning over their left wing Marxist academics, or firing them under pressure from the government. But MIT was quite good about protecting their Marxist affiliated faculty, and there's a very famous case that shows this. Dirk Struik, a math professor at MIT, was indicted by the Middlesex grand jury on charges of advocating the overthrow of the US and Massachusetts governments in 1951. At the time MIT suspended him with pay, but once the court abandoned the case due to lack of evidence and the fact that states shouldn't be ruling on this type of charge, MIT reinstated Professor Struik. This is a quote from the president at the time, James Killian about the incident.
"MIT believes that its faculty, as long as its members abide by the law, maintain the dignity and responsibility of their position, must be free to inquire, to challenge and to doubt in their search for what is true and good. They must be free to examine controversial matters, to reach conclusions of their own, to criticize and be criticized, and only through such unqualified freedom of thought and investigation can an educational institution, especially one dealing with science, perform its function of seeking truth."
Many of you may wonder why we have tenure at universities. We have tenure to protect our ability to question authority, to speak the truth and to really say what we think without fear of retribution.
There's another important case that demonstrates MIT's willingness to protect its faculty and students. In the early 1990s, MIT and a bunch of Ivy League schools came up with this idea to provide financial aid for low income students on a need basis. The Ivy League schools got together to coordinate on how they would assess need and how they would figure out how much financial aid to give to students. Weirdly, the United States government sued the Ivy League schools saying that this was an antitrust case, which was ridiculous because it was a charity. Most of the other universities caved in after this lawsuit, but Chuck Vest the president at the time said, "MIT has a long history of admitting students based on merit and a tradition of ensuring these students full financial aid." He refused to deny students financial aid, and a multi-year lawsuit ensued, in which eventually MIT won. And then this need-based scholarship system was enshrined in actual policy in the United States.
Many of the people who are here at MIT today probably don't remember this, but there's a great documentary film that shows MIT students and faculty literally clashing with police on these streets in an anti-Vietnam War protest 50 years ago. So in the not so distant past, MIT has been a very political place when it meant protecting our freedom to speak up.
More recently, I personally experienced this support for academic freedom. When Chelsea Manning's fellowship at the Harvard Kennedy School was rescinded, she emailed me and asked if she could speak at the Media Lab. I was thinking about it, and I asked the administration what they thought, and they thought it was a terrible idea. And when they told me that I said, "You know, now that means I have to invite her." I remember our Provost Marty saying, "I know." And that's what I think is wonderful about being here at MIT: the fact that the administration understands that faculty must be allowed to act independently of the Institute. Another example is when the administration was deciding what to do about funding from Saudi Arabia. The administration released a report, which has a few critics, that basically said, "we're going to let people decide what they want to do." I think each group or faculty member at MIT is permitted to make their own decision about whether to accept funding from Saudi Arabia. MIT, in my experience, has always stood by the academic freedom of whatever unit at the Institute that's trying to do what it wants to do.
I think we're in a very privileged place and I think that it's not only our freedom, but our obligation to speak up. It's also our responsibility to fight for the academic freedom of people in our community as well as people in other communities, and provide leadership. I really do want to thank the organizers of this conference for doing that. I think it's very bold, but I think it's very becoming of both MIT and Harvard. I read a very disturbing report from Human Rights Watch that talked about how Chinese scholars overseas are starting to have difficulties in speaking up, which I think is somewhat unprecedented because of the capabilities of today's technology. And I think there are similar reports about scholars from Saudi Arabia. The ability of these countries to surveil their citizens overseas and impinge on their academic freedom is a tremendously important topic to discuss, and think about both technically, legally and otherwise. I think it's also a very important thing for us to talk about how to protect the freedoms of students studying here.
Thank you again for making this topic now very front of mind for me. On the panel I'd love to try to describe some concrete steps that we can take to continue to protect this freedom that we have. Thank you.
Views: 14
Almost exactly two years ago, I noted here the comprehensive features that Google provides for users to access their Google-related activity data, and to control and/or delete it in a variety of ways. Please see:
The Google Page That Google Haters Don't Want You to Know About – https://lauren.vortex.com/2017/04/20/the-google-page-that-google-haters-dont-want-you-to-know-about
and:
Quick Tutorial: Deleting Your Data Using Google's “My Activity” – https://lauren.vortex.com/2017/04/24/quick-tutorial-deleting-your-data-using-googles-my-activity
Today Google announced a new feature that I’ve long been hoping for — the option to automatically delete these kinds of data after specific periods of time have elapsed (3 month and 18 month options). And of course, you still have the ability to use the longstanding manual features for control and deletion of such data whenever you desire, as described at the links mentioned above.
The new auto-delete feature will be deployed over coming weeks first to Location History and to Web & App Activity.
This is really quite excellent. It means that you can take advantage of the customization and other capabilities that are made possible by leaving data collection enabled, but if you’re concerned about longer term storage of that data, you’ll be able to activate auto-delete and really get the best of both worlds without needing to manually delete data yourself at intervals.
Auto-delete is a major privacy-positive milestone for Google, and is a model that other firms should follow.
My kudos to the Google teams involved!
–Lauren–
Views: 19
Could machine learning/AI techniques help to prevent mass shootings or other kinds of terrorist attacks? That’s the question. I do not profess to know the answer — but it’s a question that as a society we must seriously consider.
A notable relatively recent attribute of many mass attacks is that the criminal perpetrators don’t only want to kill, they want as large an audience as possible for their murderous activities, frequently planning their attacks openly on the Internet, even announcing online the initiation of their killing sprees and providing live video streams as well. Sometimes they use private forums for this purpose, but public forums seem to be even more popular in this context, given their potential for capturing larger audiences.
It’s particularly noteworthy that in some of these cases, members of the public were indeed aware of such attack planning and announcements due to those public postings, but chose not to report them. The reasons for the lack of reporting can be several. Users may be unsure whether or not the posts are serious, and don’t want to report someone for a fake attack scenario. Other users may want to report but not know where to report such a situation. And there may be other users who are actually urging the perpetrator onward to the maximum possible violence.
“Freedom of speech” and some privacy protections are generally viewed as ending where credible threats begin. Particularly in the context of public postings, this suggests that detecting these kinds of attacks before they have actually occurred may possibly be viewed as a kind of “big data” problem.
We can relatively easily list some of the factors that would need to be considered in these respects.
What level of resources would be required to keep an “automated” watch on at least the public postings and sites most likely to harbor the kinds of discussions and “attack manifestos” of concern? Could tools be developed to help separate false positive, faked, forged, or other “fantasy” attack postings from the genuine ones? How would these be tracked over time to include other sites involved in these operations, and to prevent “gaming” of the systems that might attempt to divert these tools away from genuine attack planning?
Clearly — as in many AI-related areas — automated systems alone would not be adequate by themselves to trigger full-scale alarms. These systems would primarily act as big filters, and would pass along to human teams their perceived alerts — with those teams making final determinations as to dispositions and possible referrals to law enforcement for investigatory or immediate preventative actions.
It can be reasonably argued that anyone publicly posting the kinds of specific planning materials that have been discovered in the wake of recent attacks has effectively surrendered various “rights” to privacy that might ordinarily be in force.
The fact that we keep discovering these kinds of directly related discussions and threats publicly online in the wake of these terrorist attacks, suggests that we are not effectively using the public information that is already available toward stopping these attacks before they actually occur.
To the extent that AI/machine learning technologies — in concert with human analysis and decision-making — may possibly provide a means to improve this situation, we should certainly at least be exploring the practical possibilities and associated issues.
–Lauren–
Applied Ethical and Governance Challenges in Artificial Intelligence (AI)
Part 3: Intervention
We recently completed the third and final section of our course that I co-taught with Jonathan Zittrain and TA'ed by Samantha Bates, John Bowers and Natalie Saltiel. The plan was to try to bring the discussion of diagnosis and prognosis in for a landing and figure out how to intervene.
The first class of this section (the eighth class of the course) looked at the use of algorithms in decision making. One paper that we read was the most recent in a series of papers by Jon Kleinberg, Sendhil Mullainathan and Cass Sunstein that supported the use of algorithms in decision making such as pretrial risk assessments - the particular paper we read focused on the use of algorithms for measuring the bias of the decision making. Sendhil Mullainathan, one of the authors of the paper joined us in the class. The second paper was by Rodrigo Ochigame, a history and science and technology in society (STS) student who criticized the fundamental premise of reducing notions such as "fairness" to "computationals formalisms" such as algorithms. The discussion which at points took the form of a lively debate was extremely interesting and helped us and the students see how important it is to question the framing of the questions and the assumptions that we often make when we begin working on a solution without coming to a societal agreement of the problem.
In the case of pretrial risk assessments, the basic question about whether rearrests are more of an indicator of policing practice or the "criminality of the individual" fundamentally changes whether the focus should be on the "fairness" and accuracy of the prediction of the criminality of the individual or whether we should be questioning the entire system of incarceration and its assumptions.
At the end of the class, Sendhil agreed to return to have a deeper and longer conversation with my Humanizing AI in Law (HAL) team to discuss this issue further.
