As it stands right now, major news organizations — in league with compliant politicians around the world — seem poised to use the power of their national governments to take actions that could absolutely destroy the essentially open Web, as we’ve known it since Sir Tim Berners-Lee created the first operational web server and client browser at CERN in 1990.
Australia — home of the right-wing Rupert Murdoch empire — is in the lead of pushing this nightmarish travesty, but other countries around the world are lining up to join in swinging wrecking balls at Web users worldwide.
Large Internet firms like Facebook and Google, feeling pressure to protect their income streams more than to protect their users, are taking varying approaches toward this situation, but the end result will likely be the same in any case — users get the shaft.
The underlying problem is that news organizations are now demanding to be paid by firms like Google and Facebook merely for being linked from them. The implications of this should be obvious — it creates the slippery slope where more and more sites of all sorts around the world would demand to be paid for links, with the result that the largest, richest Internet firms would likely be the last ones standing, and competition (along with choices available to users) would wither away.
The current situation is still in considerable flux — seemingly changing almost hour by hour — but the trend lines are clear. Google had originally taken a strong stance against this model, rightly pointing out how it could wreck the entire concept of open linking across the Web, the Web’s very foundation! But at the last minute, it seems that Google lost its backbone, and has been announcing payoff deals to Murdoch and others, which of course will just encourage more such demands. At the moment Facebook has taken the opposite approach, and has literally cut off news from their Australian users. The negative collateral effects that this move has created make it unlikely that this can be a long-term action.
But what we’re really seeing from Facebook and Google (and other large Internet firms who are likely to be joining their ranks in this respect) — despite their differing approaches at the moment — is essentially their floundering around in a kind of desperation. They don’t really want (and/or don’t know how) to address the vast damage that will be done to the overall Web by their actions, beyond their own individual ecosystems. From a profit center standpoint this arguably makes sense, but from the standpoint of ordinary users worldwide it does not.
To use the vernacular, users are being royally screwed, and that screwing has only just begun.
Some observers of how the news organizations and their government sycophants are pushing their demands have called these actions blackmail. There is one universal rule when dealing with blackmailers — no matter how much you pay them, they’ll always come back demanding more. In the case of the news link wars, the end result if the current path is continued, will be their demands for the entire Web — users be damned.
–Lauren–
Claims of “cancel culture” seems to be everywhere these days. Almost every day, we seem to hear somebody complaining that they have been “canceled” from social media, and pretty much inevitably there is an accompanying claim of politically biased motives for the action.
The term “cancel culture” itself appears to have been pretty much unknown until several years ago, and seems to have morphed from the term “call-out culture” — which ironically is generally concerned with someone getting more publicity than they desire, rather than less.
Be that as it may, cancel culture complaints — the lions’ share of which emanate from the political right wing — are now routinely used to lambaste social media and other Internet firms, to assert that their actions are based on political statements with which the firms do not agree and (according to these accusations) seek to suppress.
However, even a casual inspection of these claims suggest that the actual issues in play are hate speech, violent speech, and dangerous misinformation and disinformation — not political viewpoints, and formal studies reinforce this observation, e.g. False Accusation: The Unfounded Claim that Social Media Companies Censor Conservatives.
Putting aside for now the fact that the First Amendment does not apply to other than government actions against speech, even a cursory examination of the data reveals — confirmed by more rigorous analysis — not only that right-wing entities are overwhelmingly the source of most associated dangerous speech (though they are by no means the only source, there are sources on the left as well), but conservatives overall still have prominent visibility on social media platforms, dramatically calling into question the claims of “free speech” violations overall.
Inexorably intertwined with this are various loud, misguided, and dangerous demands for changes to (and in some cases total repeal of) Communications Decency Act Section 230, the key legislation that makes all forms of Internet UGC — User Generated Content — practical in the first place.
And here we see pretty much equally unsound proposals (largely completely conflicting with each other) from both sides of the political spectrum, often apparently based on political motives and/or a dramatic ignorance of the negative collateral damage that would be done to ordinary users if such proposals were enacted.
The draconian penalties associated with various of these proposals — aimed at Internet firms — would almost inevitably lead not to the actually desired goals of the right or left, but rather to the crushing of ordinary Internet users, by vastly reducing (or even eliminating entirely) the amount of their content on these platforms — that is, videos they create, comments, discussion forms, and everything else users want to share with others.
The practical effect of these proposals would be not to create more free speech or simply reduce hate and violent speech, misinformation and disinformation, but to make it impractical for Internet platforms to support user content — which is vast in scale beyond the imagination of most persons — in anything like the ways it is supported today. The risks would just be too enormous, and methodologies to meet the new demanded standards — even if we assume the future deployment of advanced AI systems and vast new armies of proactive moderators — do not exist and likely could never exist in a practical and affordable manner.
This is truly one of those “be careful what you wish for” moments, like asking the newly-released genie to “fix social media” and with a wave of his hand he eliminates the ability of anyone in the public — prominent or not, on the right or the left — to share their views or other content.
So as we see, complaints about social media are being driven largely by highly political arguments, but in reality invoke enormously complex technical challenges at gigantic scales — many of which we don’t even fundamentally understand given the toxic political culture of today.
As much as nobody would likely argue that Section 230 is perfect, I have yet to see any realistic proposals to change it that would not make matters far worse — especially for ordinary users who largely don’t understand how much they have to lose in these battles.
Like democracy itself, which has been referred to as “the worst possible system of governance, except for all the others” — buying into the big lie of cancel culture and demands to alter Section 230 is wrong for the Internet and would be terrible for its users.
–Lauren–
I increasingly suspect that the days of large-scale public distribution of unmoderated UGC (User Generated Content) on the Internet may shortly begin drawing to a close in significant ways. The most likely path leading to this over time will be a combination of steps taken independently by social media firms and future legislative mandates.
Such moderation at scale may follow the model of AI-based first-level filtering, followed by layers of human moderators. It seems unlikely that today’s scale of postings could continue under such a moderation model, but future technological developments may well turn out to be highly capable in this realm.
Back in 1985 when I launched my “Stargate” experiment to broadcast Usenet Netnews over the broadcast television vertical blanking interval of national “Superstation WTBS,” I decided that the project would only carry moderated Usenet newsgroups. Even more than 35 years ago, I was concerned about some of the behavior and content already beginning to become common on Usenet. My main related concerns back then did not involve hate speech or violent speech — which were not significant problems on the Net at that point — but human nature being what it is I felt that the situation was likely to get much worse rather than better.
What I had largely forgotten in the decades since then though, until I did a Google search on the topic today (a great deal of original or later information on Stargate is still online, including various of my relevant messages in very early mailing list archives that will likely long outlive me), is the level of animosity about that decision that I received at the time. My determination for Stargate to only carry moderated groups triggered cries of “censorship,” but I did not feel that responsible moderation equated with censorship — and that is still my view today.
And now, all these many years later, it’s clear that we’ve made no real progress in these regards. In fact, the associated issues of abuse of unmoderated content in hateful and dangerous ways makes the content problems that I was mostly concerned about back then seem like a soap bubble popping, compared with a nuclear bomb detonating now.
We must solve this. We must begin serious and coordinated work in this vein immediately. And my extremely strong preference is that we deal with these issues together as firms, organizations, customers, and users — rather than depend on government actions that, if history is any guide, will likely do enormous negative collateral damage.
Time is of the essence.
–Lauren–
The post below was originally published on 10 August 2019. In light of recent events, particularly the storming of the United States Capital by a violent mob — resulting in five deaths — and subsequent actions by major social media firms relating to the exiting President Donald Trump (terms of service enforcement actions by these firms that I do endorse under these extraordinary circumstances), I feel that the original post is again especially relevant. While the threats of moves by the Trump administration against CDA Section 230 are now moot, it is clear that 230 will be a central focus of Congress going forward, and it’s crucial that we all understand the risks of tampering with this key legislation that is foundational to the availability of responsible speech and content on the Internet. –Lauren–
– – – – – – – – – –
The Right’s (and Left’s) Insane Internet Content Power Grab
(10 August 2019)
Rumors are circulating widely — and some news sources claim to have seen actual drafts — of a possible Trump administration executive order aimed at giving the government control over content at large social media and other major Internet platforms.
This effort is based on one of the biggest lies of our age — the continuing claims mostly from the conservative right (but also from some elements of the liberal left) that these firms are using politically biased decisions to determine which content is inappropriate for their platforms. That lie is largely based on the false premise that it's impossible for employees of these firms to separate their personal political beliefs from content management decisions.
In fact, there is no evidence of political bias in these decisions at these firms. It is completely appropriate for these firms to remove hate speech and related attacks from their platforms — most of which does come from the right (though not exclusively so). Nazis, KKK, and a whole array of racist, antisemitic, anti-Muslim, misogynistic, and other violent hate groups are disproportionately creatures of the political right wing.
So it is understandable that hate speech and related content takedowns would largely affect the right — because they're the primary source of these postings and associated materials.
At the scales that these firms operate, no decision-making ecosystem can be 100% accurate, and so errors will occur. But that does not change the underlying reality that the "political bias" arguments are false.
The rumored draft Trump executive order would apparently give the FCC and FTC powers to determine if these firms were engaging in "inappropriate censorship" — the primary implied threat appears to be future changes to Section 230 of the Communications Decency Act, which broadly protects these (and other) firms and individuals from liability for materials that other parties post to their sites. In fact, 230 is effectively what makes social media possible in the first place, since without it the liability risks of allowing users to post anything publicly would almost certainly be overwhelming.
But wait, it gets worse!
At the same time that these political forces are making the false claims that content is taken down inappropriately from these sites for political purposes, governments and politicians are also demanding — especially in the wake of recent mass shootings — that these firms immediately take down an array of violent postings and similar content. The reality that (for example) such materials may be posted only minutes before shootings occur, and may be widely re-uploaded by other users in an array of formats after the fact, doesn't faze the politicians and others making these demands, who apparently either don't understand the enormous scale on which these firms operate, or simply don't care about such truths when they get in the way of politicians' political pandering.
The upshot of all this is an insane situation — demands that offending material be taken down almost instantly, but also demands that no material be taken down inappropriately. Even with the best of AI algorithms and a vast human monitoring workforce, these dual demands are in fundamental conflict. Individually, neither are practical. Taken together, they are utterly impossible.
Of course, we know what's actually going on. Many politicians on both the right and left are desperate to micromanage the Net, to control it for their own political and personal purposes. For them, it's not actually about protecting users, it's mostly about protecting themselves.
Here in the U.S., the First Amendment guarantees that any efforts like Trump's will trigger an orgy of court battles. For Trump himself, this probably doesn't matter too much — he likely doesn't really care how these battles turn out, so long as he's managed to score points with his base along the way.
But the broader risks of such strategies attacking the Internet are enormously dangerous, and Republicans who might smile today about such efforts would do well to imagine similar powers in the hands of a future Democratic administration.
Such governmental powers over Internet content are far too dangerous to be permitted to the administrations of any party. They are anathema to the very principles that make the Internet great. They must not be permitted to take root under any circumstances.
-Lauren-
CSS is about styling boxes. In fact, the whole web is made of boxes, from the browser viewport to elements on a page. But every once in a while a new feature comes along that makes us rethink our design approach.
Round displays, for example, make it fun to play with circular clip areas. Mobile screen notches and virtual keyboards offer challenges to best organize content that stays clear of them. And dual screen or foldable devices make us rethink how to best use available space in a number of different device postures.
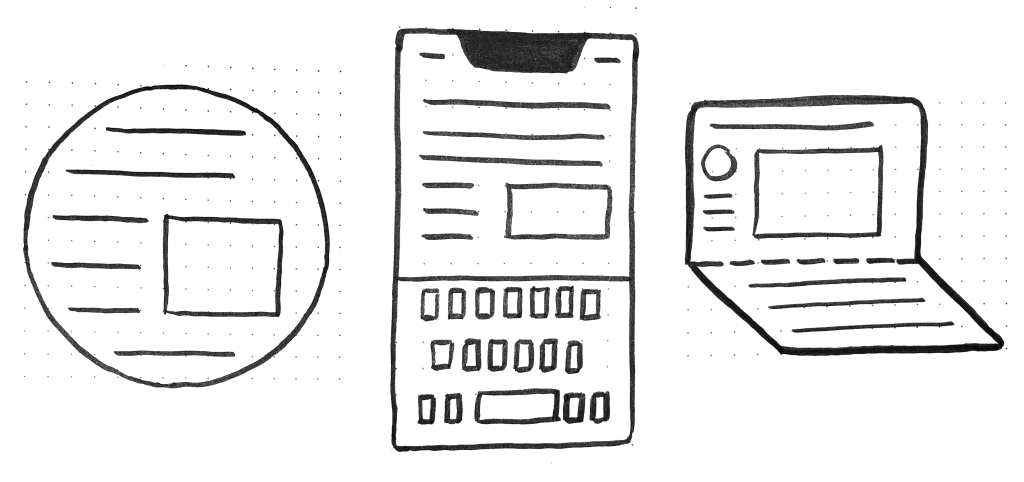 Sketches of a round display, a common rectangular mobile display, and a device with a foldable display.
Sketches of a round display, a common rectangular mobile display, and a device with a foldable display.
These recent evolutions of the web platform made it both more challenging and more interesting to design products. They're great opportunities for us to break out of our rectangular boxes.
I'd like to talk about a new feature similar to the above: the Window Controls Overlay for Progressive Web Apps (PWAs).
Progressive Web Apps are blurring the lines between apps and websites. They combine the best of both worlds. On one hand, they're stable, linkable, searchable, and responsive just like websites. On the other hand, they provide additional powerful capabilities, work offline, and read files just like native apps.
As a design surface, PWAs are really interesting because they challenge us to think about what mixing web and device-native user interfaces can be. On desktop devices in particular, we have more than 40 years of history telling us what applications should look like, and it can be hard to break out of this mental model.
At the end of the day though, PWAs on desktop are constrained to the window they appear in: a rectangle with a title bar at the top.
Here's what a typical desktop PWA app looks like:
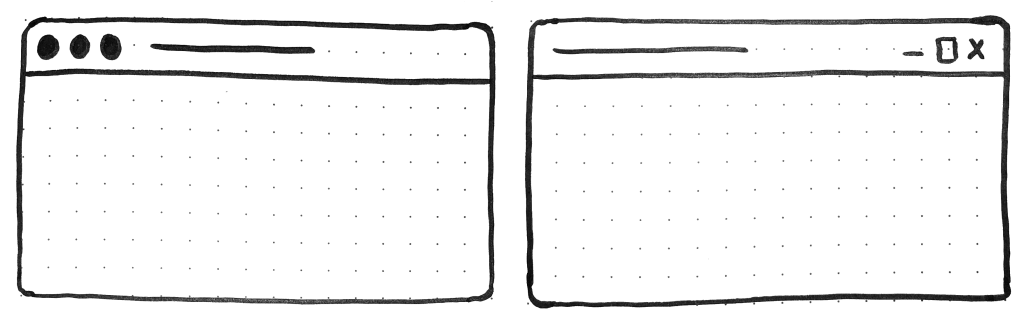 Sketches of two rectangular user interfaces representing the desktop Progressive Web App status quo on the macOS and Windows operating systems, respectively.
Sketches of two rectangular user interfaces representing the desktop Progressive Web App status quo on the macOS and Windows operating systems, respectively.
Sure, as the author of a PWA, you get to choose the color of the title bar (using the Web Application Manifest theme_color property), but that's about it.
What if we could think outside this box, and reclaim the real estate of the app's entire window? Doing so would give us a chance to make our apps more beautiful and feel more integrated in the operating system.
This is exactly what the Window Controls Overlay offers. This new PWA functionality makes it possible to take advantage of the full surface area of the app, including where the title bar normally appears.
About the title bar and window controlsLet's start with an explanation of what the title bar and window controls are.
The title bar is the area displayed at the top of an app window, which usually contains the app's name. Window controls are the affordances, or buttons, that make it possible to minimize, maximize, or close the app's window, and are also displayed at the top.
 A sketch of a rectangular application user interface highlighting the title bar area and window control buttons.
A sketch of a rectangular application user interface highlighting the title bar area and window control buttons.
Window Controls Overlay removes the physical constraint of the title bar and window controls areas. It frees up the full height of the app window, enabling the title bar and window control buttons to be overlaid on top of the application's web content.
 A sketch of a rectangular application user interface using Window Controls Overlay. The title bar and window controls are no longer in an area separated from the app's content.
A sketch of a rectangular application user interface using Window Controls Overlay. The title bar and window controls are no longer in an area separated from the app's content.
If you are reading this article on a desktop computer, take a quick look at other apps. Chances are they're already doing something similar to this. In fact, the very web browser you are using to read this uses the top area to display tabs.
 A screenshot of the top area of a browser's user interface showing a group of tabs that share the same horizontal space as the app window controls.
A screenshot of the top area of a browser's user interface showing a group of tabs that share the same horizontal space as the app window controls.
Spotify displays album artwork all the way to the top edge of the application window.