In the next class, we discussed the history of causal inference and how statistics and correlation have dominated modern machine learning and data analysis. We discussed the difficulties and challenges in validating causal claims but also the importance of causal claims. In particular, we looked at how legal precedent has from time to time made references to the right to individualized sentencing. Clearly, risk scores used in sentencing that are protected by trade secrets and confidentiality agreements challenge the right to due process as expressed in the Wisconsin v. Loomis case as well as the right to an individualized sentence.
The last class focused on adversarial examples and technical debt - which helped us think about when and how policies and important "tests" and controls can and should be put in place vs when, if ever, we should just "move quickly and break things." I'm not sure if it was the consensus of the class, but I felt that somehow we needed a new design process that allowed for the creation of design stories and "tests" that could be developed by the users and members of the affected communities that were integrated into the development process - participant design that was deeply integrated into something that looked like agile development story and test development processes. Fairness and other contextual parameters are dynamic and can only be managed through interactions with the systems in which the algorithms are deployed. Figuring out a way to somehow integrate the dynamic nature of the social system seems like a possible approach for mitigating a category of technical debt and designing systems untethered from the normative environments in which they are deployed.
Throughout the course, I observed students learning from one another, rethinking their own assumptions, and collaborating on projects outside of class. We may not have figured out how to eliminate algorithmic bias or come up with a satisfactory definition of what makes an autonomous system interpretable, but we did find ourselves having conversations and coming to new points of view that I don't think would have happened otherwise.
It is clear that integrating humanities and social science into the conversation about law, economics and technology is required for us to navigate ourselves out of the mess that we've created and to chart a way forward into a our uncertain future with our increasingly algorithmic societal systems.
Syllabus Notes
By Samantha Bates
In our final stage of the course, the intervention stage, we investigated potential solutions to the problems we identified earlier in the course. Class discussions included consideration of the various tradeoffs of implementing potential solutions and places to intervene in different systems. We also investigated the balance between waiting to address potential weaknesses in a given system until after deployment versus proactively correcting deficiencies before deploying the autonomous system.
Class Session 8: Intervening on behalf of fairness
This class was structured as a conversation involving two guests, University of Chicago Booth School of Business Professor Sendhil Mullainathan and MIT PhD student Rodrigo Ochigame. As a class we debated whether elements of the two papers were reconcilable given their seemingly opposite viewpoints.
-
"Discrimination in the Age of Algorithms" by Jon Kleinberg, Jens Ludwig, Sendhil Mullainathan, and Cass R. Sunstein (February 2019).
-
[FORTHCOMING] "The Illusion of Algorithmic Fairness" by Rodrigo Ochigame (2019)
The main argument in "Discrimination in the Age of Algorithms" is that algorithms make it easier to identify and prevent discrimination. The authors point out that current obstacles to proving discrimination are primarily caused by opacity around human decision making. Human decision makers can make up justifications for their decisions after the fact or may be influenced by bias without even knowing it. The authors argue that by making algorithms transparent, primarily through the use of counterfactuals, we can determine which components of the algorithm are causing a biased outcome. The paper also suggests that we allow algorithms to consider personal attributes such as race and gender in certain contexts because doing so could help counteract human bias. For example, if managers consistently give higher performance ratings to male workers over female workers, the algorithm won't be able to figure out that managers are discriminating against women in the workplace if it can't incorporate data about gender. But if we allow the algorithm to be aware of gender when calculating work productivity, it may be able to uncover existing biases and prevent them from being perpetuated.
The second assigned reading, "The Illusion of Algorithmic Fairness," demonstrates that attempts to reduce elements of fairness to mathematical equations have persisted throughout history. Discussions about algorithmic fairness today mirror many of the same points of contention reached in past debates about fairness, such as whether we should optimize for utility or optimize for fair outcomes. Consequently, fairness debates today have inherited some assumptions from these past discussions. In particular, we "take many concepts for granted including probability, risk, classification, correlation, regression, optimization, and utility." The author argues that despite our technical advances, fairness remains "irreducible to a mathematical property of algorithms, independent from specific social contexts." He shows that any attempt at formalism will ultimately be influenced by the social and political climate of the time. Moreover, researchers frequently use misrepresentative, historical data to create "fair" algorithms. The way that the data is framed and interpreted can be misrepresentative and frequently reinforces existing discrimination (for example, predictive policing algorithms predict future policing, not future crime.)
These readings set the stage for a conversation about how we should approach developing interventions. While "Discrimination in the Age of Algorithms" makes a strong case for using algorithms (in conjunction with counterfactuals) to improve the status quo and make it easier to prove discrimination in court, "The Illusion of Algorithmic Fairness" cautions against trying to reduce components of fairness to mathematical properties. The "Illusion of Algorithmic Fairness" paper shows that this is not a new endeavor. Humans have tried to standardize the concept of fairness as early as 1700 and we have proved time and again that determining what is fair and what is unfair is much too complicated and context dependent to model in an algorithm.
Class Session 9: Intervening on behalf of interpretability
In our second to last class, we discussed causal inference, how it differs from correlative machine learning techniques, and its benefits and drawbacks. We then considered how causal models could be deployed in the criminal justice context to generate individualized sentences and what an algorithmically informed individualized sentence would look like.
-
The Book of Why by Judea Pearl and Dana Mackenzie, Basic Books (2018). Read Introduction.
-
State of Wisconsin v. Eric Loomis (2016), paragraphs 11-28 and 67-74.
The Book of Why describes the emerging field of causal inference, which attempts to model how the human brain works by considering cause and effect relationships. The introduction delves a little into the history of causal inference and explains that it took time for the field to develop because it was nearly impossible for scientists to communicate causal relationships using mathematical terms. We've now devised ways to model what the authors call "the do-operator" (which indicates that there was some action/form of intervention that makes the relationship causal rather than correlative) through diagrams, mathematical formulas and lists of assumptions.
One main point of the introduction and the book is that "data are dumb" because they don't explain why something happened. A key component of causal inference is the creation of counterfactuals to help us understand what would have happened had certain circumstances been different. The hope with causal inference is that it will be less impacted by bias because causal inference models do not look for correlations in data, but rather focus on the "do-operator." A causal inference approach may also make algorithms more interpretable because counterfactuals will offer a better way to understand how the AI makes decisions.
The other assigned reading, State of Wisconsin v. Eric Loomis, is a 2016 case about the use of risk assessment tools in the criminal justice system. In Loomis, the court used a risk assessment tool, COMPAS, to determine the defendant's risk of pretrial recidivism, general recidivism, and violent recidivism. The key question in this case was whether the judge should be able to consider the risk scores when determining a defendant's sentence. The State Supreme Court in this case decided that judges could consider the risk score because they also take into account other evidence when making sentencing decisions. For the purposes of this class, the case provided a lede into a discussion about the right to an individualized sentence and whether risk assessment scores can result in more fair outcomes for defendants. However, it turns out that risk assessment tools should not be employed if the goal is to produce individualized sentences. Despite their appearance of generating unique risk scores for defendants, risk assessment scores are not individualized as they compare information about an individual defendant to data about similar groups of offenders to determine that individual's recidivism risk.
Class Session 10: Intervening against adversarial examples and course conclusion
We opened our final class with a discussion about adversarial examples and technical debt before wrapping up the course with a final reflection on the broader themes and findings of the course.
-
"Hidden Technical Debt in Machine Learning Systems" by D. Sculley et al., NIPS (2015)
The term "technical debt" refers to the challenge of keeping machine learning systems up to date. While technical debt is a factor in any type of technical system, machine learning systems are particularly susceptible to collecting a lot of technical debt because they tend to involve many layers of infrastructure (code and non code). Technical debt also tends to accrue more in systems that are developed and deployed quickly. In a time crunch, it is more likely that new features will be added without deleting old ones and that the systems will not be checked for redundant features or unintended feedback loops before they are deployed. In order to combat technical debt, the authors suggest several approaches including, fostering a team culture that encourages simplifying systems and eliminating unnecessary features and creating an alert system that signals when a system has run up against pre-programmed limits and requires review.
During the course retrospective, students identified several overarching themes of the class including, the effectiveness and importance of interdisciplinary learning, the tendency of policymakers and industry leaders to emphasize short term outcomes over long term consequences of decisions, the challenge of teaching engineers to consider the ethical implications of their work during the development process, and the lack of input from diverse groups in system design and deployment.
Like most parents of young children, I've found that determining how best to guide my almost 2-year-old daughter's relationship with technology--especially YouTube and mobile devices--is a challenge. And I'm not alone: One 2018 survey of parents found that overuse of digital devices has become the number one parenting concern in the United States.
Empirically grounded, rigorously researched advice is hard to come by. So perhaps it's not surprising that I've noticed a puzzling trend in my friends who provide me with unsolicited parenting advice. In general, my most liberal and tech-savvy friends exercise the most control and are weirdly technophobic when it comes to their children's screen time. What's most striking to me is how many of their opinions about children and technology are not representative of the broader consensus of research, but seem to be based on fearmongering books, media articles, and TED talks that amplify and focus on only the especially troubling outcomes of too much screen time.
I often turn to my sister, Mimi Ito, for advice on these issues. She has raised two well-adjusted kids and directs the Connected Learning Lab at UC Irvine, where researchers conduct extensive research on children and technology. Her opinion is that "most tech-privileged parents should be less concerned with controlling their kids' tech use and more about being connected to their digital lives." Mimi is glad that the American Association of Pediatrics (AAP) dropped its famous 2x2 rule--no screens for the first two years, and no more than two hours a day until a child hits 18. She argues that this rule fed into stigma and parent-shaming around screen time at the expense of what she calls "connected parenting"--guiding and engaging in kids' digital interests.
One example of my attempt at connected parenting is watching YouTube together with Kio, singing along with Elmo as Kio shows off the new dance moves she's learned. Everyday, Kio has more new videos and favorite characters that she is excited to share when I come home, and the songs and activities follow us into our ritual of goofing off in bed as a family before she goes to sleep. Her grandmother in Japan is usually part of this ritual in a surreal situation where she is participating via FaceTime on my wife's iPhone, watching Kio watching videos and singing along and cheering her on. I can't imagine depriving us of these ways of connecting with her.
The (Unfounded) War on ScreensThe anti-screen narrative can sometimes read like the War on Drugs. Perhaps the best example is Glow Kids, in which Nicholas Kardaras tells us that screens deliver a dopamine rush rather like sex. He calls screens "digital heroin" and uses the term "addiction" when referring to children unable to self-regulate their time online.
More sober (and less breathlessly alarmist) assessments by child psychologists and data analysts offer a more balanced view of the impact of technology on our kids. Psychologist and baby observer Alison Gopnik, for instance, notes: "There are plenty of mindless things that you could be doing on a screen. But there are also interactive, exploratory things that you could be doing." Gopnik highlights how feeling good about digital connections is a normal part of psychology and child development. "If your friends give you a like, well, it would be bad if you didn't produce dopamine," she says.
Other research has found that the impact of screens on kids is relatively small, and even the conservative AAP says that cases of children who have trouble regulating their screen time are not the norm, representing just 4 percent to 8.5 percent of US children. This year, Andrew Przybylski and Amy Orben conducted a rigorous analysis of data on more than 350,000 adolescents and found a nearly negligible effect on psychological well-being at the aggregate level.
In their research on digital parenting, Sonia Livingstone and Alicia Blum-Ross found widespread concern among parents about screen time. They posit, however, that "screen time" is an unhelpful catchall term and recommend that parents focus instead on quality and joint engagement rather than just quantity. The Connected Learning Lab's Candice Odgers, a professor of psychological sciences, reviewed the research on adolescents and devices and found as many positive as negative effects. She points to the consequences of unbalanced attention on the negative ones. "The real threat isn't smartphones. It's this campaign of misinformation and the generation of fear among parents and educators."
We need to immediately begin rigorous, longitudinal studies on the effects of devices and the underlying algorithms that guide their interfaces and their interactions with and recommendations for children. Then we can make evidence-based decisions about how these systems should be designed, optimized for, and deployed among children, and not put all the burden on parents to do the monitoring and regulation.
My guess is that for most kids, this issue of screen time is statistically insignificant in the context of all the other issues we face as parents--education, health, day care--and for those outside my elite tech circles even more so. Parents like me, and other tech leaders profiled in a recent New York Times series about tech elites keeping their kids off devices, can afford to hire nannies to keep their kids off screens. Our kids are the least likely to suffer the harms of excessive screen time. We are also the ones least qualified to be judgmental about other families who may need to rely on screens in different ways. We should be creating technology that makes screen entertainment healthier and fun for all families, especially those who don't have nannies.
I'm not ignoring the kids and families for whom digital devices are a real problem, but I believe that even in those cases, focusing on relationships may be more important than focusing on controlling access to screens.
Keep It PositiveOne metaphor for screen time that my sister uses is sugar. We know sugar is generally bad for you and has many side effects and can be addictive to kids. However, the occasional bonding ritual over milk and cookies might have more benefit to a family than an outright ban on sugar. Bans can also backfire, fueling binges and shame as well as mistrust and secrecy between parents and kids.
When parents allow kids to use computers, they often use spying tools, and many teens feel parental surveillance is invasive to their privacy. One study showed that using screen time to punish or reward behavior actually increased net screen time use by kids. Another study by Common Sense Media shows what seems intuitively obvious: Parents use screens as much as kids. Kids model their parents--and have a laserlike focus on parental hypocrisy.
In Alone Together, Sherry Turkle describes the fracturing of family cohesion because of the attention that devices get and how this has disintegrated family interaction. While I agree that there are situations where devices are a distraction--I often declare "laptops closed" in class, and I feel that texting during dinner is generally rude--I do not feel that iPhones necessarily draw families apart.
In the days before the proliferation of screens, I ran away from kindergarten every day until they kicked me out. I missed more classes than any other student in my high school and barely managed to graduate. I also started more extracurricular clubs in high school than any other student. My mother actively supported my inability to follow rules and my obsessive tendency to pursue my interests and hobbies over those things I was supposed to do. In the process, she fostered a highly supportive trust relationship that allowed me to learn through failure and sometimes get lost without feeling abandoned or ashamed.
It turns out my mother intuitively knew that it's more important to stay grounded in the fundamentals of positive parenting. "Research consistently finds that children benefit from parents who are sensitive, responsive, affectionate, consistent, and communicative" says education professor Stephanie Reich, another member of the Connected Learning Lab who specializes in parenting, media, and early childhood. One study shows measurable cognitive benefits from warm and less restrictive parenting.
When I watch my little girl learning dance moves from every earworm video that YouTube serves up, I imagine my mother looking at me while I spent every waking hour playing games online, which was my pathway to developing my global network of colleagues and exploring the internet and its potential early on. I wonder what wonderful as well as awful things will have happened by the time my daughter is my age, and I hope a good relationship with screens and the world beyond them can prepare her for this future.
Views: 13
Despite my very long history of enjoying “apocalyptic” and “technology run amok” sci-fi films, I’ve been forthright in my personal belief that AI and associated machine learning systems hold enormous promise for the betterment of our lives and our planet (“How AI Could Save Us All” – https://lauren.vortex.com/2018/05/01/how-ai-could-save-us-all).
Of course there are definitely ways that we could screw this up. So deep discussion from a wide variety of viewpoints is critical to “accentuate the positive — eliminate the negative” (as the old Bing Crosby song lyrics suggest).
A time-tested model for firms needing to deal with these kinds of complex situations is the appointment of external interdisciplinary advisory panels.
Google announced its own such panel — the “Advanced Technology External Advisory Council” (ATEAC), last week.
Controversy immediately erupted both inside and outside of Google, particularly relating to the presence of prominent right-wing think tank Heritage Foundation president Kay Cole James. Another invited member — behavioral economist and privacy researcher Alessandro Acquisti — has now pulled out from ATEAC, apparently due to James’ presence on the panel and the resulting protests.
This is all extraordinarily worrisome.
While I abhor the sentiments of the Heritage Foundation, an AI advisory panel composed only of “yes men” in agreement more left-wing (and so admittedly my own) philosophies regarding social issues strikes me as vastly more dangerous.
Keeping in mind that advisory panels typically do not make policy — they only make recommendations — it is critical to have a wide range of input to these panels, including views with which we may personally strongly disagree, but that — like it or not — significant numbers of politicians and voters do enthusiastically agree with. The man sitting in the Oval Office right now is demonstrable proof that such views — however much we may despise them personally — are most definitely in the equation.
“Filter bubbles” are extraordinarily dangerous on both the right and left. One of the reasons why I so frequently speak on national talk radio — whose audiences are typically very much skewed to the right — is that I view this as an opportunity to speak truth (as I see it) regarding technology issues to listeners who are not often exposed to views like mine from the other commentators that they typically see and hear. And frequently, I afterwards receive emails saying “Thanks for explaining this like you did — I never heard it explained that way before” — making it all worthwhile as far as I’m concerned.
Not attempting to include a wide variety of viewpoints on a panel dealing with a subject as important as AI would not only give the appearance of “stacking the deck” to favor preconceived outcomes, but would in fact be doing exactly that, opening up the firms involved to attacks by haters and pandering politicians who would just love to impose draconian regulatory regimes for their own benefits.
The presence on an advisory panel of someone with whom other members may dramatically disagree does not imply endorsement of that individual.
I want to know what people who disagree with me are thinking. I want to hear from them. There’s an old saying: “Keep your friends close and your enemies closer.” Ignoring that adage is beyond foolish.
We can certainly argue regarding the specific current appointments to ATEAC, but viewing an advisory panel like this as some sort of rubber stamp for our preexisting opinions would be nothing less than mental malpractice.
AI is far too crucial to all of our futures for us to fall into that sort of intellectual trap.