 A screenshot of an album in Spotify's desktop application. Album artwork spans the entire width of the main content area, all the way to the top and right edges of the window, and the right edge of the main navigation area on the left side. The application and album navigation controls are overlaid directly on top of the album artwork.
A screenshot of an album in Spotify's desktop application. Album artwork spans the entire width of the main content area, all the way to the top and right edges of the window, and the right edge of the main navigation area on the left side. The application and album navigation controls are overlaid directly on top of the album artwork.
Microsoft Word uses the available title bar space to display the auto-save and search functionalities, and more.
 A screenshot of Microsoft Word's toolbar interface. Document file information, search, and other functionality appear at the top of the window, sharing the same horizontal space as the app's window controls.
A screenshot of Microsoft Word's toolbar interface. Document file information, search, and other functionality appear at the top of the window, sharing the same horizontal space as the app's window controls.
The whole point of this feature is to allow you to make use of this space with your own content while providing a way to account for the window control buttons. And it enables you to offer this modified experience on a range of platforms while not adversely affecting the experience on browsers or devices that don't support Window Controls Overlay. After all, PWAs are all about progressive enhancement, so this feature is a chance to enhance your app to use this extra space when it's available.
Let's use the featureFor the rest of this article, we'll be working on a demo app to learn more about using the feature.
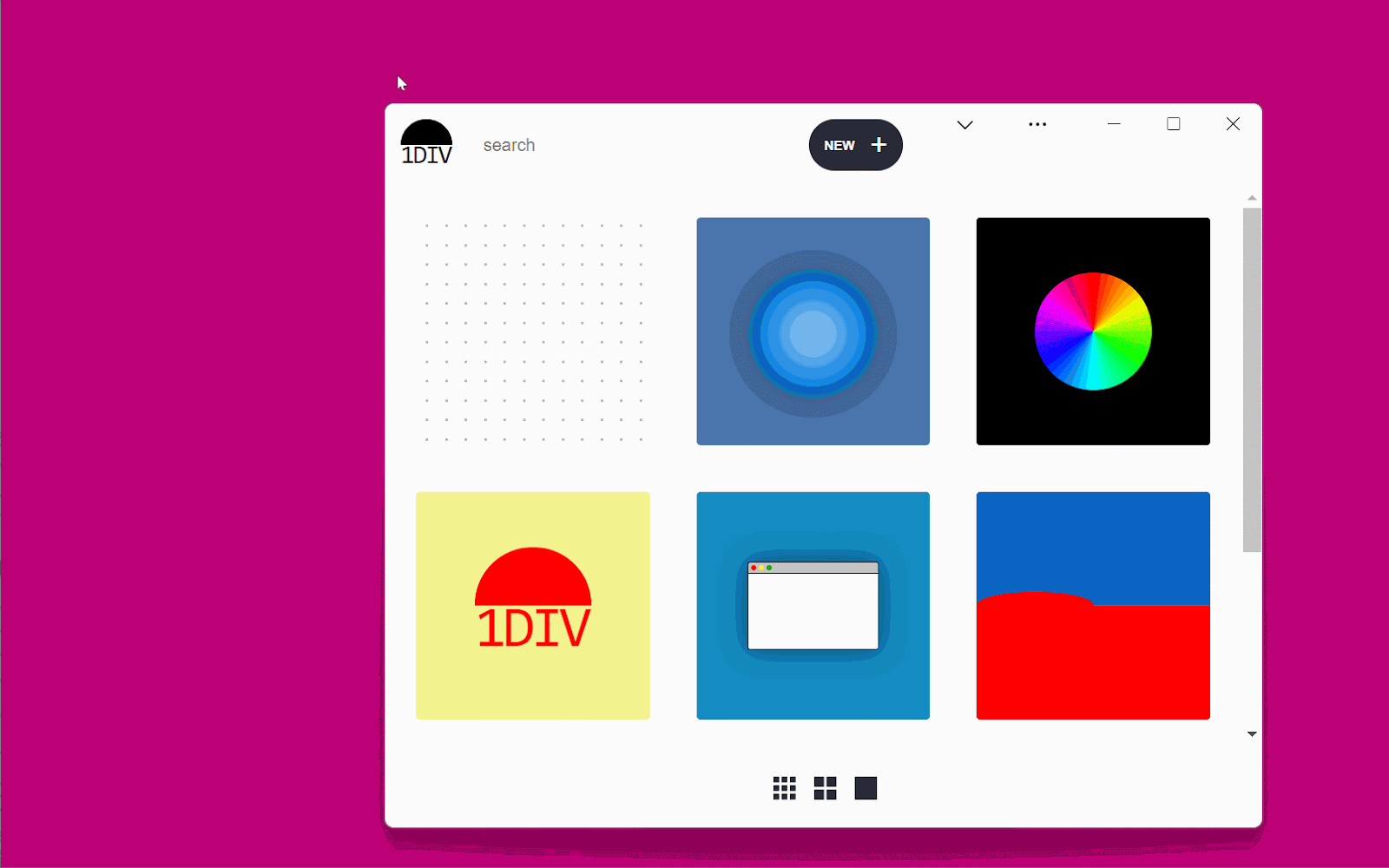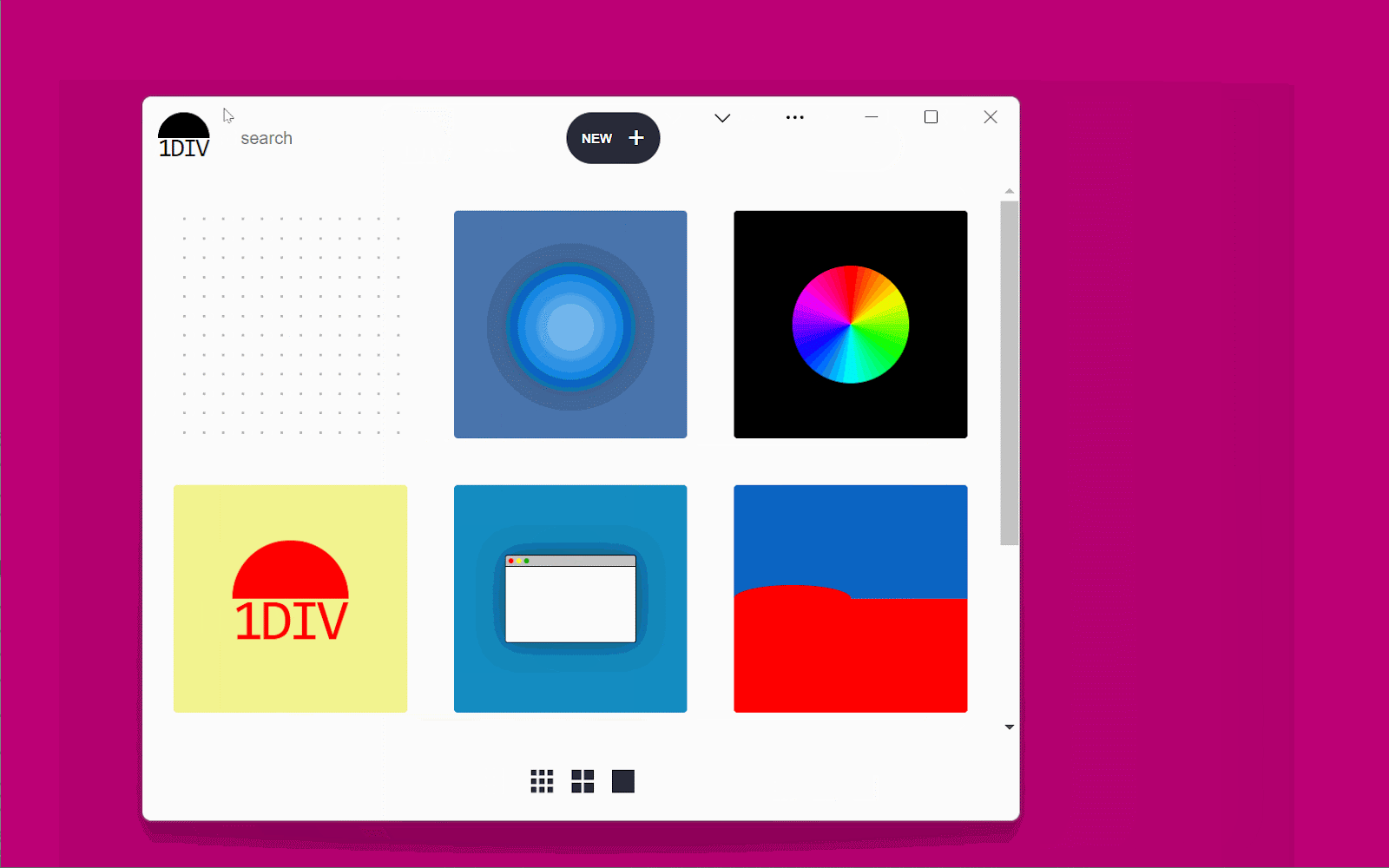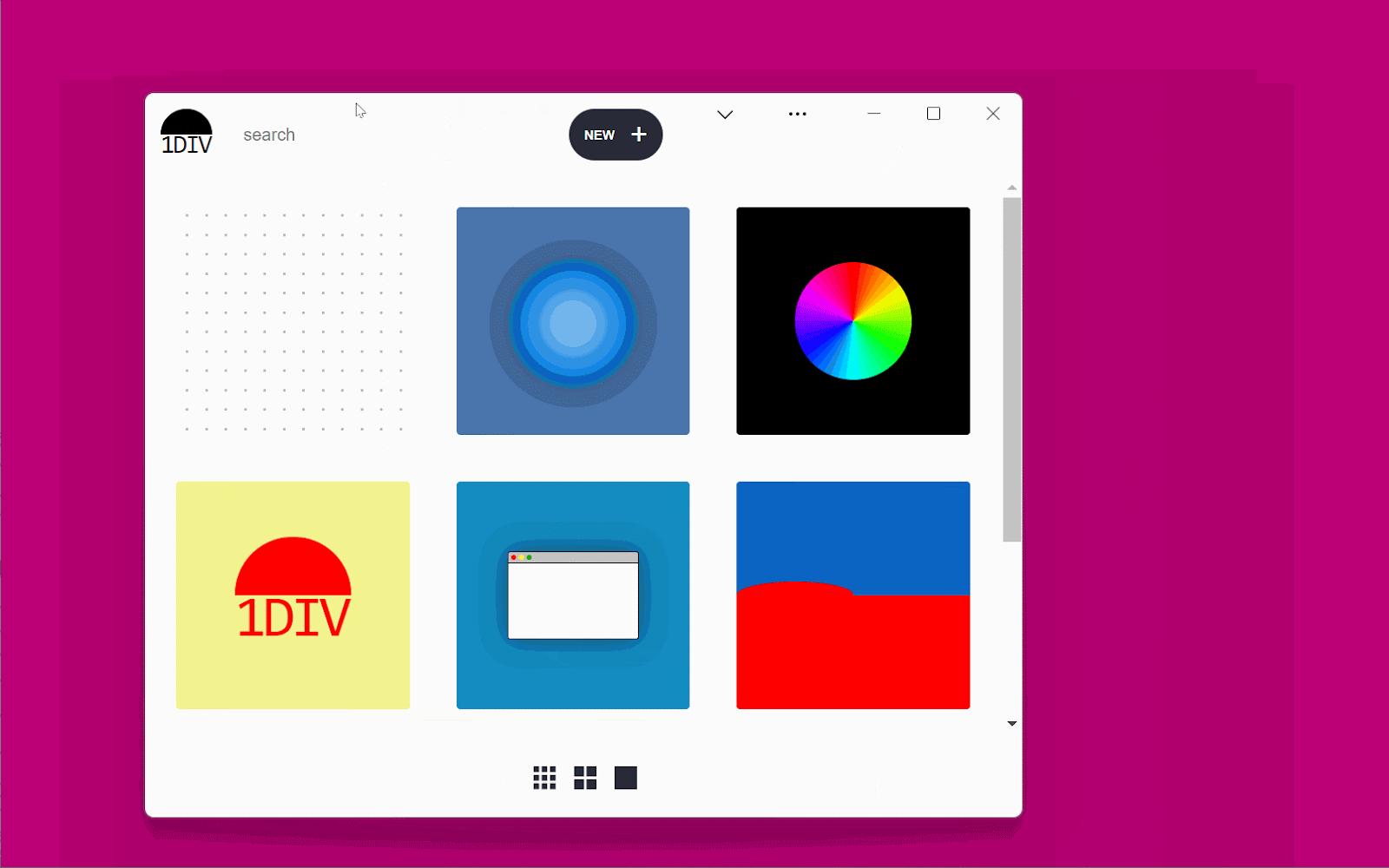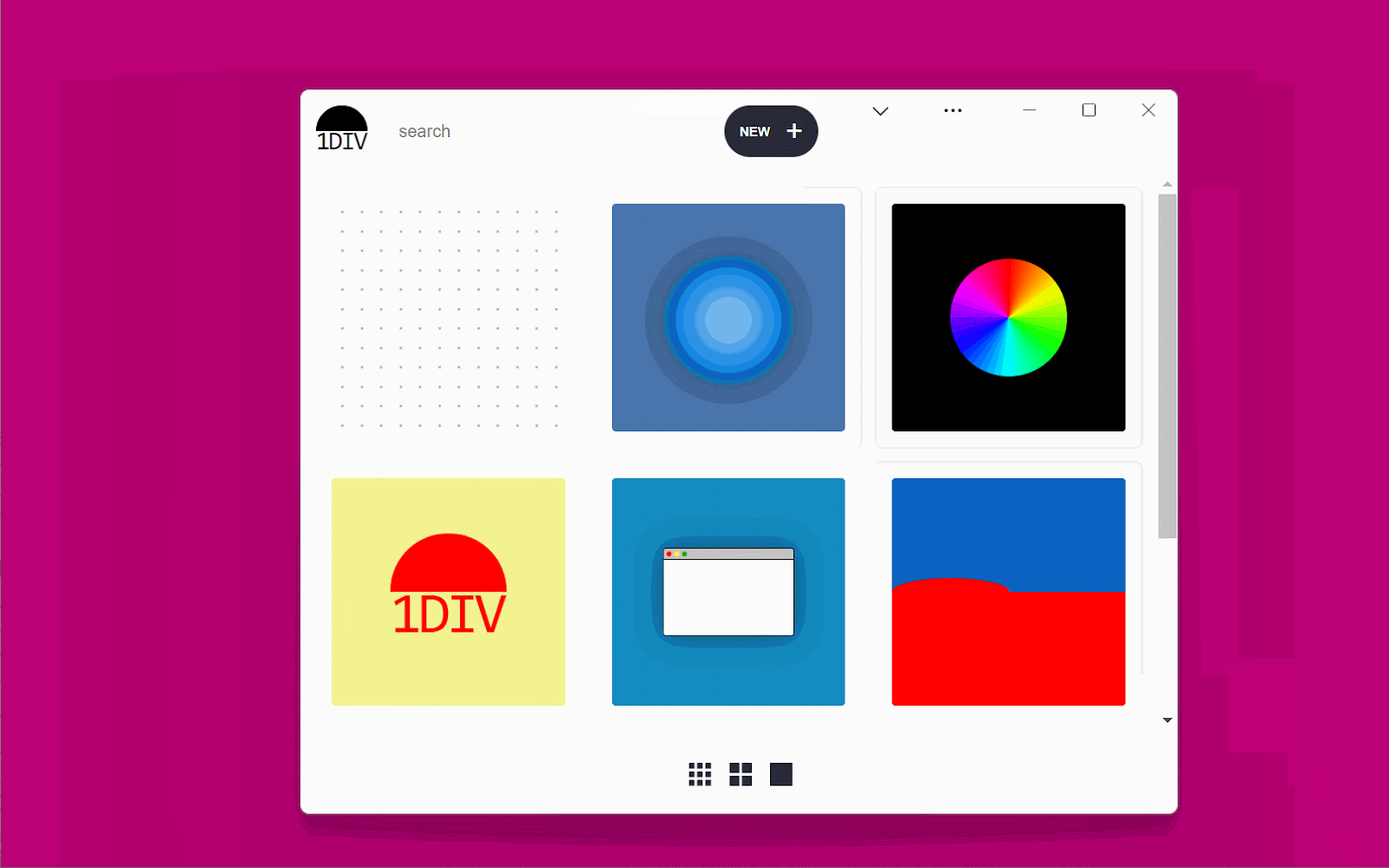
The demo app is called 1DIV. It's a simple CSS playground where users can create designs using CSS and a single HTML element.
The app has two pages. The first lists the existing CSS designs you've created:
 A screenshot of the 1DIV app displaying a thumbnail grid of CSS designs a user created.
A screenshot of the 1DIV app displaying a thumbnail grid of CSS designs a user created.
The second page enables you to create and edit CSS designs:
 A screenshot of the 1DIV app editor page. The top half of the window displays a rendered CSS design, and a text editor on the bottom half of the window displays the CSS used to create it.
A screenshot of the 1DIV app editor page. The top half of the window displays a rendered CSS design, and a text editor on the bottom half of the window displays the CSS used to create it.
Since I've added a simple web manifest and service worker, we can install the app as a PWA on desktop. Here is what it looks like on macOS:
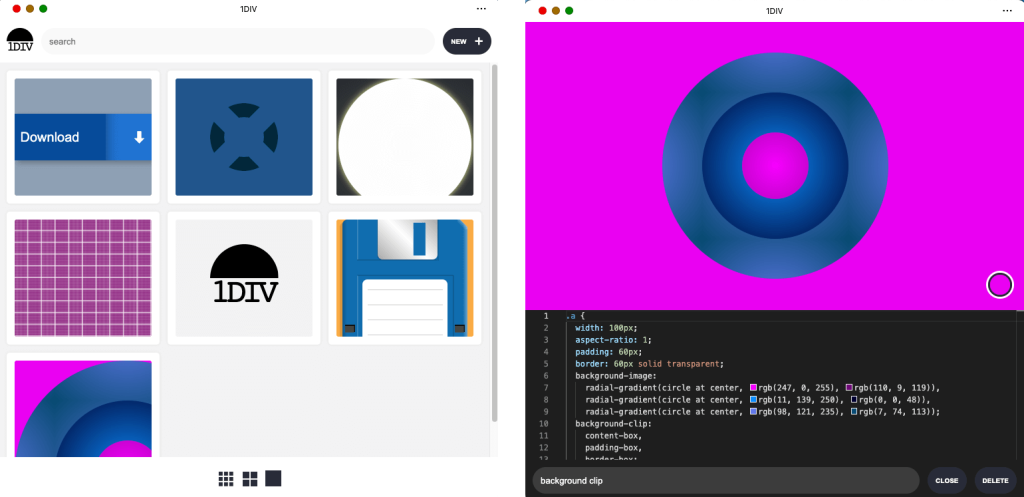 Screenshots of the 1DIV app thumbnail view and CSS editor view on macOS. This version of the app's window has a separate control bar at the top for the app name and window control buttons.
Screenshots of the 1DIV app thumbnail view and CSS editor view on macOS. This version of the app's window has a separate control bar at the top for the app name and window control buttons.
And on Windows:
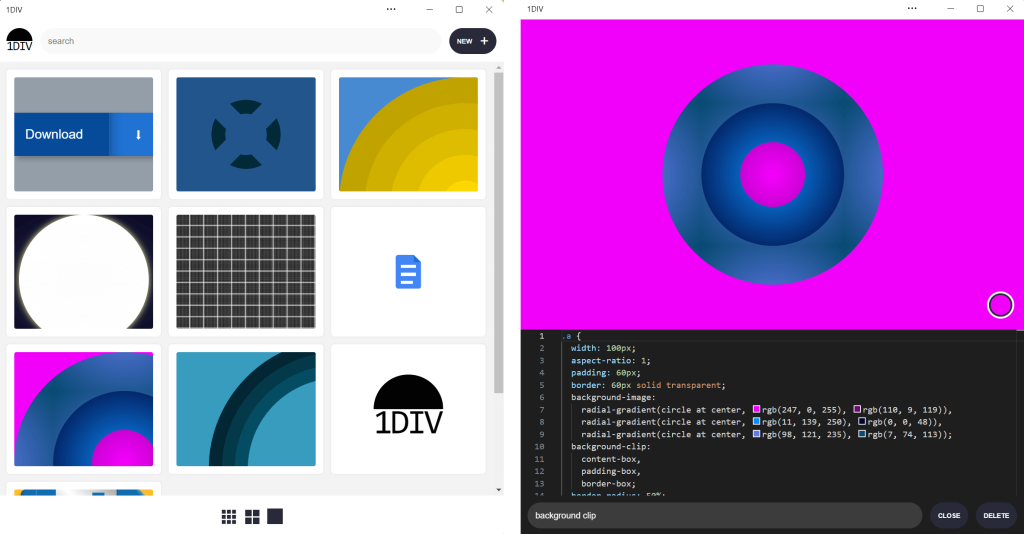 Screenshots of the 1DIV app thumbnail view and CSS editor view on the Windows operating system. This version of the app's window also has a separate control bar at the top for the app name and window control buttons.
Screenshots of the 1DIV app thumbnail view and CSS editor view on the Windows operating system. This version of the app's window also has a separate control bar at the top for the app name and window control buttons.
Our app is looking good, but the white title bar in the first page is wasted space. In the second page, it would be really nice if the design area went all the way to the top of the app window.
Let's use the Window Controls Overlay feature to improve this.
Enabling Window Controls OverlayThe feature is still experimental at the moment. To try it, you need to enable it in one of the supported browsers.
As of now, it has been implemented in Chromium, as a collaboration between Microsoft and Google. We can therefore use it in Chrome or Edge by going to the internal about://flags page, and enabling the Desktop PWA Window Controls Overlay flag.
Using Window Controls OverlayTo use the feature, we need to add the following display_override member to our web app's manifest file:
{
"name": "1DIV",
"description": "1DIV is a mini CSS playground",
"lang": "en-US",
"start_url": "/",
"theme_color": "#ffffff",
"background_color": "#ffffff",
"display_override": [
"window-controls-overlay"
],
"icons": [
...
]
}
On the surface, the feature is really simple to use. This manifest change is the only thing we need to make the title bar disappear and turn the window controls into an overlay.
However, to provide a great experience for all users regardless of what device or browser they use, and to make the most of the title bar area in our design, we'll need a bit of CSS and JavaScript code.
Here is what the app looks like now:
 Screenshot of the 1DIV app thumbnail view using Window Controls Overlay on macOS. The separate top bar area is gone, but the window controls are now blocking some of the app's interface
Screenshot of the 1DIV app thumbnail view using Window Controls Overlay on macOS. The separate top bar area is gone, but the window controls are now blocking some of the app's interface
The title bar is gone, which is what we wanted, but our logo, search field, and NEW button are partially covered by the window controls because now our layout starts at the top of the window.
It's similar on Windows, with the difference that the close, maximize, and minimize buttons appear on the right side, grouped together with the PWA control buttons:
 Screenshot of the 1DIV app thumbnail display using Window Controls Overlay on the Windows operating system. The separate top bar area is gone, but the window controls are now blocking some of the app's content.
Using CSS to keep clear of the window controls
Screenshot of the 1DIV app thumbnail display using Window Controls Overlay on the Windows operating system. The separate top bar area is gone, but the window controls are now blocking some of the app's content.
Using CSS to keep clear of the window controls
Along with the feature, new CSS environment variables have been introduced:
- titlebar-area-x
- titlebar-area-y
- titlebar-area-width
- titlebar-area-height
You use these variables with the CSS env() function to position your content where the title bar would have been while ensuring it won't overlap with the window controls. In our case, we'll use two of the variables to position our header, which contains the logo, search bar, and NEW button.
header {
position: absolute;
left: env(titlebar-area-x, 0);
width: env(titlebar-area-width, 100%);
height: var(--toolbar-height);
}
The titlebar-area-x variable gives us the distance from the left of the viewport to where the title bar would appear, and titlebar-area-width is its width. (Remember, this is not equivalent to the width of the entire viewport, just the title bar portion, which as noted earlier, doesn't include the window controls.)
By doing this, we make sure our content remains fully visible. We're also defining fallback values (the second parameter in the env() function) for when the variables are not defined (such as on non-supporting browsers, or when the Windows Control Overlay feature is disabled).
 Screenshot of the 1DIV app thumbnail view on macOS with Window Controls Overlay and our CSS updated. The app content that the window controls had been blocking has been repositioned.
Screenshot of the 1DIV app thumbnail view on macOS with Window Controls Overlay and our CSS updated. The app content that the window controls had been blocking has been repositioned.
 Screenshot of the 1DIV app thumbnail view on the Windows operating system with Window Controls Overlay and our updated CSS. The app content that the window controls had been blocking has been repositioned.
Screenshot of the 1DIV app thumbnail view on the Windows operating system with Window Controls Overlay and our updated CSS. The app content that the window controls had been blocking has been repositioned.
Now our header adapts to its surroundings, and it doesn't feel like the window control buttons have been added as an afterthought. The app looks a lot more like a native app.
Changing the window controls background color so it blends inNow let's take a closer look at our second page: the CSS playground editor.
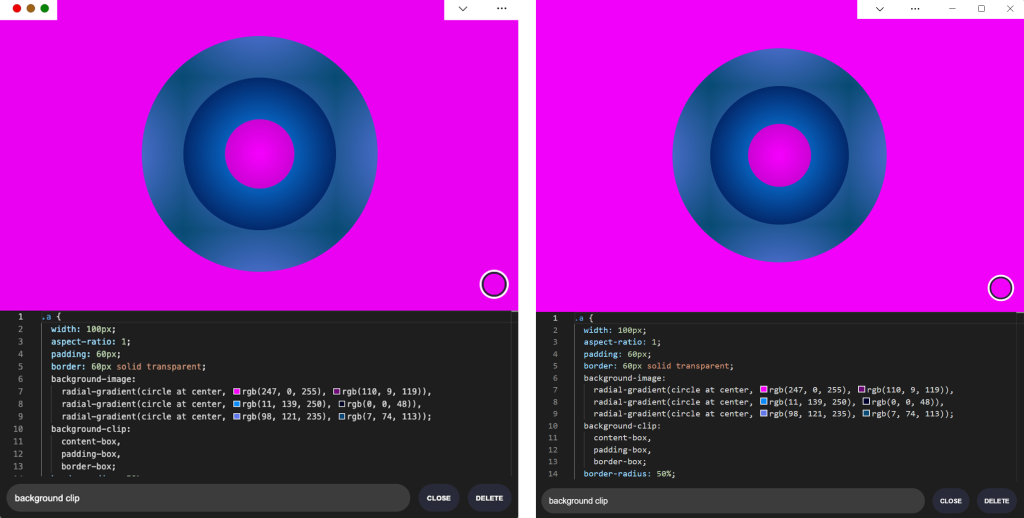 Screenshots of the 1DIV app CSS editor view with Window Controls Overlay in macOS and Windows, respectively. The window controls overlay areas have a solid white background color, which contrasts with the hot pink color of the example CSS design displayed in the editor.
Screenshots of the 1DIV app CSS editor view with Window Controls Overlay in macOS and Windows, respectively. The window controls overlay areas have a solid white background color, which contrasts with the hot pink color of the example CSS design displayed in the editor.
Not great. Our CSS demo area does go all the way to the top, which is what we wanted, but the way the window controls appear as white rectangles on top of it is quite jarring.
We can fix this by changing the app's theme color. There are a couple of ways to define it:
- PWAs can define a theme color in the web app manifest file using the theme_color manifest member. This color is then used by the OS in different ways. On desktop platforms, it is used to provide a background color to the title bar and window controls.
- Websites can use the theme-color meta tag as well. It's used by browsers to customize the color of the UI around the web page. For PWAs, this color can override the manifest theme_color.
In our case, we can set the manifest theme_color to white to provide the right default color for our app. The OS will read this color value when the app is installed and use it to make the window controls background color white. This color works great for our main page with the list of demos.
The theme-color meta tag can be changed at runtime, using JavaScript. So we can do that to override the white with the right demo background color when one is opened.
Here is the function we'll use:
function themeWindow(bgColor) {
document.querySelector("meta[name=theme-color]").setAttribute('content', bgColor);
}
With this in place, we can imagine how using color and CSS transitions can produce a smooth change from the list page to the demo page, and enable the window control buttons to blend in with the rest of the app's interface.
 Screenshot of the 1DIV app CSS editor view on the Windows operating system with Window Controls Overlay and updated CSS demonstrating how the window control buttons blend in with the rest of the app's interface.
Dragging the window
Screenshot of the 1DIV app CSS editor view on the Windows operating system with Window Controls Overlay and updated CSS demonstrating how the window control buttons blend in with the rest of the app's interface.
Dragging the window
Now, getting rid of the title bar entirely does have an important accessibility consequence: it's much more difficult to move the application window around.
The title bar provides a sizable area for users to click and drag, but by using the Window Controls Overlay feature, this area becomes limited to where the control buttons are, and users have to very precisely aim between these buttons to move the window.
Fortunately, this can be fixed using CSS with the app-region property. This property is, for now, only supported in Chromium-based browsers and needs the -webkit- vendor prefix.
To make any element of the app become a dragging target for the window, we can use the following:
-webkit-app-region: drag;
It is also possible to explicitly make an element non-draggable:
-webkit-app-region: no-drag;
These options can be useful for us. We can make the entire header a dragging target, but make the search field and NEW button within it non-draggable so they can still be used as normal.
However, because the editor page doesn't display the header, users wouldn't be able to drag the window while editing code. So let's use a different approach. We'll create another element before our header, also absolutely positioned, and dedicated to dragging the window.
<div ></div> <header>...</header>
.drag {
position: absolute;
top: 0;
width: 100%;
height: env(titlebar-area-height, 0);
-webkit-app-region: drag;
}
With the above code, we're making the draggable area span the entire viewport width, and using the titlebar-area-height variable to make it as tall as what the title bar would have been. This way, our draggable area is aligned with the window control buttons as shown below.
And, now, to make sure our search field and button remain usable:
header .search,
header .new {
-webkit-app-region: no-drag;
}
With the above code, users can click and drag where the title bar used to be. It is an area that users expect to be able to use to move windows on desktop, and we're not breaking this expectation, which is good.
 An animated view of the 1DIV app being dragged across a Windows desktop with the mouse.
Adapting to window resize
An animated view of the 1DIV app being dragged across a Windows desktop with the mouse.
Adapting to window resize
It may be useful for an app to know both whether the window controls overlay is visible and when its size changes. In our case, if the user made the window very narrow, there wouldn't be enough space for the search field, logo, and button to fit, so we'd want to push them down a bit.
The Window Controls Overlay feature comes with a JavaScript API we can use to do this: navigator.windowControlsOverlay.
The API provides three interesting things:
- navigator.windowControlsOverlay.visible lets us know whether the overlay is visible.
- navigator.windowControlsOverlay.getBoundingClientRect() lets us know the position and size of the title bar area.
- navigator.windowControlsOverlay.ongeometrychange lets us know when the size or visibility changes.
Let's use this to be aware of the size of the title bar area and move the header down if it's too narrow.
if (navigator.windowControlsOverlay) {
navigator.windowControlsOverlay.addEventListener('geometrychange', () => {
const { width } = navigator.windowControlsOverlay.getBoundingClientRect();
document.body.classList.toggle('narrow', width < 250);
});
}
In the example above, we set the narrow class on the body of the app if the title bar area is narrower than 250px. We could do something similar with a media query, but using the windowControlsOverlay API has two advantages for our use case:
- It's only fired when the feature is supported and used; we don't want to adapt the design otherwise.
- We get the size of the title bar area across operating systems, which is great because the size of the window controls is different on Mac and Windows. Using a media query wouldn't make it possible for us to know exactly how much space remains.
.narrow header {
top: env(titlebar-area-height, 0);
left: 0;
width: 100%;
}
Using the above CSS code, we can move our header down to stay clear of the window control buttons when the window is too narrow, and move the thumbnails down accordingly.
 A screenshot of the 1DIV app on Windows showing the app's content adjusted for a much narrower viewport.
Thirty pixels of exciting design opportunities
A screenshot of the 1DIV app on Windows showing the app's content adjusted for a much narrower viewport.
Thirty pixels of exciting design opportunities
Using the Window Controls Overlay feature, we were able to take our simple demo app and turn it into something that feels so much more integrated on desktop devices. Something that reaches out of the usual window constraints and provides a custom experience for its users.
In reality, this feature only gives us about 30 pixels of extra room and comes with challenges on how to deal with the window controls. And yet, this extra room and those challenges can be turned into exciting design opportunities.
More devices of all shapes and forms get invented all the time, and the web keeps on evolving to adapt to them. New features get added to the web platform to allow us, web authors, to integrate more and more deeply with those devices. From watches or foldable devices to desktop computers, we need to evolve our design approach for the web. Building for the web now lets us think outside the rectangular box.
So let's embrace this. Let's use the standard technologies already at our disposal, and experiment with new ideas to provide tailored experiences for all devices, all from a single codebase!
If you get a chance to try the Window Controls Overlay feature and have feedback about it, you can open issues on the spec's repository. It's still early in the development of this feature, and you can help make it even better. Or, you can take a look at the feature's existing documentation, or this demo app and its source code.
Do you find yourself designing screens with only a vague idea of how the things on the screen relate to the things elsewhere in the system? Do you leave stakeholder meetings with unclear directives that often seem to contradict previous conversations? You know a better understanding of user needs would help the team get clear on what you are actually trying to accomplish, but time and budget for research is tight. When it comes to asking for more direct contact with your users, you might feel like poor Oliver Twist, timidly asking, "Please, sir, I want some more."
Here's the trick. You need to get stakeholders themselves to identify high-risk assumptions and hidden complexity, so that they become just as motivated as you to get answers from users. Basically, you need to make them think it's their idea.
In this article, I'll show you how to collaboratively expose misalignment and gaps in the team's shared understanding by bringing the team together around two simple questions:
- What are the objects?