–Lauren–
In the late 1970s, the computer, which for decades had been a mysterious, hulking machine that only did the bidding of corporate overlords, suddenly became something the average person could buy and take home. An enthusiastic minority saw how great this was and rushed to get a computer of their own. For many more people, the arrival of the microcomputer triggered helpless anxiety about the future. An ad from a magazine at the time promised that a home computer would "give your child an unfair advantage in school." It showed a boy in a smart blazer and tie eagerly raising his hand to answer a question, while behind him his dim-witted classmates look on sullenly. The ad and others like it implied that the world was changing quickly and, if you did not immediately learn how to use one of these intimidating new devices, you and your family would be left behind.
In the UK, this anxiety metastasized into concern at the highest levels of government about the competitiveness of the nation. The 1970s had been, on the whole, an underwhelming decade for Great Britain. Both inflation and unemployment had been high. Meanwhile, a series of strikes put London through blackout after blackout. A government report from 1979 fretted that a failure to keep up with trends in computing technology would "add another factor to our poor industrial performance."1 The country already seemed to be behind in the computing arena—all the great computer companies were American, while integrated circuits were being assembled in Japan and Taiwan.
In an audacious move, the BBC, a public service broadcaster funded by the government, decided that it would solve Britain's national competitiveness problems by helping Britons everywhere overcome their aversion to computers. It launched the Computer Literacy Project, a multi-pronged educational effort that involved several TV series, a few books, a network of support groups, and a specially built microcomputer known as the BBC Micro. The project was so successful that, by 1983, an editor for BYTE Magazine wrote, "compared to the US, proportionally more of Britain's population is interested in microcomputers."2 The editor marveled that there were more people at the Fifth Personal Computer World Show in the UK than had been to that year's West Coast Computer Faire. Over a sixth of Great Britain watched an episode in the first series produced for the Computer Literacy Project and 1.5 million BBC Micros were ultimately sold.3
An archive containing every TV series produced and all the materials published for the Computer Literacy Project was put on the web last year. I've had a huge amount of fun watching the TV series and trying to imagine what it would have been like to learn about computing in the early 1980s. But what's turned out to be more interesting is how computing was taught. Today, we still worry about technology leaving people behind. Wealthy tech entrepreneurs and governments spend lots of money trying to teach kids "to code." We have websites like Codecademy that make use of new technologies to teach coding interactively. One would assume that this approach is more effective than a goofy '80s TV series. But is it?
The Computer Literacy ProjectThe microcomputer revolution began in 1975 with the release of the Altair 8800. Only two years later, the Apple II, TRS-80, and Commodore PET had all been released. Sales of the new computers exploded. In 1978, the BBC explored the dramatic societal changes these new machines were sure to bring in a documentary called "Now the Chips Are Down."
The documentary was alarming. Within the first five minutes, the narrator explains that microelectronics will "totally revolutionize our way of life." As eerie synthesizer music plays, and green pulses of electricity dance around a magnified microprocessor on screen, the narrator argues that the new chips are why "Japan is abandoning its ship building, and why our children will grow up without jobs to go to." The documentary goes on to explore how robots are being used to automate car assembly and how the European watch industry has lost out to digital watch manufacturers in the United States. It castigates the British government for not doing more to prepare the country for a future of mass unemployment.
The documentary was supposedly shown to the British Cabinet.4 Several government agencies, including the Department of Industry and the Manpower Services Commission, became interested in trying to raise awareness about computers among the British public. The Manpower Services Commission provided funds for a team from the BBC's education division to travel to Japan, the United States, and other countries on a fact-finding trip. This research team produced a report that cataloged the ways in which microelectronics would indeed mean major changes for industrial manufacturing, labor relations, and office work. In late 1979, it was decided that the BBC should make a ten-part TV series that would help regular Britons "learn how to use and control computers and not feel dominated by them."5 The project eventually became a multimedia endeavor similar to the Adult Literacy Project, an earlier BBC undertaking that involved a TV series and supplemental courses and helped two million people improve their reading.
The producers behind the Computer Literacy Project were keen for the TV series to feature "hands-on" examples that viewers could try on their own if they had a microcomputer at home. These examples would have to be in BASIC, since that was the language (really the entire shell) used on almost all microcomputers. But the producers faced a thorny problem: Microcomputer manufacturers all had their own dialects of BASIC, so no matter which dialect they picked, they would inevitably alienate some large fraction of their audience. The only real solution was to create a new BASIC—BBC BASIC—and a microcomputer to go along with it. Members of the British public would be able to buy the new microcomputer and follow along without worrying about differences in software or hardware.
The TV producers and presenters at the BBC were not capable of building a microcomputer on their own. So they put together a specification for the computer they had in mind and invited British microcomputer companies to propose a new machine that met the requirements. The specification called for a relatively powerful computer because the BBC producers felt that the machine should be able to run real, useful applications. Technical consultants for the Computer Literacy Project also suggested that, if it had to be a BASIC dialect that was going to be taught to the entire nation, then it had better be a good one. (They may not have phrased it exactly that way, but I bet that's what they were thinking.) BBC BASIC would make up for some of BASIC's usual shortcomings by allowing for recursion and local variables.6
The BBC eventually decided that a Cambridge-based company called Acorn Computers would make the BBC Micro. In choosing Acorn, the BBC passed over a proposal from Clive Sinclair, who ran a company called Sinclair Research. Sinclair Research had brought mass-market microcomputing to the UK in 1980 with the Sinclair ZX80. Sinclair's new computer, the ZX81, was cheap but not powerful enough for the BBC's purposes. Acorn's new prototype computer, known internally as the Proton, would be more expensive but more powerful and expandable. The BBC was impressed. The Proton was never marketed or sold as the Proton because it was instead released in December 1981 as the BBC Micro, also affectionately called "The Beeb." You could get a 16k version for £235 and a 32k version for £335.
In 1980, Acorn was an underdog in the British computing industry. But the BBC Micro helped establish the company's legacy. Today, the world's most popular microprocessor instruction set is the ARM architecture. "ARM" now stands for "Advanced RISC Machine," but originally it stood for "Acorn RISC Machine." ARM Holdings, the company behind the architecture, was spun out from Acorn in 1990.
 A bad picture of a BBC Micro, taken by me at the Computer History Museum
A bad picture of a BBC Micro, taken by me at the Computer History Museum
in Mountain View, California.
A dozen different TV series were eventually produced as part of the Computer Literacy Project, but the first of them was a ten-part series known as The Computer Programme. The series was broadcast over ten weeks at the beginning of 1982. A million people watched each week-night broadcast of the show; a quarter million watched the reruns on Sunday and Monday afternoon.
The show was hosted by two presenters, Chris Serle and Ian McNaught-Davis. Serle plays the neophyte while McNaught-Davis, who had professional experience programming mainframe computers, plays the expert. This was an inspired setup. It made for awkward transitions—Serle often goes directly from a conversation with McNaught-Davis to a bit of walk-and-talk narration delivered to the camera, and you can't help but wonder whether McNaught-Davis is still standing there out of frame or what. But it meant that Serle could voice the concerns that the audience would surely have. He can look intimidated by a screenful of BASIC and can ask questions like, "What do all these dollar signs mean?" At several points during the show, Serle and McNaught-Davis sit down in front of a computer and essentially pair program, with McNaught-Davis providing hints here and there while Serle tries to figure it out. It would have been much less relatable if the show had been presented by a single, all-knowing narrator.
The show also made an effort to demonstrate the many practical applications of computing in the lives of regular people. By the early 1980s, the home computer had already begun to be associated with young boys and video games. The producers behind The Computer Programme sought to avoid interviewing "impressively competent youngsters," as that was likely "to increase the anxieties of older viewers," a demographic that the show was trying to attract to computing.7 In the first episode of the series, Gill Nevill, the show's "on location" reporter, interviews a woman that has bought a Commodore PET to help manage her sweet shop. The woman (her name is Phyllis) looks to be 60-something years old, yet she has no trouble using the computer to do her accounting and has even started using her PET to do computer work for other businesses, which sounds like the beginning of a promising freelance career. Phyllis says that she wouldn't mind if the computer work grew to replace her sweet shop business since she enjoys the computer work more. This interview could instead have been an interview with a teenager about how he had modified Breakout to be faster and more challenging. But that would have been encouraging to almost nobody. On the other hand, if Phyllis, of all people, can use a computer, then surely you can too.
While the show features lots of BASIC programming, what it really wants to teach its audience is how computing works in general. The show explains these general principles with analogies. In the second episode, there is an extended discussion of the Jacquard loom, which accomplishes two things. First, it illustrates that computers are not based only on magical technology invented yesterday—some of the foundational principles of computing go back two hundred years and are about as simple as the idea that you can punch holes in card to control a weaving machine. Second, the interlacing of warp and weft threads is used to demonstrate how a binary choice (does the weft thread go above or below the warp thread?) is enough, when repeated over and over, to produce enormous variation. This segues, of course, into a discussion of how information can be stored using binary digits.