- What are the relationships between those objects?
These two questions align to the first two steps of the ORCA process, which might become your new best friend when it comes to reducing guesswork. Wait, what's ORCA?! Glad you asked.
ORCA stands for Objects, Relationships, CTAs, and Attributes, and it outlines a process for creating solid object-oriented user experiences. Object-oriented UX is my design philosophy. ORCA is an iterative methodology for synthesizing user research into an elegant structural foundation to support screen and interaction design. OOUX and ORCA have made my work as a UX designer more collaborative, effective, efficient, fun, strategic, and meaningful.
The ORCA process has four iterative rounds and a whopping fifteen steps. In each round we get more clarity on our Os, Rs, Cs, and As.
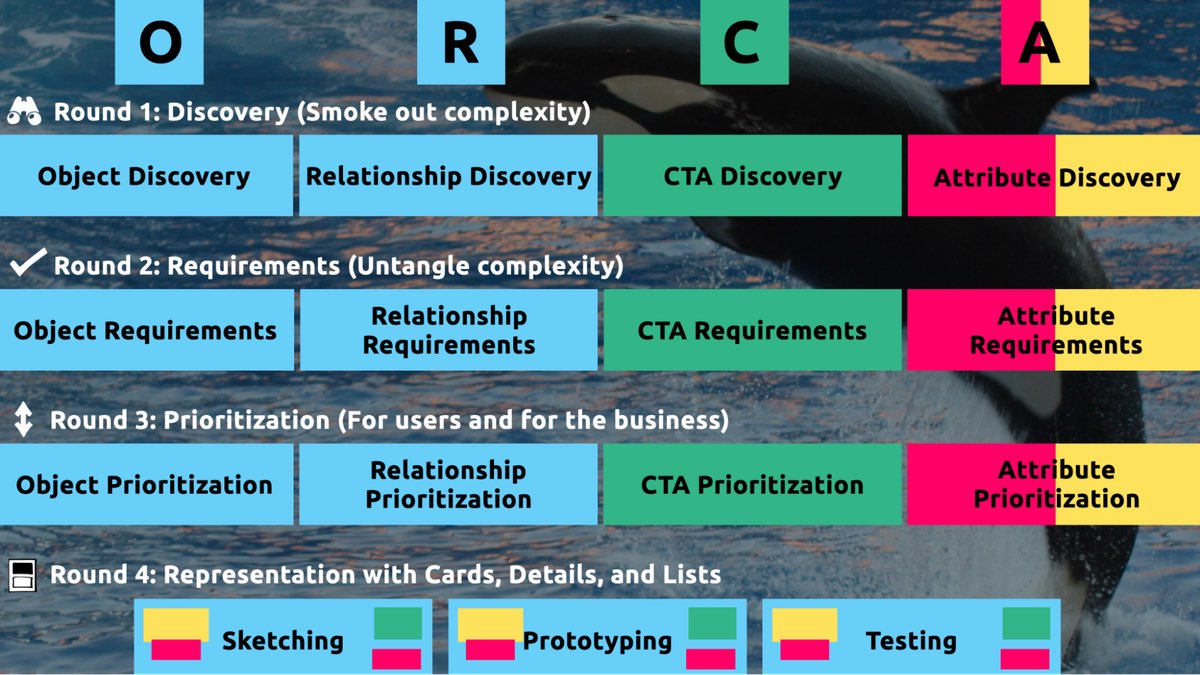 The four rounds and fifteen steps of the ORCA process. In the OOUX world, we love color-coding. Blue is reserved for objects! (Yellow is for core content, pink is for metadata, and green is for calls-to-action. Learn more about the color-coded object map and connecting CTAs to objects.)
The four rounds and fifteen steps of the ORCA process. In the OOUX world, we love color-coding. Blue is reserved for objects! (Yellow is for core content, pink is for metadata, and green is for calls-to-action. Learn more about the color-coded object map and connecting CTAs to objects.)
I sometimes say that ORCA is a "garbage in, garbage out" process. To ensure that the testable prototype produced in the final round actually tests well, the process needs to be fed by good research. But if you don't have a ton of research, the beginning of the ORCA process serves another purpose: it helps you sell the need for research.
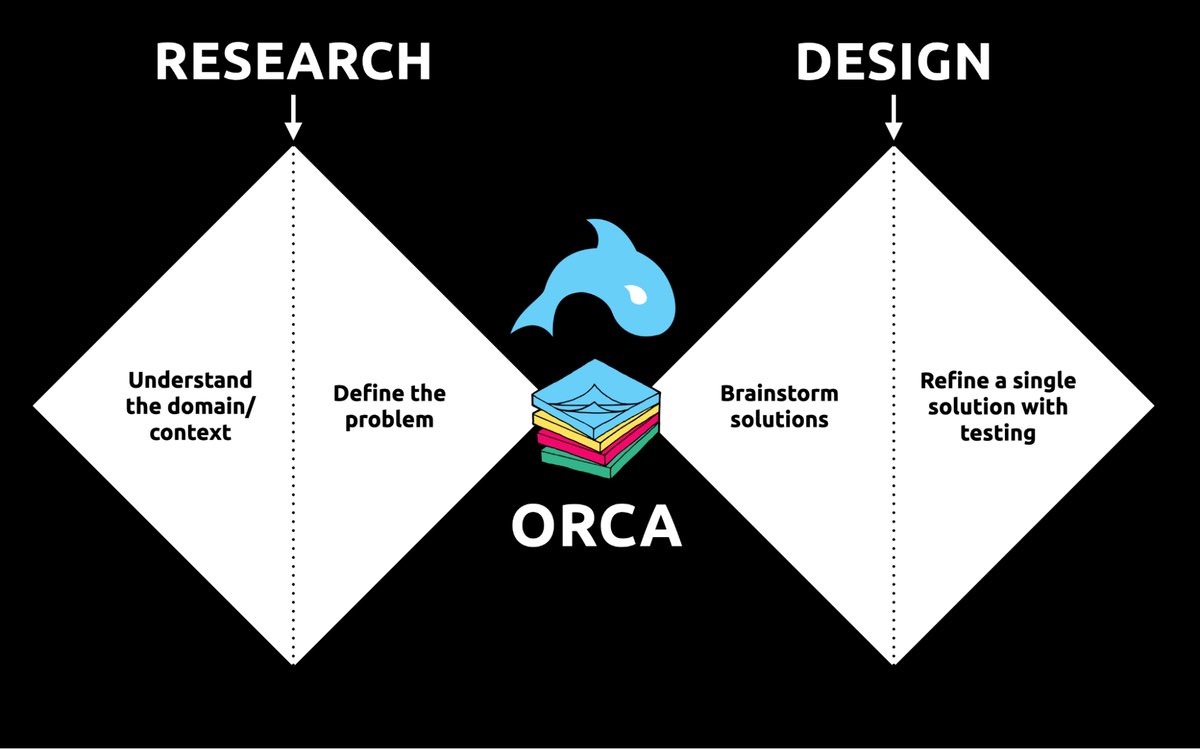 ORCA strengthens the weak spot between research and design by helping distill research into solid information architecture—scaffolding for the screen design and interaction design to hang on.
ORCA strengthens the weak spot between research and design by helping distill research into solid information architecture—scaffolding for the screen design and interaction design to hang on.
In other words, the ORCA process serves as a gauntlet between research and design. With good research, you can gracefully ride the killer whale from research into design. But without good research, the process effectively spits you back into research and with a cache of specific open questions.
Getting in the same curiosity-boatWhat gets us into trouble is not what we don't know. It's what we know for sure that just ain't so.
Mark Twain
The first two steps of the ORCA process—Object Discovery and Relationship Discovery—shine a spotlight on the dark, dusty corners of your team's misalignments and any inherent complexity that's been swept under the rug. It begins to expose what this classic comic so beautifully illustrates:
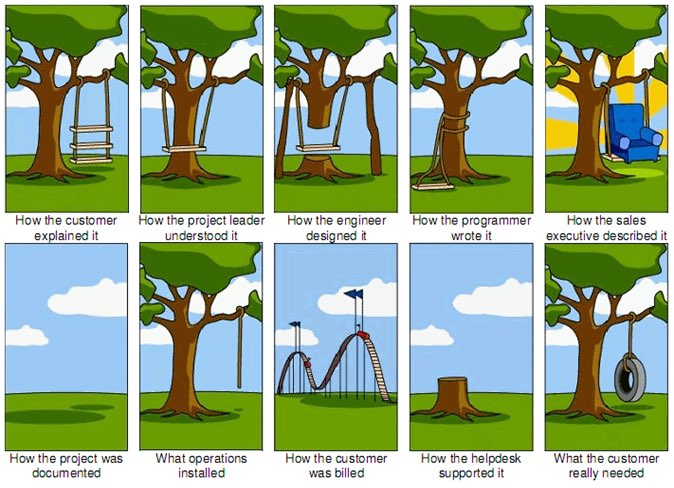 The original "Tree Swing Project Management" cartoon dates back to the 1960s or 1970s and has no artist attribution we could find.
The original "Tree Swing Project Management" cartoon dates back to the 1960s or 1970s and has no artist attribution we could find.
This is one reason why so many UX designers are frustrated in their job and why many projects fail. And this is also why we often can't sell research: every decision-maker is confident in their own mental picture.
Once we expose hidden fuzzy patches in each picture and the differences between them all, the case for user research makes itself.
But how we do this is important. However much we might want to, we can't just tell everyone, "YOU ARE WRONG!" Instead, we need to facilitate and guide our team members to self-identify holes in their picture. When stakeholders take ownership of assumptions and gaps in understanding, BAM! Suddenly, UX research is not such a hard sell, and everyone is aboard the same curiosity-boat.
Say your users are doctors. And you have no idea how doctors use the system you are tasked with redesigning.
You might try to sell research by honestly saying: "We need to understand doctors better! What are their pain points? How do they use the current app?" But here's the problem with that. Those questions are vague, and the answers to them don't feel acutely actionable.
Instead, you want your stakeholders themselves to ask super-specific questions. This is more like the kind of conversation you need to facilitate. Let's listen in:
"Wait a sec, how often do doctors share patients? Does a patient in this system have primary and secondary doctors?"
"Can a patient even have more than one primary doctor?"
"Is it a 'primary doctor' or just a 'primary caregiver'… Can't that role be a nurse practitioner?"
"No, caregivers are something else… That's the patient's family contacts, right?"
"So are caregivers in scope for this redesign?"
"Yeah, because if a caregiver is present at an appointment, the doctor needs to note that. Like, tag the caregiver on the note… Or on the appointment?"
Now we are getting somewhere. Do you see how powerful it can be getting stakeholders to debate these questions themselves? The diabolical goal here is to shake their confidence—gently and diplomatically.
When these kinds of questions bubble up collaboratively and come directly from the mouths of your stakeholders and decision-makers, suddenly, designing screens without knowing the answers to these questions seems incredibly risky, even silly.
If we create software without understanding the real-world information environment of our users, we will likely create software that does not align to the real-world information environment of our users. And this will, hands down, result in a more confusing, more complex, and less intuitive software product.
The two questionsBut how do we get to these kinds of meaty questions diplomatically, efficiently, collaboratively, and reliably?
We can do this by starting with those two big questions that align to the first two steps of the ORCA process:
- What are the objects?
- What are the relationships between those objects?
In practice, getting to these answers is easier said than done. I'm going to show you how these two simple questions can provide the outline for an Object Definition Workshop. During this workshop, these "seed" questions will blossom into dozens of specific questions and shine a spotlight on the need for more user research.
Prep work: Noun foragingIn the next section, I'll show you how to run an Object Definition Workshop with your stakeholders (and entire cross-functional team, hopefully). But first, you need to do some prep work.
Basically, look for nouns that are particular to the business or industry of your project, and do it across at least a few sources. I call this noun foraging.
Here are just a few great noun foraging sources:
- the product's marketing site
- the product's competitors' marketing sites (competitive analysis, anyone?)
- the existing product (look at labels!)
- user interview transcripts
- notes from stakeholder interviews or vision docs from stakeholders
Put your detective hat on, my dear Watson. Get resourceful and leverage what you have. If all you have is a marketing website, some screenshots of the existing legacy system, and access to customer service chat logs, then use those.
As you peruse these sources, watch for the nouns that are used over and over again, and start listing them (preferably on blue sticky notes if you'll be creating an object map later!).
You'll want to focus on nouns that might represent objects in your system. If you are having trouble determining if a noun might be object-worthy, remember the acronym SIP and test for:
- Structure
- Instances
- Purpose
Think of a library app, for example. Is "book" an object?
Structure: can you think of a few attributes for this potential object? Title, author, publish date… Yep, it has structure. Check!
Instance: what are some examples of this potential "book" object? Can you name a few? The Alchemist, Ready Player One, Everybody Poops… OK, check!
Purpose: why is this object important to the users and business? Well, "book" is what our library client is providing to people and books are why people come to the library… Check, check, check!
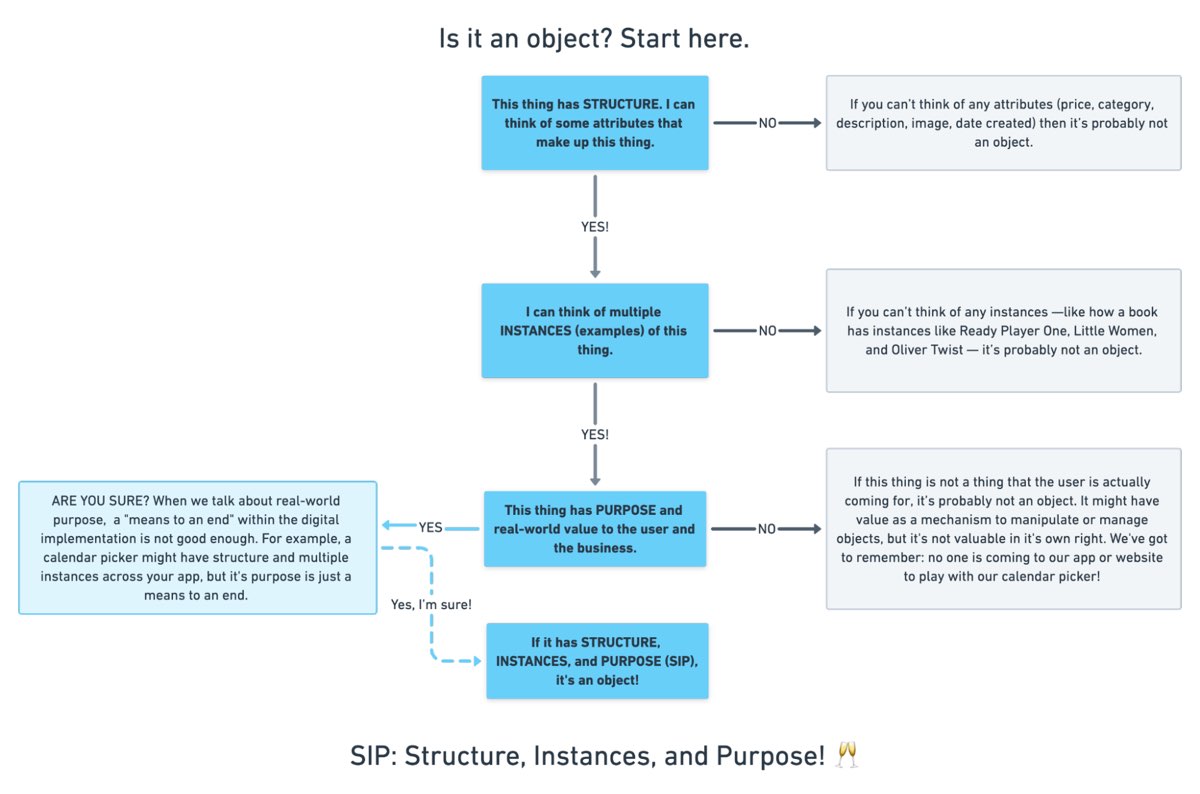 SIP: Structure, Instances, and Purpose! (Here's a flowchart where I elaborate even more on SIP.)
SIP: Structure, Instances, and Purpose! (Here's a flowchart where I elaborate even more on SIP.)
As you are noun foraging, focus on capturing the nouns that have SIP. Avoid capturing components like dropdowns, checkboxes, and calendar pickers—your UX system is not your design system! Components are just the packaging for objects—they are a means to an end. No one is coming to your digital place to play with your dropdown! They are coming for the VALUABLE THINGS and what they can do with them. Those things, or objects, are what we are trying to identify.
Let's say we work for a startup disrupting the email experience. This is how I'd start my noun foraging.
First I'd look at my own email client, which happens to be Gmail. I'd then look at Outlook and the new HEY email. I'd look at Yahoo, Hotmail…I'd even look at Slack and Basecamp and other so-called "email replacers." I'd read some articles, reviews, and forum threads where people are complaining about email. While doing all this, I would look for and write down the nouns.
(Before moving on, feel free to go noun foraging for this hypothetical product, too, and then scroll down to see how much our lists match up. Just don't get lost in your own emails! Come back to me!)