Later in the show there is a section about a steam organ that plays music encoded in a long, segmented roll of punched card. This time the analogy is used to explain subroutines in BASIC. Serle and McNaught-Davis lay out the whole roll of punched card on the floor in the studio, then point out the segments where it looks like a refrain is being repeated. McNaught-Davis explains that a subroutine is what you would get if you cut out those repeated segments of card and somehow added an instruction to go back to the original segment that played the refrain for the first time. This is a brilliant explanation and probably one that stuck around in people's minds for a long time afterward.
I've picked out only a few examples, but I think in general the show excels at demystifying computers by explaining the principles that computers rely on to function. The show could instead have focused on teaching BASIC, but it did not. This, it turns out, was very much a conscious choice. In a retrospective written in 1983, John Radcliffe, the executive producer of the Computer Literacy Project, wrote the following:
If computers were going to be as important as we believed, some genuine understanding of this new subject would be important for everyone, almost as important perhaps as the capacity to read and write. Early ideas, both here and in America, had concentrated on programming as the main route to computer literacy. However, as our thinking progressed, although we recognized the value of "hands-on" experience on personal micros, we began to place less emphasis on programming and more on wider understanding, on relating micros to larger machines, encouraging people to gain experience with a range of applications programs and high-level languages, and relating these to experience in the real world of industry and commerce…. Our belief was that once people had grasped these principles, at their simplest, they would be able to move further forward into the subject.
Later, Radcliffe writes, in a similar vein:
There had been much debate about the main explanatory thrust of the series. One school of thought had argued that it was particularly important for the programmes to give advice on the practical details of learning to use a micro. But we had concluded that if the series was to have any sustained educational value, it had to be a way into the real world of computing, through an explanation of computing principles. This would need to be achieved by a combination of studio demonstration on micros, explanation of principles by analogy, and illustration on film of real-life examples of practical applications. Not only micros, but mini computers and mainframes would be shown.
I love this, particularly the part about mini-computers and mainframes. The producers behind The Computer Programme aimed to help Britons get situated: Where had computing been, and where was it going? What can computers do now, and what might they do in the future? Learning some BASIC was part of answering those questions, but knowing BASIC alone was not seen as enough to make someone computer literate.
Computer Literacy TodayIf you google "learn to code," the first result you see is a link to Codecademy's website. If there is a modern equivalent to the Computer Literacy Project, something with the same reach and similar aims, then it is Codecademy.
"Learn to code" is Codecademy's tagline. I don't think I'm the first person to point this out—in fact, I probably read this somewhere and I'm now ripping it off—but there's something revealing about using the word "code" instead of "program." It suggests that the important thing you are learning is how to decode the code, how to look at a screen's worth of Python and not have your eyes glaze over. I can understand why to the average person this seems like the main hurdle to becoming a professional programmer. Professional programmers spend all day looking at computer monitors covered in gobbledygook, so, if I want to become a professional programmer, I better make sure I can decipher the gobbledygook. But dealing with syntax is not the most challenging part of being a programmer, and it quickly becomes almost irrelevant in the face of much bigger obstacles. Also, armed only with knowledge of a programming language's syntax, you may be able to read code but you won't be able to write code to solve a novel problem.
I recently went through Codecademy's "Code Foundations" course, which is the course that the site recommends you take if you are interested in programming (as opposed to web development or data science) and have never done any programming before. There are a few lessons in there about the history of computer science, but they are perfunctory and poorly researched. (Thank heavens for this noble internet vigilante, who pointed out a particularly egregious error.) The main focus of the course is teaching you about the common structural elements of programming languages: variables, functions, control flow, loops. In other words, the course focuses on what you would need to know to start seeing patterns in the gobbledygook.
To be fair to Codecademy, they offer other courses that look meatier. But even courses such as their "Computer Science Path" course focus almost exclusively on programming and concepts that can be represented in programs. One might argue that this is the whole point—Codecademy's main feature is that it gives you little interactive programming lessons with automated feedback. There also just isn't enough room to cover more because there is only so much you can stuff into somebody's brain in a little automated lesson. But the producers at the BBC tasked with kicking off the Computer Literacy Project also had this problem; they recognized that they were limited by their medium and that "the amount of learning that would take place as a result of the television programmes themselves would be limited."8 With similar constraints on the volume of information they could convey, they chose to emphasize general principles over learning BASIC. Couldn't Codecademy replace a lesson or two with an interactive visualization of a Jacquard loom weaving together warp and weft threads?
I'm banging the drum for "general principles" loudly now, so let me just explain what I think they are and why they are important. There's a book by J. Clark Scott about computers called But How Do It Know? The title comes from the anecdote that opens the book. A salesman is explaining to a group of people that a thermos can keep hot food hot and cold food cold. A member of the audience, astounded by this new invention, asks, "But how do it know?" The joke of course is that the thermos is not perceiving the temperature of the food and then making a decision—the thermos is just constructed so that cold food inevitably stays cold and hot food inevitably stays hot. People anthropomorphize computers in the same way, believing that computers are digital brains that somehow "choose" to do one thing or another based on the code they are fed. But learning a few things about how computers work, even at a rudimentary level, takes the homunculus out of the machine. That's why the Jacquard loom is such a good go-to illustration. It may at first seem like an incredible device. It reads punch cards and somehow "knows" to weave the right pattern! The reality is mundane: Each row of holes corresponds to a thread, and where there is a hole in that row the corresponding thread gets lifted. Understanding this may not help you do anything new with computers, but it will give you the confidence that you are not dealing with something magical. We should impart this sense of confidence to beginners as soon as we can.
Alas, it's possible that the real problem is that nobody wants to learn about the Jacquard loom. Judging by how Codecademy emphasizes the professional applications of what it teaches, many people probably start using Codecademy because they believe it will help them "level up" their careers. They believe, not unreasonably, that the primary challenge will be understanding the gobbledygook, so they want to "learn to code." And they want to do it as quickly as possible, in the hour or two they have each night between dinner and collapsing into bed. Codecademy, which after all is a business, gives these people what they are looking for—not some roundabout explanation involving a machine invented in the 18th century.
The Computer Literacy Project, on the other hand, is what a bunch of producers and civil servants at the BBC thought would be the best way to educate the nation about computing. I admit that it is a bit elitist to suggest we should laud this group of people for teaching the masses what they were incapable of seeking out on their own. But I can't help but think they got it right. Lots of people first learned about computing using a BBC Micro, and many of these people went on to become successful software developers or game designers. As I've written before, I suspect learning about computing at a time when computers were relatively simple was a huge advantage. But perhaps another advantage these people had is shows like The Computer Programme, which strove to teach not just programming but also how and why computers can run programs at all. After watching The Computer Programme, you may not understand all the gobbledygook on a computer screen, but you don't really need to because you know that, whatever the "code" looks like, the computer is always doing the same basic thing. After a course or two on Codecademy, you understand some flavors of gobbledygook, but to you a computer is just a magical machine that somehow turns gobbledygook into running software. That isn't computer literacy.
If you enjoyed this post, more like it come out every four weeks! Follow @TwoBitHistory on Twitter or subscribe to the RSS feed to make sure you know when a new post is out.
Previously on TwoBitHistory…
FINALLY some new damn content, amirite?
— TwoBitHistory (@TwoBitHistory) February 1, 2019
Wanted to write an article about how Simula bought us object-oriented programming. It did that, but early Simula also flirted with a different vision for how OOP would work. Wrote about that instead!https://t.co/AYIWRRceI6
-
Robert Albury and David Allen, Microelectronics, report (1979). ↩
-
Gregg Williams, "Microcomputing, British Style", Byte Magazine, 40, January 1983, accessed on March 31, 2019, https://archive.org/stream/byte-magazine-1983-01/1983_01_BYTE_08-01_Looking_Ahead#page/n41/mode/2up. ↩
-
John Radcliffe, "Toward Computer Literacy," Computer Literacy Project Achive, 42, accessed March 31, 2019, https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/media/Towards Computer Literacy.pdf. ↩
-
David Allen, "About the Computer Literacy Project," Computer Literacy Project Archive, accessed March 31, 2019, https://computer-literacy-project.pilots.bbcconnectedstudio.co.uk/history. ↩
-
ibid. ↩
-
Williams, 51. ↩
-
Radcliffe, 11. ↩
-
Radcliffe, 5. ↩
SPECIAL OFFER: Pre-order NOW and receive the copy you ordered when it comes out.http://bit.ly/scarfolkbook

For more information please reread.
Imagine that you are sitting on the grassy bank of a river. Ahead of you, the water flows past swiftly. The afternoon sun has put you in an idle, philosophical mood, and you begin to wonder whether the river in front of you really exists at all. Sure, large volumes of water are going by only a few feet away. But what is this thing that you are calling a "river"? After all, the water you see is here and then gone, to be replaced only by more and different water. It doesn't seem like the word "river" refers to any fixed thing in front of you at all.
In 2009, Rich Hickey, the creator of Clojure, gave an excellent talk about why this philosophical quandary poses a problem for the object-oriented programming paradigm. He argues that we think of an object in a computer program the same way we think of a river—we imagine that the object has a fixed identity, even though many or all of the object's properties will change over time. Doing this is a mistake, because we have no way of distinguishing between an object instance in one state and the same object instance in another state. We have no explicit notion of time in our programs. We just breezily use the same name everywhere and hope that the object is in the state we expect it to be in when we reference it. Inevitably, we write bugs.
The solution, Hickey concludes, is that we ought to model the world not as a collection of mutable objects but a collection of processes acting on immutable data. We should think of each object as a "river" of causally related states. In sum, you should use a functional language like Clojure.
 The author, on a hike, pondering the ontological commitments
The author, on a hike, pondering the ontological commitments
of
object-oriented programming.
Since Hickey gave his talk in 2009, interest in functional programming languages has grown, and functional programming idioms have found their way into the most popular object-oriented languages. Even so, most programmers continue to instantiate objects and mutate them in place every day. And they have been doing it for so long that it is hard to imagine that programming could ever look different.
I wanted to write an article about Simula and imagined that it would mostly be about when and how object-oriented constructs we are familiar with today were added to the language. But I think the more interesting story is about how Simula was originally so unlike modern object-oriented programming languages. This shouldn't be a surprise, because the object-oriented paradigm we know now did not spring into existence fully formed. There were two major versions of Simula: Simula I and Simula 67. Simula 67 brought the world classes, class hierarchies, and virtual methods. But Simula I was a first draft that experimented with other ideas about how data and procedures could be bundled together. The Simula I model is not a functional model like the one Hickey proposes, but it does focus on processes that unfold over time rather than objects with hidden state that interact with each other. Had Simula 67 stuck with more of Simula I's ideas, the object-oriented paradigm we know today might have looked very different indeed—and that contingency should teach us to be wary of assuming that the current paradigm will dominate forever.
Simula 0 Through 67Simula was created by two Norwegians, Kristen Nygaard and Ole-Johan Dahl.
In the late 1950s, Nygaard was employed by the Norwegian Defense Research Establishment (NDRE), a research institute affiliated with the Norwegian military. While there, he developed Monte Carlo simulations used for nuclear reactor design and operations research. These simulations were at first done by hand and then eventually programmed and run on a Ferranti Mercury.1 Nygaard soon found that he wanted a higher-level way to describe these simulations to a computer.
The kind of simulation that Nygaard commonly developed is known as a "discrete event model." The simulation captures how a sequence of events change the state of a system over time—but the important property here is that the simulation can jump from one event to the next, since the events are discrete and nothing changes in the system between events. This kind of modeling, according to a paper that Nygaard and Dahl presented about Simula in 1966, was increasingly being used to analyze "nerve networks, communication systems, traffic flow, production systems, administrative systems, social systems, etc."2 So Nygaard thought that other people might want a higher-level way to describe these simulations too. He began looking for someone that could help him implement what he called his "Simulation Language" or "Monte Carlo Compiler."3
Dahl, who had also been employed by NDRE, where he had worked on language design, came aboard at this point to play Wozniak to Nygaard's Jobs. Over the next year or so, Nygaard and Dahl worked to develop what has been called "Simula 0."4 This early version of the language was going to be merely a modest extension to ALGOL 60, and the plan was to implement it as a preprocessor. The language was then much less abstract than what came later. The primary language constructs were "stations" and "customers." These could be used to model certain discrete event networks; Nygaard and Dahl give an example simulating airport departures.5 But Nygaard and Dahl eventually came up with a more general language construct that could represent both "stations" and "customers" and also model a wider range of simulations. This was the first of two major generalizations that took Simula from being an application-specific ALGOL package to a general-purpose programming language.
In Simula I, there were no "stations" or "customers," but these could be recreated using "processes." A process was a bundle of data attributes associated with a single action known as the process' operating rule. You might think of a process as an object with only a single method, called something like run(). This analogy is imperfect though, because each process' operating rule could be suspended or resumed at any time—the operating rules were a kind of coroutine. A Simula I program would model a system as a set of processes that conceptually all ran in parallel. Only one process could actually be "current" at any time, but once a process suspended itself the next queued process would automatically take over. As the simulation ran, behind the scenes, Simula would keep a timeline of "event notices" that tracked when each process should be resumed. In order to resume a suspended process, Simula needed to keep track of multiple call stacks. This meant that Simula could no longer be an ALGOL preprocessor, because ALGOL had only once call stack. Nygaard and Dahl were committed to writing their own compiler.
In their paper introducing this system, Nygaard and Dahl illustrate its use by implementing a simulation of a factory with a limited number of machines that can serve orders.6 The process here is the order, which starts by looking for an available machine, suspends itself to wait for one if none are available, and then runs to completion once a free machine is found. There is a definition of the order process that is then used to instantiate several different order instances, but no methods are ever called on these instances. The main part of the program just creates the processes and sets them running.
The first Simula I compiler was finished in 1965. The language grew popular at the Norwegian Computer Center, where Nygaard and Dahl had gone to work after leaving NDRE. Implementations of Simula I were made available to UNIVAC users and to Burroughs B5500 users.7 Nygaard and Dahl did a consulting deal with a Swedish company called ASEA that involved using Simula to run job shop simulations. But Nygaard and Dahl soon realized that Simula could be used to write programs that had nothing to do with simulation at all.
Stein Krogdahl, a professor at the University of Oslo that has written about the history of Simula, claims that "the spark that really made the development of a new general-purpose language take off" was a paper called "Record Handling" by the British computer scientist C.A.R. Hoare.8 If you read Hoare's paper now, this is easy to believe. I'm surprised that you don't hear Hoare's name more often when people talk about the history of object-oriented languages. Consider this excerpt from his paper:
The proposal envisages the existence inside the computer during the execution of the program, of an arbitrary number of records, each of which represents some object which is of past, present or future interest to the programmer. The program keeps dynamic control of the number of records in existence, and can create new records or destroy existing ones in accordance with the requirements of the task in hand.
Each record in the computer must belong to one of a limited number of disjoint record classes; the programmer may declare as many record classes as he requires, and he associates with each class an identifier to name it. A record class name may be thought of as a common generic term like "cow," "table," or "house" and the records which belong to these classes represent the individual cows, tables, and houses.
Hoare does not mention subclasses in this particular paper, but Dahl credits him with introducing Nygaard and himself to the concept.9 Nygaard and Dahl had noticed that processes in Simula I often had common elements. Using a superclass to implement those common elements would be convenient. This also raised the possibility that the "process" idea itself could be implemented as a superclass, meaning that not every class had to be a process with a single operating rule. This then was the second great generalization that would make Simula 67 a truly general-purpose programming language. It was such a shift of focus that Nygaard and Dahl briefly considered changing the name of the language so that people would know it was not just for simulations.10 But "Simula" was too much of an established name for them to risk it.
In 1967, Nygaard and Dahl signed a contract with Control Data to implement this new version of Simula, to be known as Simula 67. A conference was held in June, where people from Control Data, the University of Oslo, and the Norwegian Computing Center met with Nygaard and Dahl to establish a specification for this new language. This conference eventually led to a document called the "Simula 67 Common Base Language," which defined the language going forward.
Several different vendors would make Simula 67 compilers. The Association of Simula Users (ASU) was founded and began holding annual conferences. Simula 67 soon had users in more than 23 different countries.11
21st Century SimulaSimula is remembered now because of its influence on the languages that have supplanted it. You would be hard-pressed to find anyone still using Simula to write application programs. But that doesn't mean that Simula is an entirely dead language. You can still compile and run Simula programs on your computer today, thanks to GNU cim.
The cim compiler implements the Simula standard as it was after a revision in 1986. But this is mostly the Simula 67 version of the language. You can write classes, subclass, and virtual methods just as you would have with Simula 67. So you could create a small object-oriented program that looks a lot like something you could easily write in Python or Ruby:
! dogs.sim ;
Begin
Class Dog;
! The cim compiler requires virtual procedures to be fully specified ;
Virtual: Procedure bark Is Procedure bark;;
Begin
Procedure bark;
Begin
OutText("Woof!");
OutImage; ! Outputs a newline ;
End;
End;
Dog Class Chihuahua; ! Chihuahua is "prefixed" by Dog ;
Begin
Procedure bark;
Begin
OutText("Yap yap yap yap yap yap");
OutImage;
End;
End;
Ref (Dog) d;
d :- new Chihuahua; ! :- is the reference assignment operator ;
d.bark;
End;
You would compile and run it as follows:
$ cim dogs.sim Compiling dogs.sim: gcc -g -O2 -c dogs.c gcc -g -O2 -o dogs dogs.o -L/usr/local/lib -lcim $ ./dogs Yap yap yap yap yap yap
(You might notice that cim compiles Simula to C, then hands off to a C compiler.)
This was what object-oriented programming looked like in 1967, and I hope you agree that aside from syntactic differences this is also what object-oriented programming looks like in 2019. So you can see why Simula is considered a historically important language.
But I'm more interested in showing you the process model that was central to Simula I. That process model is still available in Simula 67, but only when you use the Process class and a special Simulation block.