Drumroll, please…
Here are a few nouns I came up with during my noun foraging:
- email message
- thread
- contact
- client
- rule/automation
- email address that is not a contact?
- contact groups
- attachment
- Google doc file / other integrated file
- newsletter? (HEY treats this differently)
- saved responses and templates
 In the OOUX world, we love color-coding. Blue is reserved for objects! (Yellow is for core content, pink is for metadata, and green is for calls-to-action. Learn more about the color coded object map and connecting CTAs to objects.)
In the OOUX world, we love color-coding. Blue is reserved for objects! (Yellow is for core content, pink is for metadata, and green is for calls-to-action. Learn more about the color coded object map and connecting CTAs to objects.)
Scan your list of nouns and pick out words that you are completely clueless about. In our email example, it might be client or automation. Do as much homework as you can before your session with stakeholders: google what's googleable. But other terms might be so specific to the product or domain that you need to have a conversation about them.
Aside: here are some real nouns foraged during my own past project work that I needed my stakeholders to help me understand:
- Record Locator
- Incentive Home
- Augmented Line Item
- Curriculum-Based Measurement Probe
This is really all you need to prepare for the workshop session: a list of nouns that represent potential objects and a short list of nouns that need to be defined further.
Facilitate an Object Definition WorkshopYou could actually start your workshop with noun foraging—this activity can be done collaboratively. If you have five people in the room, pick five sources, assign one to every person, and give everyone ten minutes to find the objects within their source. When the time's up, come together and find the overlap. Affinity mapping is your friend here!
If your team is short on time and might be reluctant to do this kind of grunt work (which is usually the case) do your own noun foraging beforehand, but be prepared to show your work. I love presenting screenshots of documents and screens with all the nouns already highlighted. Bring the artifacts of your process, and start the workshop with a five-minute overview of your noun foraging journey.
HOT TIP: before jumping into the workshop, frame the conversation as a requirements-gathering session to help you better understand the scope and details of the system. You don't need to let them know that you're looking for gaps in the team's understanding so that you can prove the need for more user research—that will be our little secret. Instead, go into the session optimistically, as if your knowledgeable stakeholders and PMs and biz folks already have all the answers.
Then, let the question whack-a-mole commence.
1. What is this thing?Want to have some real fun? At the beginning of your session, ask stakeholders to privately write definitions for the handful of obscure nouns you might be uncertain about. Then, have everyone show their cards at the same time and see if you get different definitions (you will). This is gold for exposing misalignment and starting great conversations.
As your discussion unfolds, capture any agreed-upon definitions. And when uncertainty emerges, quietly (but visibly) start an "open questions" parking lot.
Do you remember when having a great website was enough? Now, people are getting answers from Siri, Google search snippets, and mobile apps, not just our websites. Forward-thinking organizations have adopted an omnichannel content strategy, whose mission is to reach audiences across multiple digital channels and platforms.
But how do you set up a content management system (CMS) to reach your audience now and in the future? I learned the hard way that creating a content model—a definition of content types, attributes, and relationships that let people and systems understand content—with my more familiar design-system thinking would capsize my customer's omnichannel content strategy. You can avoid that outcome by creating content models that are semantic and that also connect related content.
I recently had the opportunity to lead the CMS implementation for a Fortune 500 company. The client was excited by the benefits of an omnichannel content strategy, including content reuse, multichannel marketing, and robot delivery—designing content to be intelligible to bots, Google knowledge panels, snippets, and voice user interfaces.
A content model is a critical foundation for an omnichannel content strategy, and for our content to be understood by multiple systems, the model needed semantic types—types named according to their meaning instead of their presentation. Our goal was to let authors create content and reuse it wherever it was relevant. But as the project proceeded, I realized that supporting content reuse at the scale that my customer needed required the whole team to recognize a new pattern.
Despite our best intentions, we kept drawing from what we were more familiar with: design systems. Unlike web-focused content strategies, an omnichannel content strategy can't rely on WYSIWYG tools for design and layout. Our tendency to approach the content model with our familiar design-system thinking constantly led us to veer away from one of the primary purposes of a content model: delivering content to audiences on multiple marketing channels.
Two essential principles for an effective content modelWe needed to help our designers, developers, and stakeholders understand that we were doing something very different from their prior web projects, where it was natural for everyone to think about content as visual building blocks fitting into layouts. The previous approach was not only more familiar but also more intuitive—at least at first—because it made the designs feel more tangible. We discovered two principles that helped the team understand how a content model differs from the design systems that we were used to:
- Content models must define semantics instead of layout.
- And content models should connect content that belongs together.
A semantic content model uses type and attribute names that reflect the meaning of the content, not how it will be displayed. For example, in a nonsemantic model, teams might create types like teasers, media blocks, and cards. Although these types might make it easy to lay out content, they don't help delivery channels understand the content's meaning, which in turn would have opened the door to the content being presented in each marketing channel. In contrast, a semantic content model uses type names like product, service, and testimonial so that each delivery channel can understand the content and use it as it sees fit.
When you're creating a semantic content model, a great place to start is to look over the types and properties defined by Schema.org, a community-driven resource for type definitions that are intelligible to platforms like Google search.
A semantic content model has several benefits:
- Even if your team doesn't care about omnichannel content, a semantic content model decouples content from its presentation so that teams can evolve the website's design without needing to refactor its content. In this way, content can withstand disruptive website redesigns.
- A semantic content model also provides a competitive edge. By adding structured data based on Schema.org's types and properties, a website can provide hints to help Google understand the content, display it in search snippets or knowledge panels, and use it to answer voice-interface user questions. Potential visitors could discover your content without ever setting foot in your website.
- Beyond those practical benefits, you'll also need a semantic content model if you want to deliver omnichannel content. To use the same content in multiple marketing channels, delivery channels need to be able to understand it. For example, if your content model were to provide a list of questions and answers, it could easily be rendered on a frequently asked questions (FAQ) page, but it could also be used in a voice interface or by a bot that answers common questions.
For example, using a semantic content model for articles, events, people, and locations lets A List Apart provide cleanly structured data for search engines so that users can read the content on the website, in Google knowledge panels, and even with hypothetical voice interfaces in the future.
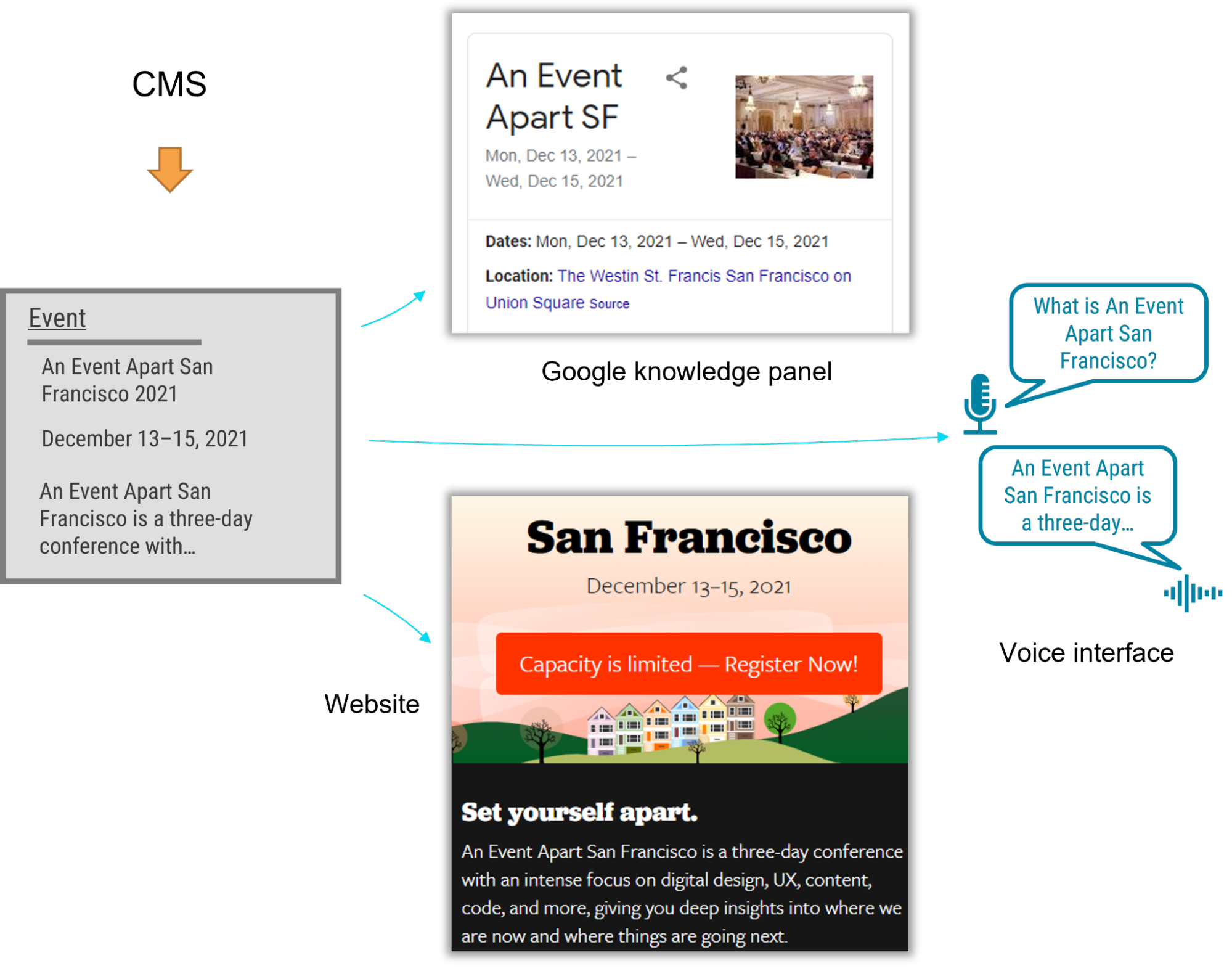 Content models that connect
Content models that connect
After struggling to describe what makes a good content model, I've come to realize that the best models are those that are semantic and that also connect related content components (such as a FAQ item's question and answer pair), instead of slicing up related content across disparate content components. A good content model connects content that should remain together so that multiple delivery channels can use it without needing to first put those pieces back together.
Think about writing an article or essay. An article's meaning and usefulness depends upon its parts being kept together. Would one of the headings or paragraphs be meaningful on their own without the context of the full article? On our project, our familiar design-system thinking often led us to want to create content models that would slice content into disparate chunks to fit the web-centric layout. This had a similar impact to an article that were to have been separated from its headline. Because we were slicing content into standalone pieces based on layout, content that belonged together became difficult to manage and nearly impossible for multiple delivery channels to understand.
To illustrate, let's look at how connecting related content applies in a real-world scenario. The design team for our customer presented a complex layout for a software product page that included multiple tabs and sections. Our instincts were to follow suit with the content model. Shouldn't we make it as easy and as flexible as possible to add any number of tabs in the future?
Because our design-system instincts were so familiar, it felt like we had needed a content type called "tab section" so that multiple tab sections could be added to a page. Each tab section would display various types of content. One tab might provide the software's overview or its specifications. Another tab might provide a list of resources.
Our inclination to break down the content model into "tab section" pieces would have led to an unnecessarily complex model and a cumbersome editing experience, and it would have also created content that couldn't have been understood by additional delivery channels. For example, how would another system have been able to tell which "tab section" referred to a product's specifications or its resource list—would that other system have to have resorted to counting tab sections and content blocks? This would have prevented the tabs from ever being reordered, and it would have required adding logic in every other delivery channel to interpret the design system's layout. Furthermore, if the customer were to have no longer wanted to display this content in a tab layout, it would have been tedious to migrate to a new content model to reflect the new page redesign.
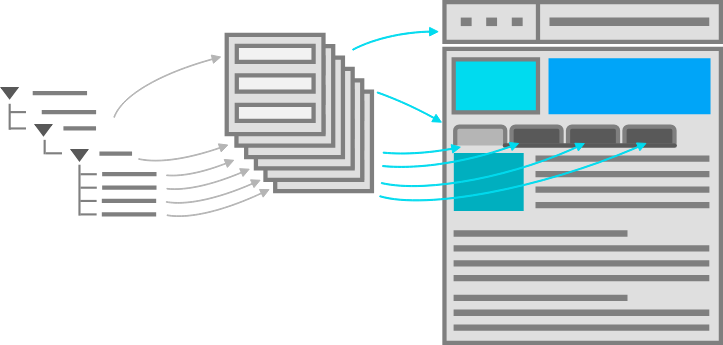 A content model based on design components is unnecessarily complex, and it's unintelligible to systems.
A content model based on design components is unnecessarily complex, and it's unintelligible to systems.
We had a breakthrough when we discovered that our customer had a specific purpose in mind for each tab: it would reveal specific information such as the software product's overview, specifications, related resources, and pricing. Once implementation began, our inclination to focus on what's visual and familiar had obscured the intent of the designs. With a little digging, it didn't take long to realize that the concept of tabs wasn't relevant to the content model. The meaning of the content that they were planning to display in the tabs was what mattered.
In fact, the customer could have decided to display this content in a different way—without tabs—somewhere else. This realization prompted us to define content types for the software product based on the meaningful attributes that the customer had wanted to render on the web. There were obvious semantic attributes like name and description as well as rich attributes like screenshots, software requirements, and feature lists. The software's product information stayed together because it wasn't sliced across separate components like "tab sections" that were derived from the content's presentation. Any delivery channel—including future ones—could understand and present this content.
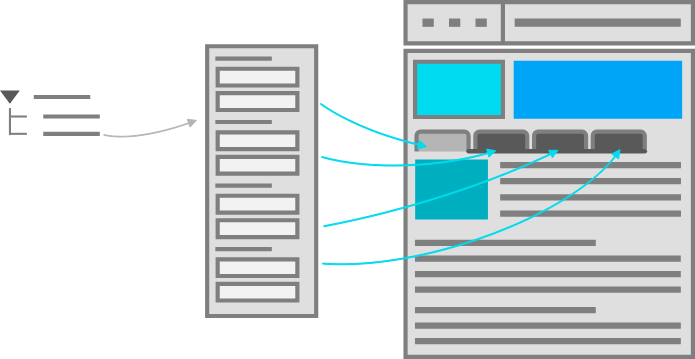 A good content model connects content that belongs together so it can be easily managed and reused.
Conclusion
A good content model connects content that belongs together so it can be easily managed and reused.
Conclusion
In this omnichannel marketing project, we discovered that the best way to keep our content model on track was to ensure that it was semantic (with type and attribute names that reflected the meaning of the content) and that it kept content together that belonged together (instead of fragmenting it). These two concepts curtailed our temptation to shape the content model based on the design. So if you're working on a content model to support an omnichannel content strategy—or even if you just want to make sure that Google and other interfaces understand your content—remember:
- A design system isn't a content model. Team members may be tempted to conflate them and to make your content model mirror your design system, so you should protect the semantic value and contextual structure of the content strategy during the entire implementation process. This will let every delivery channel consume the content without needing a magic decoder ring.
- If your team is struggling to make this transition, you can still reap some of the benefits by using Schema.org-based structured data in your website. Even if additional delivery channels aren't on the immediate horizon, the benefit to search engine optimization is a compelling reason on its own.
- Additionally, remind the team that decoupling the content model from the design will let them update the designs more easily because they won't be held back by the cost of content migrations. They'll be able to create new designs without the obstacle of compatibility between the design and the content, and they'll be ready for the next big thing.
By rigorously advocating for these principles, you'll help your team treat content the way that it deserves—as the most critical asset in your user experience and the best way to connect with your audience.
Antiracist economist Kim Crayton says that "intention without strategy is chaos." We've discussed how our biases, assumptions, and inattention toward marginalized and vulnerable groups lead to dangerous and unethical tech—but what, specifically, do we need to do to fix it? The intention to make our tech safer is not enough; we need a strategy.
This chapter will equip you with that plan of action. It covers how to integrate safety principles into your design work in order to create tech that's safe, how to convince your stakeholders that this work is necessary, and how to respond to the critique that what we actually need is more diversity. (Spoiler: we do, but diversity alone is not the antidote to fixing unethical, unsafe tech.)
The process for inclusive safetyWhen you are designing for safety, your goals are to:
- identify ways your product can be used for abuse,
- design ways to prevent the abuse, and
- provide support for vulnerable users to reclaim power and control.
The Process for Inclusive Safety is a tool to help you reach those goals (Fig 5.1). It's a methodology I created in 2018 to capture the various techniques I was using when designing products with safety in mind. Whether you are creating an entirely new product or adding to an existing feature, the Process can help you make your product safe and inclusive. The Process includes five general areas of action:
- Conducting research
- Creating archetypes
- Brainstorming problems
- Designing solutions
- Testing for safety
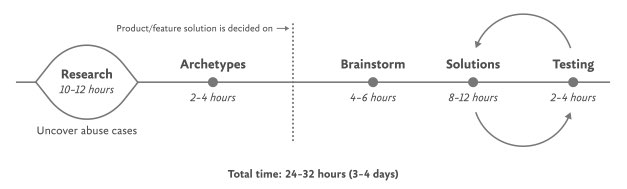 Fig 5.1: Each aspect of the Process for Inclusive Safety can be incorporated into your design process where it makes the most sense for you. The times given are estimates to help you incorporate the stages into your design plan.