In order to show you how processes work, I've decided to simulate the following scenario. Imagine that there is a village full of villagers next to a river. The river has lots of fish, but between them the villagers only have one fishing rod. The villagers, who have voracious appetites, get hungry every 60 minutes or so. When they get hungry, they have to use the fishing rod to catch a fish. If a villager cannot use the fishing rod because another villager is waiting for it, then the villager queues up to use the fishing rod. If a villager has to wait more than five minutes to catch a fish, then the villager loses health. If a villager loses too much health, then that villager has starved to death.
This is a somewhat strange example and I'm not sure why this is what first came to mind. But there you go. We will represent our villagers as Simula processes and see what happens over a day's worth of simulated time in a village with four villagers.
The full program is available here as a Gist.
The last lines of my output look like the following. Here we are seeing what happens in the last few hours of the day:
1299.45: John is hungry and requests the fishing rod. 1299.45: John is now fishing. 1311.39: John has caught a fish. 1328.96: Betty is hungry and requests the fishing rod. 1328.96: Betty is now fishing. 1331.25: Jane is hungry and requests the fishing rod. 1340.44: Betty has caught a fish. 1340.44: Jane went hungry waiting for the rod. 1340.44: Jane starved to death waiting for the rod. 1369.21: John is hungry and requests the fishing rod. 1369.21: John is now fishing. 1379.33: John has caught a fish. 1409.59: Betty is hungry and requests the fishing rod. 1409.59: Betty is now fishing. 1419.98: Betty has caught a fish. 1427.53: John is hungry and requests the fishing rod. 1427.53: John is now fishing. 1437.52: John has caught a fish.
Poor Jane starved to death. But she lasted longer than Sam, who didn't even make it to 7am. Betty and John sure have it good now that only two of them need the fishing rod.
What I want you to see here is that the main, top-level part of the program does nothing but create the four villager processes and get them going. The processes manipulate the fishing rod object in the same way that we would manipulate an object today. But the main part of the program does not call any methods or modify and properties on the processes. The processes have internal state, but this internal state only gets modified by the process itself.
There are still fields that get mutated in place here, so this style of programming does not directly address the problems that pure functional programming would solve. But as Krogdahl observes, "this mechanism invites the programmer of a simulation to model the underlying system as a set of processes, each describing some natural sequence of events in that system."12 Rather than thinking primarily in terms of nouns or actors—objects that do things to other objects—here we are thinking of ongoing processes. The benefit is that we can hand overall control of our program off to Simula's event notice system, which Krogdahl calls a "time manager." So even though we are still mutating processes in place, no process makes any assumptions about the state of another process. Each process interacts with other processes only indirectly.
It's not obvious how this pattern could be used to build, say, a compiler or an HTTP server. (On the other hand, if you've ever programmed games in the Unity game engine, this should look familiar.) I also admit that even though we have a "time manager" now, this may not have been exactly what Hickey meant when he said that we need an explicit notion of time in our programs. (I think he'd want something like the superscript notation that Ada Lovelace used to distinguish between the different values a variable assumes through time.) All the same, I think it's really interesting that right there at the beginning of object-oriented programming we can find a style of programming that is not all like the object-oriented programming we are used to. We might take it for granted that object-oriented programming simply works one way—that a program is just a long list of the things that certain objects do to other objects in the exact order that they do them. Simula I's process system shows that there are other approaches. Functional languages are probably a better thought-out alternative, but Simula I reminds us that the very notion of alternatives to modern object-oriented programming should come as no surprise.
If you enjoyed this post, more like it come out every four weeks! Follow @TwoBitHistory on Twitter or subscribe to the RSS feed to make sure you know when a new post is out.
Previously on TwoBitHistory…
Hey everyone! I sadly haven't had time to do any new writing but I've just put up an updated version of my history of RSS. This version incorporates interviews I've since done with some of the key people behind RSS like Ramanathan Guha and Dan Libby.https://t.co/WYPhvpTGqB
— TwoBitHistory (@TwoBitHistory) December 18, 2018
-
Jan Rune Holmevik, "The History of Simula," accessed January 31, 2019, http://campus.hesge.ch/daehne/2004-2005/langages/simula.htm. ↩
-
Ole-Johan Dahl and Kristen Nygaard, "SIMULA—An ALGOL-Based Simulation Langauge," Communications of the ACM 9, no. 9 (September 1966): 671, accessed January 31, 2019, http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.95.384&rep=rep1&type=pdf. ↩
-
Stein Krogdahl, "The Birth of Simula," 2, accessed January 31, 2019, http://heim.ifi.uio.no/~steinkr/papers/HiNC1-webversion-simula.pdf. ↩
-
ibid. ↩
-
Ole-Johan Dahl and Kristen Nygaard, "The Development of the Simula Languages," ACM SIGPLAN Notices 13, no. 8 (August 1978): 248, accessed January 31, 2019, https://hannemyr.com/cache/knojd_acm78.pdf. ↩
-
Dahl and Nygaard (1966), 676. ↩
-
Dahl and Nygaard (1978), 257. ↩
-
Krogdahl, 3. ↩
-
Ole-Johan Dahl, "The Birth of Object-Orientation: The Simula Languages," 3, accessed January 31, 2019, http://www.olejohandahl.info/old/birth-of-oo.pdf. ↩
-
Dahl and Nygaard (1978), 265. ↩
-
Holmevik. ↩
-
Krogdahl, 4. ↩
Originally shared by Shava Nerad
David Sirota's war against media critical thinking
Bernie, Beto, and the Streisand Effect
If there's anything I despise more than an attack on the electorate from foreign influence, from right wing media, from corporate mainstream media, it's a left media figure using everything we know about propaganda and media criticism, distortion and influence, to punch left.
David Sirota was Bernie Sanders' first office lead in the 90s, when Vermont sent Bernie to DC to mess with Speaker Newt Gingrich's head. It was David's first big break in DC from the looks of his VC, and I'm sure that the relationship means a lot.
Right up to New Hampshire, I was pretty gleeful about Sanders' run. I was really troubled when he hired Tad Devine and displaced his Vermont staff. I defended Bernie with teeth bared when his staff lifted the Clinton campaign annotated voter file (yes, in the modern way of blurring social engineering and hacking, you can call that hacking) and the DNC threatened -- quite justifiably -- to shut their asses down.
Later I ended up regretting it as the campaign grew more and more anti-community. I imagined another Dean campaign -- bottom up, participatory, integrated with the party to the point of taking over the counties, breathing a via positiva of lifeblood into the progressives -- to use an abused term? Hope.
What we got was Bernie Bros that presaged #metoo politics, and a level of hostility and lack of civic and political understanding of how political insurgencies work in a two party system that was crippling, all around.
Well, oops, it's happening again.
This time, instead of Tad, we've got David Sirota as our snake in the garden, the designated whisperer of insinuations to drip poison into ears and divide.
He's fun. Let me take this apart for you. I'm going to write this up as a reference for fellow journalists. It's going to be tl;dr, long, opinionated but well documented, and I'm going to add to it over the course of days.
===
Who the hell is Beto O'Rourke?
I'd heard the name. There's even some lunatic with Mass plates on my street here in Cambridge who has a Beto bumper sticker. Early adopter, I guess.
But as I've written here I'm not favoring anyone at this point in 2020. It's too early.
Still, the first week in December, I saw retweets of Sirota "exposing" Beto for various insinuated sins against progressive politics. The major charges have been that he has:
o - voted "with the GOP" 167 times.
o - accepted at least one maxed out donation from a CEO of an oil/gas corporation
Now, I'm going to go through and take these apart in depth with full footnotes, but this preamble is just to explain why this rang such an off note with me.
Voting "with the GOP" means you are not voting party line Democrat. There are lots of reasons for this. One of the most common in recent years is that you live in a rural state. Yo? This is part of how we got the Cheeto.
Plus, Politico has reported that Sanders votes with the Dems about 95% of the time. He has been in office a very long time. I don't have a full tally, but David has included procedural votes in his 167 that Beto's joined the evil pachyderms. How many hundreds or thousands more votes has our independent from Vermont registered since the 90s?
David illustrated Beto's receiving "oil money" from the CEO of a small business in Texas. Right SIC code, $2700 donation. Instructed people to decide what they thought of it -- after framing that we can't afford more money in politics supporting global warming that is going to kill us all. Nice.
Remember, this stuff pretty much starts with Stalin, and he was a lefty. We've all studied him. ;)
The example he uses is a guy who is a long time Democratic donor, the widower of a Human Rights Campaign activist. The two men were married in the Unitarian Universalist church. Now he's raising two kids as a single dad.
I honestly doubt he was buying Beto's vote for big oil.
Beto's a Texas politician. Over 375,000 people in Texas fall directly under the oil/gas SIC code, and more -- likely millions -- in the many industries that support and profit from the extraction and refining.
What is Bernie afraid of?
I'm not the only one -- probably not even the only one who didn't know crap about Beto -- for whom David Sirota is managing to bring a spotlight to the Texan and shade to the Vermonter with his tactics.