Fig 5.1: Each aspect of the Process for Inclusive Safety can be incorporated into your design process where it makes the most sense for you. The times given are estimates to help you incorporate the stages into your design plan.
The Process is meant to be flexible—it won't make sense for teams to implement every step in some situations. Use the parts that are relevant to your unique work and context; this is meant to be something you can insert into your existing design practice.
And once you use it, if you have an idea for making it better or simply want to provide context of how it helped your team, please get in touch with me. It's a living document that I hope will continue to be a useful and realistic tool that technologists can use in their day-to-day work.
If you're working on a product specifically for a vulnerable group or survivors of some form of trauma, such as an app for survivors of domestic violence, sexual assault, or drug addiction, be sure to read Chapter 7, which covers that situation explicitly and should be handled a bit differently. The guidelines here are for prioritizing safety when designing a more general product that will have a wide user base (which, we already know from statistics, will include certain groups that should be protected from harm). Chapter 7 is focused on products that are specifically for vulnerable groups and people who have experienced trauma.
Step 1: Conduct researchDesign research should include a broad analysis of how your tech might be weaponized for abuse as well as specific insights into the experiences of survivors and perpetrators of that type of abuse. At this stage, you and your team will investigate issues of interpersonal harm and abuse, and explore any other safety, security, or inclusivity issues that might be a concern for your product or service, like data security, racist algorithms, and harassment.
Broad researchYour project should begin with broad, general research into similar products and issues around safety and ethical concerns that have already been reported. For example, a team building a smart home device would do well to understand the multitude of ways that existing smart home devices have been used as tools of abuse. If your product will involve AI, seek to understand the potentials for racism and other issues that have been reported in existing AI products. Nearly all types of technology have some kind of potential or actual harm that's been reported on in the news or written about by academics. Google Scholar is a useful tool for finding these studies.
Specific research: SurvivorsWhen possible and appropriate, include direct research (surveys and interviews) with people who are experts in the forms of harm you have uncovered. Ideally, you'll want to interview advocates working in the space of your research first so that you have a more solid understanding of the topic and are better equipped to not retraumatize survivors. If you've uncovered possible domestic violence issues, for example, the experts you'll want to speak with are survivors themselves, as well as workers at domestic violence hotlines, shelters, other related nonprofits, and lawyers.
Especially when interviewing survivors of any kind of trauma, it is important to pay people for their knowledge and lived experiences. Don't ask survivors to share their trauma for free, as this is exploitative. While some survivors may not want to be paid, you should always make the offer in the initial ask. An alternative to payment is to donate to an organization working against the type of violence that the interviewee experienced. We'll talk more about how to appropriately interview survivors in Chapter 6.
Specific research: AbusersIt's unlikely that teams aiming to design for safety will be able to interview self-proclaimed abusers or people who have broken laws around things like hacking. Don't make this a goal; rather, try to get at this angle in your general research. Aim to understand how abusers or bad actors weaponize technology to use against others, how they cover their tracks, and how they explain or rationalize the abuse.
Step 2: Create archetypesOnce you've finished conducting your research, use your insights to create abuser and survivor archetypes. Archetypes are not personas, as they're not based on real people that you interviewed and surveyed. Instead, they're based on your research into likely safety issues, much like when we design for accessibility: we don't need to have found a group of blind or low-vision users in our interview pool to create a design that's inclusive of them. Instead, we base those designs on existing research into what this group needs. Personas typically represent real users and include many details, while archetypes are broader and can be more generalized.
The abuser archetype is someone who will look at the product as a tool to perform harm (Fig 5.2). They may be trying to harm someone they don't know through surveillance or anonymous harassment, or they may be trying to control, monitor, abuse, or torment someone they know personally.
 Fig 5.2: Harry Oleson, an abuser archetype for a fitness product, is looking for ways to stalk his ex-girlfriend through the fitness apps she uses.
Fig 5.2: Harry Oleson, an abuser archetype for a fitness product, is looking for ways to stalk his ex-girlfriend through the fitness apps she uses.
The survivor archetype is someone who is being abused with the product. There are various situations to consider in terms of the archetype's understanding of the abuse and how to put an end to it: Do they need proof of abuse they already suspect is happening, or are they unaware they've been targeted in the first place and need to be alerted (Fig 5.3)?
 Fig 5.3: The survivor archetype Lisa Zwaan suspects her husband is weaponizing their home's IoT devices against her, but in the face of his insistence that she simply doesn't understand how to use the products, she's unsure. She needs some kind of proof of the abuse.
Fig 5.3: The survivor archetype Lisa Zwaan suspects her husband is weaponizing their home's IoT devices against her, but in the face of his insistence that she simply doesn't understand how to use the products, she's unsure. She needs some kind of proof of the abuse.
You may want to make multiple survivor archetypes to capture a range of different experiences. They may know that the abuse is happening but not be able to stop it, like when an abuser locks them out of IoT devices; or they know it's happening but don't know how, such as when a stalker keeps figuring out their location (Fig 5.4). Include as many of these scenarios as you need to in your survivor archetype. You'll use these later on when you design solutions to help your survivor archetypes achieve their goals of preventing and ending abuse.
 Fig 5.4: The survivor archetype Eric Mitchell knows he's being stalked by his ex-boyfriend Rob but can't figure out how Rob is learning his location information.
Fig 5.4: The survivor archetype Eric Mitchell knows he's being stalked by his ex-boyfriend Rob but can't figure out how Rob is learning his location information.
It may be useful for you to create persona-like artifacts for your archetypes, such as the three examples shown. Instead of focusing on the demographic information we often see in personas, focus on their goals. The goals of the abuser will be to carry out the specific abuse you've identified, while the goals of the survivor will be to prevent abuse, understand that abuse is happening, make ongoing abuse stop, or regain control over the technology that's being used for abuse. Later, you'll brainstorm how to prevent the abuser's goals and assist the survivor's goals.
And while the "abuser/survivor" model fits most cases, it doesn't fit all, so modify it as you need to. For example, if you uncovered an issue with security, such as the ability for someone to hack into a home camera system and talk to children, the malicious hacker would get the abuser archetype and the child's parents would get survivor archetype.
Step 3: Brainstorm problemsAfter creating archetypes, brainstorm novel abuse cases and safety issues. "Novel" means things not found in your research; you're trying to identify completely new safety issues that are unique to your product or service. The goal with this step is to exhaust every effort of identifying harms your product could cause. You aren't worrying about how to prevent the harm yet—that comes in the next step.
How could your product be used for any kind of abuse, outside of what you've already identified in your research? I recommend setting aside at least a few hours with your team for this process.
If you're looking for somewhere to start, try doing a Black Mirror brainstorm. This exercise is based on the show Black Mirror, which features stories about the dark possibilities of technology. Try to figure out how your product would be used in an episode of the show—the most wild, awful, out-of-control ways it could be used for harm. When I've led Black Mirror brainstorms, participants usually end up having a good deal of fun (which I think is great—it's okay to have fun when designing for safety!). I recommend time-boxing a Black Mirror brainstorm to half an hour, and then dialing it back and using the rest of the time thinking of more realistic forms of harm.
After you've identified as many opportunities for abuse as possible, you may still not feel confident that you've uncovered every potential form of harm. A healthy amount of anxiety is normal when you're doing this kind of work. It's common for teams designing for safety to worry, "Have we really identified every possible harm? What if we've missed something?" If you've spent at least four hours coming up with ways your product could be used for harm and have run out of ideas, go to the next step.
It's impossible to guarantee you've thought of everything; instead of aiming for 100 percent assurance, recognize that you've taken this time and have done the best you can, and commit to continuing to prioritize safety in the future. Once your product is released, your users may identify new issues that you missed; aim to receive that feedback graciously and course-correct quickly.
Step 4: Design solutionsAt this point, you should have a list of ways your product can be used for harm as well as survivor and abuser archetypes describing opposing user goals. The next step is to identify ways to design against the identified abuser's goals and to support the survivor's goals. This step is a good one to insert alongside existing parts of your design process where you're proposing solutions for the various problems your research uncovered.
Some questions to ask yourself to help prevent harm and support your archetypes include:
- Can you design your product in such a way that the identified harm cannot happen in the first place? If not, what roadblocks can you put up to prevent the harm from happening?
- How can you make the victim aware that abuse is happening through your product?
- How can you help the victim understand what they need to do to make the problem stop?
- Can you identify any types of user activity that would indicate some form of harm or abuse? Could your product help the user access support?
In some products, it's possible to proactively recognize that harm is happening. For example, a pregnancy app might be modified to allow the user to report that they were the victim of an assault, which could trigger an offer to receive resources for local and national organizations. This sort of proactiveness is not always possible, but it's worth taking a half hour to discuss if any type of user activity would indicate some form of harm or abuse, and how your product could assist the user in receiving help in a safe manner.
That said, use caution: you don't want to do anything that could put a user in harm's way if their devices are being monitored. If you do offer some kind of proactive help, always make it voluntary, and think through other safety issues, such as the need to keep the user in-app in case an abuser is checking their search history. We'll walk through a good example of this in the next chapter.
Step 5: Test for safetyThe final step is to test your prototypes from the point of view of your archetypes: the person who wants to weaponize the product for harm and the victim of the harm who needs to regain control over the technology. Just like any other kind of product testing, at this point you'll aim to rigorously test out your safety solutions so that you can identify gaps and correct them, validate that your designs will help keep your users safe, and feel more confident releasing your product into the world.
Ideally, safety testing happens along with usability testing. If you're at a company that doesn't do usability testing, you might be able to use safety testing to cleverly perform both; a user who goes through your design attempting to weaponize the product against someone else can also be encouraged to point out interactions or other elements of the design that don't make sense to them.
You'll want to conduct safety testing on either your final prototype or the actual product if it's already been released. There's nothing wrong with testing an existing product that wasn't designed with safety goals in mind from the onset—"retrofitting" it for safety is a good thing to do.
Remember that testing for safety involves testing from the perspective of both an abuser and a survivor, though it may not make sense for you to do both. Alternatively, if you made multiple survivor archetypes to capture multiple scenarios, you'll want to test from the perspective of each one.
As with other sorts of usability testing, you as the designer are most likely too close to the product and its design by this point to be a valuable tester; you know the product too well. Instead of doing it yourself, set up testing as you would with other usability testing: find someone who is not familiar with the product and its design, set the scene, give them a task, encourage them to think out loud, and observe how they attempt to complete it.
Abuser testingThe goal of this testing is to understand how easy it is for someone to weaponize your product for harm. Unlike with usability testing, you want to make it impossible, or at least difficult, for them to achieve their goal. Reference the goals in the abuser archetype you created earlier, and use your product in an attempt to achieve them.
For example, for a fitness app with GPS-enabled location features, we can imagine that the abuser archetype would have the goal of figuring out where his ex-girlfriend now lives. With this goal in mind, you'd try everything possible to figure out the location of another user who has their privacy settings enabled. You might try to see her running routes, view any available information on her profile, view anything available about her location (which she has set to private), and investigate the profiles of any other users somehow connected with her account, such as her followers.
If by the end of this you've managed to uncover some of her location data, despite her having set her profile to private, you know now that your product enables stalking. Your next step is to go back to step 4 and figure out how to prevent this from happening. You may need to repeat the process of designing solutions and testing them more than once.
Survivor testingSurvivor testing involves identifying how to give information and power to the survivor. It might not always make sense based on the product or context. Thwarting the attempt of an abuser archetype to stalk someone also satisfies the goal of the survivor archetype to not be stalked, so separate testing wouldn't be needed from the survivor's perspective.
However, there are cases where it makes sense. For example, for a smart thermostat, a survivor archetype's goals would be to understand who or what is making the temperature change when they aren't doing it themselves. You could test this by looking for the thermostat's history log and checking for usernames, actions, and times; if you couldn't find that information, you would have more work to do in step 4.
Another goal might be regaining control of the thermostat once the survivor realizes the abuser is remotely changing its settings. Your test would involve attempting to figure out how to do this: are there instructions that explain how to remove another user and change the password, and are they easy to find? This might again reveal that more work is needed to make it clear to the user how they can regain control of the device or account.
Stress testingTo make your product more inclusive and compassionate, consider adding stress testing. This concept comes from Design for Real Life by Eric Meyer and Sara Wachter-Boettcher. The authors pointed out that personas typically center people who are having a good day—but real users are often anxious, stressed out, having a bad day, or even experiencing tragedy. These are called "stress cases," and testing your products for users in stress-case situations can help you identify places where your design lacks compassion. Design for Real Life has more details about what it looks like to incorporate stress cases into your design as well as many other great tactics for compassionate design.
In the 1950s, many in the elite running community had begun to believe it wasn't possible to run a mile in less than four minutes. Runners had been attempting it since the late 19th century and were beginning to draw the conclusion that the human body simply wasn't built for the task.
But on May 6, 1956, Roger Bannister took everyone by surprise. It was a cold, wet day in Oxford, England—conditions no one expected to lend themselves to record-setting—and yet Bannister did just that, running a mile in 3:59.4 and becoming the first person in the record books to run a mile in under four minutes.
This shift in the benchmark had profound effects; the world now knew that the four-minute mile was possible. Bannister's record lasted only forty-six days, when it was snatched away by Australian runner John Landy. Then a year later, three runners all beat the four-minute barrier together in the same race. Since then, over 1,400 runners have officially run a mile in under four minutes; the current record is 3:43.13, held by Moroccan athlete Hicham El Guerrouj.
We achieve far more when we believe that something is possible, and we will believe it's possible only when we see someone else has already done it—and as with human running speed, so it is with what we believe are the hard limits for how a website needs to perform.
Establishing standards for a sustainable webIn most major industries, the key metrics of environmental performance are fairly well established, such as miles per gallon for cars or energy per square meter for homes. The tools and methods for calculating those metrics are standardized as well, which keeps everyone on the same page when doing environmental assessments. In the world of websites and apps, however, we aren't held to any particular environmental standards, and only recently have gained the tools and methods we need to even make an environmental assessment.
The primary goal in sustainable web design is to reduce carbon emissions. However, it's almost impossible to actually measure the amount of CO2 produced by a web product. We can't measure the fumes coming out of the exhaust pipes on our laptops. The emissions of our websites are far away, out of sight and out of mind, coming out of power stations burning coal and gas. We have no way to trace the electrons from a website or app back to the power station where the electricity is being generated and actually know the exact amount of greenhouse gas produced. So what do we do?
If we can't measure the actual carbon emissions, then we need to find what we can measure. The primary factors that could be used as indicators of carbon emissions are:
- Data transfer
- Carbon intensity of electricity
Let's take a look at how we can use these metrics to quantify the energy consumption, and in turn the carbon footprint, of the websites and web apps we create.
Data transferMost researchers use kilowatt-hours per gigabyte (kWh/GB) as a metric of energy efficiency when measuring the amount of data transferred over the internet when a website or application is used. This provides a great reference point for energy consumption and carbon emissions. As a rule of thumb, the more data transferred, the more energy used in the data center, telecoms networks, and end user devices.
For web pages, data transfer for a single visit can be most easily estimated by measuring the page weight, meaning the transfer size of the page in kilobytes the first time someone visits the page. It's fairly easy to measure using the developer tools in any modern web browser. Often your web hosting account will include statistics for the total data transfer of any web application (Fig 2.1).
 Fig 2.1: The Kinsta hosting dashboard displays data transfer alongside traffic volumes. If you divide data transfer by visits, you get the average data per visit, which can be used as a metric of efficiency.
Fig 2.1: The Kinsta hosting dashboard displays data transfer alongside traffic volumes. If you divide data transfer by visits, you get the average data per visit, which can be used as a metric of efficiency.
The nice thing about page weight as a metric is that it allows us to compare the efficiency of web pages on a level playing field without confusing the issue with constantly changing traffic volumes.
Reducing page weight requires a large scope. By early 2020, the median page weight was 1.97 MB for setups the HTTP Archive classifies as "desktop" and 1.77 MB for "mobile," with desktop increasing 36 percent since January 2016 and mobile page weights nearly doubling in the same period (Fig 2.2). Roughly half of this data transfer is image files, making images the single biggest source of carbon emissions on the average website.
History clearly shows us that our web pages can be smaller, if only we set our minds to it. While most technologies become ever more energy efficient, including the underlying technology of the web such as data centers and transmission networks, websites themselves are a technology that becomes less efficient as time goes on.
 Fig 2.2: The historical page weight data from HTTP Archive can teach us a lot about what is possible in the future.
Fig 2.2: The historical page weight data from HTTP Archive can teach us a lot about what is possible in the future.
You might be familiar with the concept of performance budgeting as a way of focusing a project team on creating faster user experiences. For example, we might specify that the website must load in a maximum of one second on a broadband connection and three seconds on a 3G connection. Much like speed limits while driving, performance budgets are upper limits rather than vague suggestions, so the goal should always be to come in under budget.
Designing for fast performance does often lead to reduced data transfer and emissions, but it isn't always the case. Web performance is often more about the subjective perception of load times than it is about the true efficiency of the underlying system, whereas page weight and transfer size are more objective measures and more reliable benchmarks for sustainable web design.
We can set a page weight budget in reference to a benchmark of industry averages, using data from sources like HTTP Archive. We can also benchmark page weight against competitors or the old version of the website we're replacing. For example, we might set a maximum page weight budget as equal to our most efficient competitor, or we could set the benchmark lower to guarantee we are best in class.
If we want to take it to the next level, then we could also start looking at the transfer size of our web pages for repeat visitors. Although page weight for the first time someone visits is the easiest thing to measure, and easy to compare on a like-for-like basis, we can learn even more if we start looking at transfer size in other scenarios too. For example, visitors who load the same page multiple times will likely have a high percentage of the files cached in their browser, meaning they don't need to transfer all of the files on subsequent visits. Likewise, a visitor who navigates to new pages on the same website will likely not need to load the full page each time, as some global assets from areas like the header and footer may already be cached in their browser. Measuring transfer size at this next level of detail can help us learn even more about how we can optimize efficiency for users who regularly visit our pages, and enable us to set page weight budgets for additional scenarios beyond the first visit.
Page weight budgets are easy to track throughout a design and development process. Although they don't actually tell us carbon emission and energy consumption analytics directly, they give us a clear indication of efficiency relative to other websites. And as transfer size is an effective analog for energy consumption, we can actually use it to estimate energy consumption too.
In summary, reduced data transfer translates to energy efficiency, a key factor to reducing carbon emissions of web products. The more efficient our products, the less electricity they use, and the less fossil fuels need to be burned to produce the electricity to power them. But as we'll see next, since all web products demand some power, it's important to consider the source of that electricity, too.
Carbon intensity of electricityRegardless of energy efficiency, the level of pollution caused by digital products depends on the carbon intensity of the energy being used to power them. Carbon intensity is a term used to define the grams of CO2 produced for every kilowatt-hour of electricity (gCO2/kWh). This varies widely, with renewable energy sources and nuclear having an extremely low carbon intensity of less than 10 gCO2/kWh (even when factoring in their construction); whereas fossil fuels have very high carbon intensity of approximately 200-400 gCO2/kWh.
Most electricity comes from national or state grids, where energy from a variety of different sources is mixed together with varying levels of carbon intensity. The distributed nature of the internet means that a single user of a website or app might be using energy from multiple different grids simultaneously; a website user in Paris uses electricity from the French national grid to power their home internet and devices, but the website's data center could be in Dallas, USA, pulling electricity from the Texas grid, while the telecoms networks use energy from everywhere between Dallas and Paris.
We don't have control over the full energy supply of web services, but we do have some control over where we host our projects. With a data center using a significant proportion of the energy of any website, locating the data center in an area with low carbon energy will tangibly reduce its carbon emissions. Danish startup Tomorrow reports and maps this user-contributed data, and a glance at their map shows how, for example, choosing a data center in France will have significantly lower carbon emissions than a data center in the Netherlands (Fig 2.3).
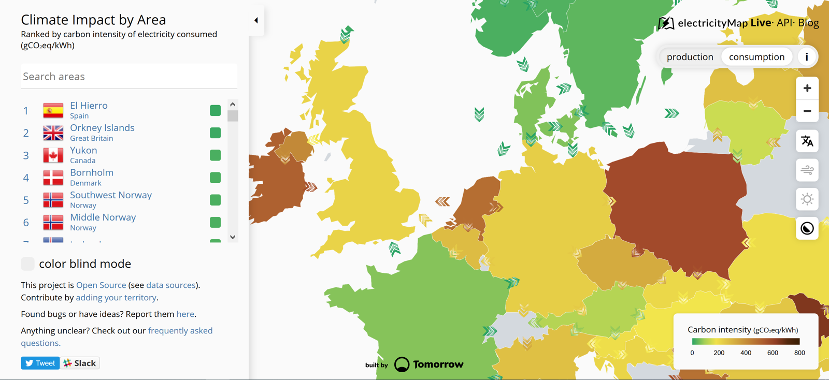 Fig 2.3: Tomorrow's electricityMap shows live data for the carbon intensity of electricity by country.
Fig 2.3: Tomorrow's electricityMap shows live data for the carbon intensity of electricity by country.
That said, we don't want to locate our servers too far away from our users; it takes energy to transmit data through the telecom's networks, and the further the data travels, the more energy is consumed. Just like food miles, we can think of the distance from the data center to the website's core user base as "megabyte miles"—and we want it to be as small as possible.
Using the distance itself as a benchmark, we can use website analytics to identify the country, state, or even city where our core user group is located and measure the distance from that location to the data center used by our hosting company. This will be a somewhat fuzzy metric as we don't know the precise center of mass of our users or the exact location of a data center, but we can at least get a rough idea.
For example, if a website is hosted in London but the primary user base is on the West Coast of the USA, then we could look up the distance from London to San Francisco, which is 5,300 miles. That's a long way! We can see that hosting it somewhere in North America, ideally on the West Coast, would significantly reduce the distance and thus the energy used to transmit the data. In addition, locating our servers closer to our visitors helps reduce latency and delivers better user experience, so it's a win-win.
Converting it back to carbon emissionsIf we combine carbon intensity with a calculation for energy consumption, we can calculate the carbon emissions of our websites and apps. A tool my team created does this by measuring the data transfer over the wire when loading a web page, calculating the amount of electricity associated, and then converting that into a figure for CO2 (Fig 2.4). It also factors in whether or not the web hosting is powered by renewable energy.
If you want to take it to the next level and tailor the data more accurately to the unique aspects of your project, the Energy and Emissions Worksheet accompanying this book shows you how.
 Fig 2.4: The Website Carbon Calculator shows how the Riverford Organic website embodies their commitment to sustainability, being both low carbon and hosted in a data center using renewable energy.
Fig 2.4: The Website Carbon Calculator shows how the Riverford Organic website embodies their commitment to sustainability, being both low carbon and hosted in a data center using renewable energy.
With the ability to calculate carbon emissions for our projects, we could actually take a page weight budget one step further and set carbon budgets as well. CO2 is not a metric commonly used in web projects; we're more familiar with kilobytes and megabytes, and can fairly easily look at design options and files to assess how big they are. Translating that into carbon adds a layer of abstraction that isn't as intuitive—but carbon budgets do focus our minds on the primary thing we're trying to reduce, and support the core objective of sustainable web design: reducing carbon emissions.
Browser EnergyData transfer might be the simplest and most complete analog for energy consumption in our digital projects, but by giving us one number to represent the energy used in the data center, the telecoms networks, and the end user's devices, it can't offer us insights into the efficiency in any specific part of the system.
One part of the system we can look at in more detail is the energy used by end users' devices. As front-end web technologies become more advanced, the computational load is increasingly moving from the data center to users' devices, whether they be phones, tablets, laptops, desktops, or even smart TVs. Modern web browsers allow us to implement more complex styling and animation on the fly using CSS and JavaScript. Furthermore, JavaScript libraries such as Angular and React allow us to create applications where the "thinking" work is done partly or entirely in the browser.
All of these advances are exciting and open up new possibilities for what the web can do to serve society and create positive experiences. However, more computation in the user's web browser means more energy used by their devices. This has implications not just environmentally, but also for user experience and inclusivity. Applications that put a heavy processing load on the user's device can inadvertently exclude users with older, slower devices and cause batteries on phones and laptops to drain faster. Furthermore, if we build web applications that require the user to have up-to-date, powerful devices, people throw away old devices much more frequently. This isn't just bad for the environment, but it puts a disproportionate financial burden on the poorest in society.
In part because the tools are limited, and partly because there are so many different models of devices, it's difficult to measure website energy consumption on end users' devices. One tool we do currently have is the Energy Impact monitor inside the developer console of the Safari browser (Fig 2.5).
 Fig 2.5: The Energy Impact meter in Safari (on the right) shows how a website consumes CPU energy.
Fig 2.5: The Energy Impact meter in Safari (on the right) shows how a website consumes CPU energy.
You know when you load a website and your computer's cooling fans start spinning so frantically you think it might actually take off? That's essentially what this tool is measuring.
It shows us the percentage of CPU used and the duration of CPU usage when loading the web page, and uses these figures to generate an energy impact rating. It doesn't give us precise data for the amount of electricity used in kilowatts, but the information it does provide can be used to benchmark how efficiently your websites use energy and set targets for improvement.
We've been having conversations for thousands of years. Whether to convey information, conduct transactions, or simply to check in on one another, people have yammered away, chattering and gesticulating, through spoken conversation for countless generations. Only in the last few millennia have we begun to commit our conversations to writing, and only in the last few decades have we begun to outsource them to the computer, a machine that shows much more affinity for written correspondence than for the slangy vagaries of spoken language.
Computers have trouble because between spoken and written language, speech is more primordial. To have successful conversations with us, machines must grapple with the messiness of human speech: the disfluencies and pauses, the gestures and body language, and the variations in word choice and spoken dialect that can stymie even the most carefully crafted human-computer interaction. In the human-to-human scenario, spoken language also has the privilege of face-to-face contact, where we can readily interpret nonverbal social cues.
In contrast, written language immediately concretizes as we commit it to record and retains usages long after they become obsolete in spoken communication (the salutation "To whom it may concern," for example), generating its own fossil record of outdated terms and phrases. Because it tends to be more consistent, polished, and formal, written text is fundamentally much easier for machines to parse and understand.
Spoken language has no such luxury. Besides the nonverbal cues that decorate conversations with emphasis and emotional context, there are also verbal cues and vocal behaviors that modulate conversation in nuanced ways: how something is said, not what. Whether rapid-fire, low-pitched, or high-decibel, whether sarcastic, stilted, or sighing, our spoken language conveys much more than the written word could ever muster. So when it comes to voice interfaces—the machines we conduct spoken conversations with—we face exciting challenges as designers and content strategists.
Voice InteractionsWe interact with voice interfaces for a variety of reasons, but according to Michael McTear, Zoraida Callejas, and David Griol in The Conversational Interface, those motivations by and large mirror the reasons we initiate conversations with other people, too (http://bkaprt.com/vcu36/01-01). Generally, we start up a conversation because:
- we need something done (such as a transaction),
- we want to know something (information of some sort), or
- we are social beings and want someone to talk to (conversation for conversation's sake).
These three categories—which I call transactional, informational, and prosocial—also characterize essentially every voice interaction: a single conversation from beginning to end that realizes some outcome for the user, starting with the voice interface's first greeting and ending with the user exiting the interface. Note here that a conversation in our human sense—a chat between people that leads to some result and lasts an arbitrary length of time—could encompass multiple transactional, informational, and prosocial voice interactions in succession. In other words, a voice interaction is a conversation, but a conversation is not necessarily a single voice interaction.
Purely prosocial conversations are more gimmicky than captivating in most voice interfaces, because machines don't yet have the capacity to really want to know how we're doing and to do the sort of glad-handing humans crave. There's also ongoing debate as to whether users actually prefer the sort of organic human conversation that begins with a prosocial voice interaction and shifts seamlessly into other types. In fact, in Voice User Interface Design, Michael Cohen, James Giangola, and Jennifer Balogh recommend sticking to users' expectations by mimicking how they interact with other voice interfaces rather than trying too hard to be human—potentially alienating them in the process (http://bkaprt.com/vcu36/01-01).
That leaves two genres of conversations we can have with one another that a voice interface can easily have with us, too: a transactional voice interaction realizing some outcome ("buy iced tea") and an informational voice interaction teaching us something new ("discuss a musical").
Transactional voice interactionsUnless you're tapping buttons on a food delivery app, you're generally having a conversation—and therefore a voice interaction—when you order a Hawaiian pizza with extra pineapple. Even when we walk up to the counter and place an order, the conversation quickly pivots from an initial smattering of neighborly small talk to the real mission at hand: ordering a pizza (generously topped with pineapple, as it should be).
Alison: Hey, how's it going?
Burhan: Hi, welcome to Crust Deluxe! It's cold out there. How can I help you?
Alison: Can I get a Hawaiian pizza with extra pineapple?
Burhan: Sure, what size?
Alison: Large.
Burhan: Anything else?
Alison: No thanks, that's it.
Burhan: Something to drink?
Alison: I'll have a bottle of Coke.
Burhan: You got it. That'll be $13.55 and about fifteen minutes.
Each progressive disclosure in this transactional conversation reveals more and more of the desired outcome of the transaction: a service rendered or a product delivered. Transactional conversations have certain key traits: they're direct, to the point, and economical. They quickly dispense with pleasantries.
Informational voice interactionsMeanwhile, some conversations are primarily about obtaining information. Though Alison might visit Crust Deluxe with the sole purpose of placing an order, she might not actually want to walk out with a pizza at all. She might be just as interested in whether they serve halal or kosher dishes, gluten-free options, or something else. Here, though we again have a prosocial mini-conversation at the beginning to establish politeness, we're after much more.
Alison: Hey, how's it going?
Burhan: Hi, welcome to Crust Deluxe! It's cold out there. How can I help you?
Alison: Can I ask a few questions?
Burhan: Of course! Go right ahead.
Alison: Do you have any halal options on the menu?
Burhan: Absolutely! We can make any pie halal by request. We also have lots of vegetarian, ovo-lacto, and vegan options. Are you thinking about any other dietary restrictions?
Alison: What about gluten-free pizzas?
Burhan: We can definitely do a gluten-free crust for you, no problem, for both our deep-dish and thin-crust pizzas. Anything else I can answer for you?
Alison: That's it for now. Good to know. Thanks!
Burhan: Anytime, come back soon!
This is a very different dialogue. Here, the goal is to get a certain set of facts. Informational conversations are investigative quests for the truth—research expeditions to gather data, news, or facts. Voice interactions that are informational might be more long-winded than transactional conversations by necessity. Responses tend to be lengthier, more informative, and carefully communicated so the customer understands the key takeaways.
Voice InterfacesAt their core, voice interfaces employ speech to support users in reaching their goals. But simply because an interface has a voice component doesn't mean that every user interaction with it is mediated through voice. Because multimodal voice interfaces can lean on visual components like screens as crutches, we're most concerned in this book with pure voice interfaces, which depend entirely on spoken conversation, lack any visual component whatsoever, and are therefore much more nuanced and challenging to tackle.
Though voice interfaces have long been integral to the imagined future of humanity in science fiction, only recently have those lofty visions become fully realized in genuine voice interfaces.
Interactive voice response (IVR) systemsThough written conversational interfaces have been fixtures of computing for many decades, voice interfaces first emerged in the early 1990s with text-to-speech (TTS) dictation programs that recited written text aloud, as well as speech-enabled in-car systems that gave directions to a user-provided address. With the advent of interactive voice response (IVR) systems, intended as an alternative to overburdened customer service representatives, we became acquainted with the first true voice interfaces that engaged in authentic conversation.
IVR systems allowed organizations to reduce their reliance on call centers but soon became notorious for their clunkiness. Commonplace in the corporate world, these systems were primarily designed as metaphorical switchboards to guide customers to a real phone agent ("Say Reservations to book a flight or check an itinerary"); chances are you will enter a conversation with one when you call an airline or hotel conglomerate. Despite their functional issues and users' frustration with their inability to speak to an actual human right away, IVR systems proliferated in the early 1990s across a variety of industries (http://bkaprt.com/vcu36/01-02, PDF).
While IVR systems are great for highly repetitive, monotonous conversations that generally don't veer from a single format, they have a reputation for less scintillating conversation than we're used to in real life (or even in science fiction).
Screen readersParallel to the evolution of IVR systems was the invention of the screen reader, a tool that transcribes visual content into synthesized speech. For Blind or visually impaired website users, it's the predominant method of interacting with text, multimedia, or form elements. Screen readers represent perhaps the closest equivalent we have today to an out-of-the-box implementation of content delivered through voice.
Among the first screen readers known by that moniker was the Screen Reader for the BBC Micro and NEEC Portable developed by the Research Centre for the Education of the Visually Handicapped (RCEVH) at the University of Birmingham in 1986 (http://bkaprt.com/vcu36/01-03). That same year, Jim Thatcher created the first IBM Screen Reader for text-based computers, later recreated for computers with graphical user interfaces (GUIs) (http://bkaprt.com/vcu36/01-04).
With the rapid growth of the web in the 1990s, the demand for accessible tools for websites exploded. Thanks to the introduction of semantic HTML and especially ARIA roles beginning in 2008, screen readers started facilitating speedy interactions with web pages that ostensibly allow disabled users to traverse the page as an aural and temporal space rather than a visual and physical one. In other words, screen readers for the web "provide mechanisms that translate visual design constructs—proximity, proportion, etc.—into useful information," writes Aaron Gustafson in A List Apart. "At least they do when documents are authored thoughtfully" (http://bkaprt.com/vcu36/01-05).