Streisand Effect.
https://nymclub.net/photos/mosqueeto/album/50d4bb8cdc76f81c887b296fdbabc64d6a203552bc8122e7805e6326fb5e7ae0
https://www.theonion.com/thousands-of-drunk-revelers-dressed-as-jesus-descend-on-1831048100

Best viewed large.
This is the scariest article I've read in a really long, scary, time.
"(It's easy to read that number as 60 percent less, but it's sixtyfold less: Where once he caught 473 milligrams of bugs, Lister was now catching just eight milligrams.) "It was, you know, devastating," Lister told me. But even scarier were the ways the losses were already moving through the ecosystem, with serious declines in the numbers of lizards, birds and frogs. The paper reported "a bottom-up trophic cascade and consequent collapse of the forest food web." Lister's inbox quickly filled with messages from other scientists, especially people who study soil invertebrates, telling him they were seeing similarly frightening declines. Even after his dire findings, Lister found the losses shocking: "I didn't even know about the earthworm crisis!"
https://www.nytimes.com/2018/11/27/magazine/insect-apocalypse.html

A bug.

Fuck Bernie Sanders, his momma, and the white horse he rode his racist ass in on. Those white voters don't exist.
https://www.thedailybeast.com/bernie-sanders-on-andrew-gillium-and-stacey-abrams-many-whites-uncomfortable-voting-for-black-candidates

Originally shared by Darrin C
There's currently an organized bot effort to discourage people from voting. Among their "arguments" is that voting machines are all "rigged".
Hogwash.
I'm one of the computer scientists who discovered these voting system problems. And I vote, because it matters. So should you.

Purgatory.
How I set up a hubzilla hub on Digital Ocean.
Motivation: Hubzilla is the most interesting of the possible G+ alternatives I've looked at so far. It's most important feature, from my perspective, is that your identity isn't tied to a particular hub. Identity portability is built in. You can move your activity to any hubzilla hub -- one you run yourself, or one run by a mega-corp. You can run your own hub and participate fully in the network.
But hubzilla is new and perhaps a bit hard to grasp -- new terms, new concepts. I decided to set up a hub.
Requirements: Some proficiency in linux system administration at the command line. Financial committment of ~ $100/year. Time committment of ~ 8-24 hours to set up, and then ongoing time TBD. Some expertise in using Google...
0) You need a domain name for your hub (eg: "nymclub.net"). In my case I had registered the name long ago at godaddy.com.
1) Set up a DO account (at https://www.digitalocean.com/) and create a
droplet. A minimal droplet costs $5/month. Select ubuntu 18.04 as the OS.
The name of the droplet on creation should be the domain name above (eg: "nymclub.net"), and not the name they provide by default. Secure your droplet by following the excellent clear instructions at
https://www.digitalocean.com/community/tutorials/initial-server-setup-with-ubuntu-18-04
[In general, DO has really great tutorials.]
[Note: I don't work for DO, but I am a satisfied customer.]
The droplet will have an IP address that it will keep as long as it is alive.
Note it.
2) Set up DNS using the above IP address. You can use DO servers, following the documentation at:
https://www.digitalocean.com/docs/networking/dns/
In my case I have my own dns servers, so I used them.
Be sure you can log into your droplet remotely, by name, not IP address.
3) Install the LAMP stack (Linux, Apache, Mysql, PHP):
https://www.digitalocean.com/community/tutorials/how-to-install-linux-apache-mysql-php-lamp-stack-ubuntu-18-04
(There is also a DO "one click application" that gives you a server with a
LAMP stack. I don't know anything about it, other than it exists.)
Note: I used the MariaDB, a free plug in replacement for MySql, with
$ sudo apt install mariadb-server
if I recall correctly. It may be the default already.
Verify that you can see the apache start page from your browser.
4) Hubzilla requires a mail server that can send mail to confirm accounts. I just installed postfix as an "internet server":
$ sudo apt update
$ sudo apt install postfix
[I think this will take further work on my part -- I got it to the point where it could send the confirmation emails, and didn't do any more email
configuration. Email is, in general, a pain.]
I also installed an email client so I could send test messages:
$ sudo apt install mutt
5) Hubzilla also highly recommends using SSL/TLS for your web server. I used the "Let's Encrypt" certificate authority, and "certbot". See
https://certbot.eff.org/lets-encrypt/ubuntubionic-apache for information.
https://nymclub.net worked first try.
6) Install hubzilla. The instructions at
https://project.hubzilla.org/help/en/admin/administrator_guide are perhaps too concise, but they are complete. I followed them slavishly. Google will reveal several other tutorials:
https://www.howtoforge.com/tutorial/how-to-install-hubzilla-on-ubuntu/ --
doesn't include TLS, and uses an apache virtual host.
https://hubzilla.rocks/page/tobias/tutorial_install_hubzilla_in_7_easy_steps
https://websiteforstudents.com/install-hubzilla-platform-on-ubuntu-16-04-18-04-with-apache2-mariadb-and-php-7-2/
Might not be a bad idea to read through them.
Once you have unpacked the software you can access the site and use the software itself to guide you through the installation. Specifically, I used the recommended "git clone" to get hubzilla in the default root directory of the web site, /var/www/html, then browsed to https://nymclub.net. The web site at this point shows the status of the installation -- what is missing and what needs to be configured. At the command line, then, I manually installed the needed requirements -- php-zip, mbstring, php-xml, and several others were needed. Sometimes it took a bit of head-scratching to figure out the correct package name to install. You can use "dpkg
$ sudo dpkg -S php-zip
You may also need to edit the /etc/php/7.2/apache2/php.ini file to be sure that all the indicated packages have been enabled, change upload limits, and so on.
Important: in order to get changes in the php configuration to be reflected in the web page you must first RESTART THE WEB SERVER:
$ sudo service apache2 restart
Took me a while to remember that...
Be sure you have changed "AllowOverride None" to "AllowOverride All" in the necessary places in the /etc/apache2/apache2.conf file:
Options Indexes FollowSymLinks
AllowOverride All
Require all granted
Set up the database and the database user as described in the documentation.
After all this you should have an installation.
Finally, you need to create the first user, using the same email address
that you provided during installation. This user is the administrator.
7) Now it is "administration" of hubzilla, not "installation." I'm learning
this at the moment, so just a couple of quick notes.
Initially, the navigation bar at the top of the page is pretty empty. In the
upper right of the "Channel Home" page is "New Member Links". A "Missing Features?" group is at the bottom of the list, with "Install more apps" and "Pin apps...".
"Install more apps": click on this link to get a list of apps to install.
"Pin apps to navigation bar": Click on that link, and you will see a bunch
of apps, along with a pushpin icon. Click the icon, and the app will appear in the nav bar. (Requires a reload).
I think you need apps to do much of anything, so the above two steps are pretty important.
Anyway, for ~$100/year you can have an awesome social network with complete control over your own data. Not a bad deal.
Installation is a bit complex -- hubzilla itself is really pretty straightforward to install, but the infrastructure: a virtual host, a domain name with function dns, a web server with a LAMP stack, a let's encrypt certificate, email -- a bunch of fiddly details that need to be set up. I haven't done this stuff for a while, and there were small snags that I wouldn't have hit in my younger days...
Of course, people who live on their phones may not have that luxury, but I surf mainly from my desktop.

Murder in the garden....
Originally shared by Sawanya Prittipongpunt
Big-eyed bugs - Hemiptera (Geocoris) : มวนตาโต
ello.co: mosqueeto
pluspora.com: mosqueeto
diasp.org: mosqueeto
cake.co: mosqueeto
mastodon.social: mosqueeto
photog.social: mosqueeto
reddit.com: mosqueeto
tumblr.com: mosqueeto
social.isurf.ca: mosqueeto
C32767.blogger.com
https://medium.com/we-distribute/a-quick-guide-to-the-free-network-c069309f334
What kind of an organizational infrastructure is appropriate to support a long term replacement for gplus? For example, I could personally support a diaspora instance with perhaps a few dozen active users, using my personal funds and time. But that doesn't scale. Many of the efforts so far seem to be on an "if we build it they will come and the organizational infrastructure will evolve later" model.
Some kind of legal entity (corporation/foundation/trust) with an unlimited potential lifetime and a funding mechanism seems required. A governance mechanism to deal with bad actors, hopefully something other than autocracy, would be nice.
In a federated case this consideration applies to each instance individually, and to the overall software base. How do the various alternatives compare in this matter?
https://www.dailydot.com/debug/facebook-alternatives/
https://www.theguardian.com/technology/2018/mar/31/youve-decided-to-delete-facebook-but-what-will-you-replace-it-with
https://fossbytes.com/best-facebook-alternatives/
https://eluxemagazine.com/magazine/alternative-social-media-sites/
Google search on "alternative social media":
https://www.cnet.com/how-to/social-media-alternatives-to-facebook/
https://www.1and1.com/digitalguide/online-marketing/social-media/the-best-facebook-alternatives/
Diaspora, ello, and tumblr seem somewhat viable.