Though deeply instructive for voice interface designers, there's one significant problem with screen readers: they're difficult to use and unremittingly verbose. The visual structures of websites and web navigation don't translate well to screen readers, sometimes resulting in unwieldy pronouncements that name every manipulable HTML element and announce every formatting change. For many screen reader users, working with web-based interfaces exacts a cognitive toll.
In Wired, accessibility advocate and voice engineer Chris Maury considers why the screen reader experience is ill-suited to users relying on voice:
From the beginning, I hated the way that Screen Readers work. Why are they designed the way they are? It makes no sense to present information visually and then, and only then, translate that into audio. All of the time and energy that goes into creating the perfect user experience for an app is wasted, or even worse, adversely impacting the experience for blind users. (http://bkaprt.com/vcu36/01-06)
In many cases, well-designed voice interfaces can speed users to their destination better than long-winded screen reader monologues. After all, visual interface users have the benefit of darting around the viewport freely to find information, ignoring areas irrelevant to them. Blind users, meanwhile, are obligated to listen to every utterance synthesized into speech and therefore prize brevity and efficiency. Disabled users who have long had no choice but to employ clunky screen readers may find that voice interfaces, particularly more modern voice assistants, offer a more streamlined experience.
Voice assistantsWhen we think of voice assistants (the subset of voice interfaces now commonplace in living rooms, smart homes, and offices), many of us immediately picture HAL from 2001: A Space Odyssey or hear Majel Barrett's voice as the omniscient computer in Star Trek. Voice assistants are akin to personal concierges that can answer questions, schedule appointments, conduct searches, and perform other common day-to-day tasks. And they're rapidly gaining more attention from accessibility advocates for their assistive potential.
Before the earliest IVR systems found success in the enterprise, Apple published a demonstration video in 1987 depicting the Knowledge Navigator, a voice assistant that could transcribe spoken words and recognize human speech to a great degree of accuracy. Then, in 2001, Tim Berners-Lee and others formulated their vision for a Semantic Web "agent" that would perform typical errands like "checking calendars, making appointments, and finding locations" (http://bkaprt.com/vcu36/01-07, behind paywall). It wasn't until 2011 that Apple's Siri finally entered the picture, making voice assistants a tangible reality for consumers.
Thanks to the plethora of voice assistants available today, there is considerable variation in how programmable and customizable certain voice assistants are over others (Fig 1.1). At one extreme, everything except vendor-provided features is locked down; for example, at the time of their release, the core functionality of Apple's Siri and Microsoft's Cortana couldn't be extended beyond their existing capabilities. Even today, it isn't possible to program Siri to perform arbitrary functions, because there's no means by which developers can interact with Siri at a low level, apart from predefined categories of tasks like sending messages, hailing rideshares, making restaurant reservations, and certain others.
At the opposite end of the spectrum, voice assistants like Amazon Alexa and Google Home offer a core foundation on which developers can build custom voice interfaces. For this reason, programmable voice assistants that lend themselves to customization and extensibility are becoming increasingly popular for developers who feel stifled by the limitations of Siri and Cortana. Amazon offers the Alexa Skills Kit, a developer framework for building custom voice interfaces for Amazon Alexa, while Google Home offers the ability to program arbitrary Google Assistant skills. Today, users can choose from among thousands of custom-built skills within both the Amazon Alexa and Google Assistant ecosystems.
 Fig 1.1: Voice assistants like Amazon Alexa and Google Home tend to be more programmable, and thus more flexible, than their counterpart Apple Siri.
Fig 1.1: Voice assistants like Amazon Alexa and Google Home tend to be more programmable, and thus more flexible, than their counterpart Apple Siri.
As corporations like Amazon, Apple, Microsoft, and Google continue to stake their territory, they're also selling and open-sourcing an unprecedented array of tools and frameworks for designers and developers that aim to make building voice interfaces as easy as possible, even without code.
Often by necessity, voice assistants like Amazon Alexa tend to be monochannel—they're tightly coupled to a device and can't be accessed on a computer or smartphone instead. By contrast, many development platforms like Google's Dialogflow have introduced omnichannel capabilities so users can build a single conversational interface that then manifests as a voice interface, textual chatbot, and IVR system upon deployment. I don't prescribe any specific implementation approaches in this design-focused book, but in Chapter 4 we'll get into some of the implications these variables might have on the way you build out your design artifacts.
Voice ContentSimply put, voice content is content delivered through voice. To preserve what makes human conversation so compelling in the first place, voice content needs to be free-flowing and organic, contextless and concise—everything written content isn't.
Our world is replete with voice content in various forms: screen readers reciting website content, voice assistants rattling off a weather forecast, and automated phone hotline responses governed by IVR systems. In this book, we're most concerned with content delivered auditorily—not as an option, but as a necessity.
For many of us, our first foray into informational voice interfaces will be to deliver content to users. There's only one problem: any content we already have isn't in any way ready for this new habitat. So how do we make the content trapped on our websites more conversational? And how do we write new copy that lends itself to voice interactions?
Lately, we've begun slicing and dicing our content in unprecedented ways. Websites are, in many respects, colossal vaults of what I call macrocontent: lengthy prose that can extend for infinitely scrollable miles in a browser window, like microfilm viewers of newspaper archives. Back in 2002, well before the present-day ubiquity of voice assistants, technologist Anil Dash defined microcontent as permalinked pieces of content that stay legible regardless of environment, such as email or text messages:
A day's weather forcast [sic], the arrival and departure times for an airplane flight, an abstract from a long publication, or a single instant message can all be examples of microcontent. (http://bkaprt.com/vcu36/01-08)
I'd update Dash's definition of microcontent to include all examples of bite-sized content that go well beyond written communiqués. After all, today we encounter microcontent in interfaces where a small snippet of copy is displayed alone, unmoored from the browser, like a textbot confirmation of a restaurant reservation. Microcontent offers the best opportunity to gauge how your content can be stretched to the very edges of its capabilities, informing delivery channels both established and novel.
As microcontent, voice content is unique because it's an example of how content is experienced in time rather than in space. We can glance at a digital sign underground for an instant and know when the next train is arriving, but voice interfaces hold our attention captive for periods of time that we can't easily escape or skip, something screen reader users are all too familiar with.
Because microcontent is fundamentally made up of isolated blobs with no relation to the channels where they'll eventually end up, we need to ensure that our microcontent truly performs well as voice content—and that means focusing on the two most important traits of robust voice content: voice content legibility and voice content discoverability.
Fundamentally, the legibility and discoverability of our voice content both have to do with how voice content manifests in perceived time and space.
I'm not sure when I first heard this quote, but it's something that has stayed with me over the years. How do you create services for situations you can't imagine? Or design products that work on devices yet to be invented?
Flash, Photoshop, and responsive designWhen I first started designing websites, my go-to software was Photoshop. I created a 960px canvas and set about creating a layout that I would later drop content in. The development phase was about attaining pixel-perfect accuracy using fixed widths, fixed heights, and absolute positioning.
Ethan Marcotte's talk at An Event Apart and subsequent article "Responsive Web Design" in A List Apart in 2010 changed all this. I was sold on responsive design as soon as I heard about it, but I was also terrified. The pixel-perfect designs full of magic numbers that I had previously prided myself on producing were no longer good enough.
The fear wasn't helped by my first experience with responsive design. My first project was to take an existing fixed-width website and make it responsive. What I learned the hard way was that you can't just add responsiveness at the end of a project. To create fluid layouts, you need to plan throughout the design phase.
A new way to designDesigning responsive or fluid sites has always been about removing limitations, producing content that can be viewed on any device. It relies on the use of percentage-based layouts, which I initially achieved with native CSS and utility classes:
.column-span-6 {
width: 49%;
float: left;
margin-right: 0.5%;
margin-left: 0.5%;
}
.column-span-4 {
width: 32%;
float: left;
margin-right: 0.5%;
margin-left: 0.5%;
}
.column-span-3 {
width: 24%;
float: left;
margin-right: 0.5%;
margin-left: 0.5%;
}
Then with Sass so I could take advantage of @includes to re-use repeated blocks of code and move back to more semantic markup:
.logo {
@include colSpan(6);
}
.search {
@include colSpan(3);
}
.social-share {
@include colSpan(3);
}
Media queries
The second ingredient for responsive design is media queries. Without them, content would shrink to fit the available space regardless of whether that content remained readable (The exact opposite problem occurred with the introduction of a mobile-first approach).
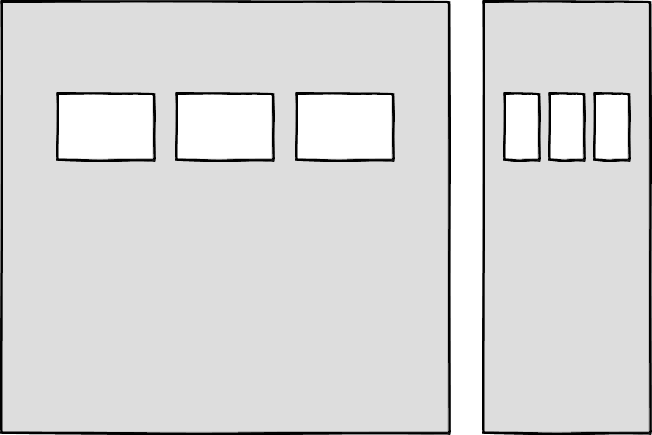 Components becoming too small at mobile breakpoints
Components becoming too small at mobile breakpoints
Media queries prevented this by allowing us to add breakpoints where the design could adapt. Like most people, I started out with three breakpoints: one for desktop, one for tablets, and one for mobile. Over the years, I added more and more for phablets, wide screens, and so on.
For years, I happily worked this way and improved both my design and front-end skills in the process. The only problem I encountered was making changes to content, since with our Sass grid system in place, there was no way for the site owners to add content without amending the markup—something a small business owner might struggle with. This is because each row in the grid was defined using a div as a container. Adding content meant creating new row markup, which requires a level of HTML knowledge.
Row markup was a staple of early responsive design, present in all the widely used frameworks like Bootstrap and Skeleton.
<section > <div >1 of 7</div> <div >2 of 7</div> <div >3 of 7</div> </section> <section > <div >4 of 7</div> <div >5 of 7</div> <div >6 of 7</div> </section> <section > <div >7 of 7</div> </section>
 Components placed in the rows of a Sass grid
Components placed in the rows of a Sass grid
Another problem arose as I moved from a design agency building websites for small- to medium-sized businesses, to larger in-house teams where I worked across a suite of related sites. In those roles I started to work much more with reusable components.
Our reliance on media queries resulted in components that were tied to common viewport sizes. If the goal of component libraries is reuse, then this is a real problem because you can only use these components if the devices you're designing for correspond to the viewport sizes used in the pattern library—in the process not really hitting that "devices that don't yet exist" goal.
Then there's the problem of space. Media queries allow components to adapt based on the viewport size, but what if I put a component into a sidebar, like in the figure below?
 Components responding to the viewport width with media queries
Container queries: our savior or a false dawn?
Components responding to the viewport width with media queries
Container queries: our savior or a false dawn?
Container queries have long been touted as an improvement upon media queries, but at the time of writing are unsupported in most browsers. There are JavaScript workarounds, but they can create dependency and compatibility issues. The basic theory underlying container queries is that elements should change based on the size of their parent container and not the viewport width, as seen in the following illustrations.
 Components responding to their parent container with container queries
Components responding to their parent container with container queries
One of the biggest arguments in favor of container queries is that they help us create components or design patterns that are truly reusable because they can be picked up and placed anywhere in a layout. This is an important step in moving toward a form of component-based design that works at any size on any device.
In other words, responsive components to replace responsive layouts.
Container queries will help us move from designing pages that respond to the browser or device size to designing components that can be placed in a sidebar or in the main content, and respond accordingly.
My concern is that we are still using layout to determine when a design needs to adapt. This approach will always be restrictive, as we will still need pre-defined breakpoints. For this reason, my main question with container queries is, How would we decide when to change the CSS used by a component?
A component library removed from context and real content is probably not the best place for that decision.
As the diagrams below illustrate, we can use container queries to create designs for specific container widths, but what if I want to change the design based on the image size or ratio?
 Cards responding to their parent container with container queries
Cards responding to their parent container with container queries
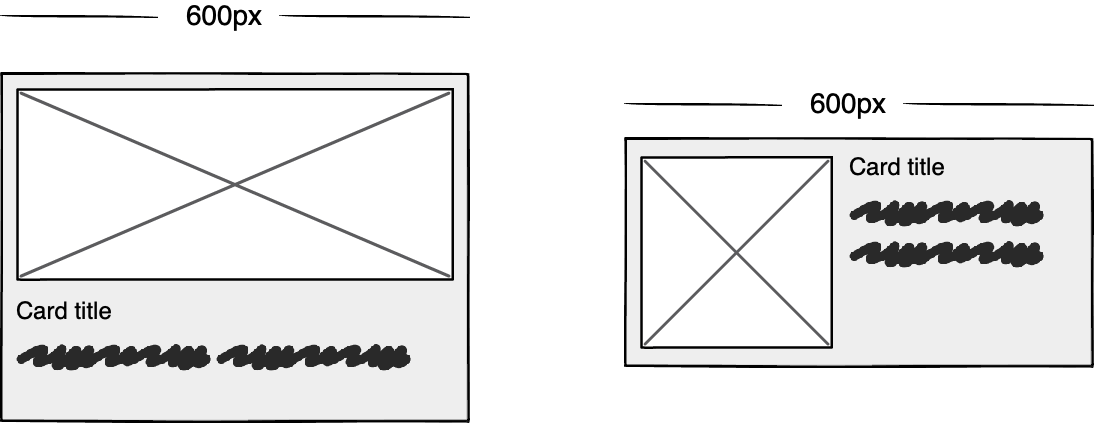 Cards responding based on their own content
Cards responding based on their own content
In this example, the dimensions of the container are not what should dictate the design; rather, the image is.
It's hard to say for sure whether container queries will be a success story until we have solid cross-browser support for them. Responsive component libraries would definitely evolve how we design and would improve the possibilities for reuse and design at scale. But maybe we will always need to adjust these components to suit our content.
CSS is changingWhilst the container query debate rumbles on, there have been numerous advances in CSS that change the way we think about design. The days of fixed-width elements measured in pixels and floated div elements used to cobble layouts together are long gone, consigned to history along with table layouts. Flexbox and CSS Grid have revolutionized layouts for the web. We can now create elements that wrap onto new rows when they run out of space, not when the device changes.
.wrapper {
display: grid;
grid-template-columns: repeat(auto-fit, 450px);
gap: 10px;
}
The repeat() function paired with auto-fit or auto-fill allows us to specify how much space each column should use while leaving it up to the browser to decide when to spill the columns onto a new line. Similar things can be achieved with Flexbox, as elements can wrap over multiple rows and "flex" to fill available space.
.wrapper {
display: flex;
flex-wrap: wrap;
justify-content: space-between;
}
.child {
flex-basis: 32%;
margin-bottom: 20px;
}
The biggest benefit of all this is you don't need to wrap elements in container rows. Without rows, content isn't tied to page markup in quite the same way, allowing for removals or additions of content without additional development.
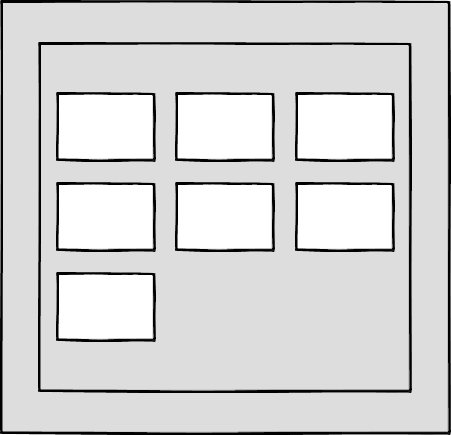 A traditional Grid layout without the usual row containers
A traditional Grid layout without the usual row containers
This is a big step forward when it comes to creating designs that allow for evolving content, but the real game changer for flexible designs is CSS Subgrid.
Remember the days of crafting perfectly aligned interfaces, only for the customer to add an unbelievably long header almost as soon as they're given CMS access, like the illustration below?
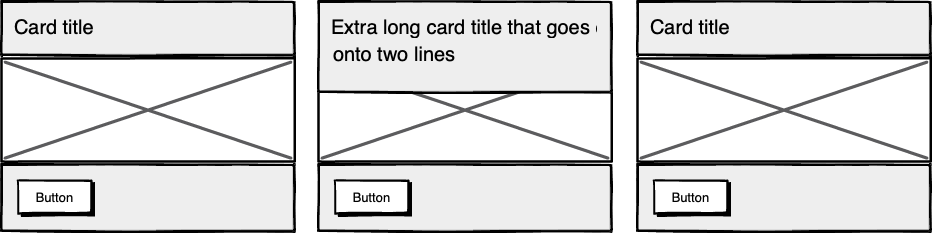 Cards unable to respond to a sibling's content changes
Cards unable to respond to a sibling's content changes
Subgrid allows elements to respond to adjustments in their own content and in the content of sibling elements, helping us create designs more resilient to change.
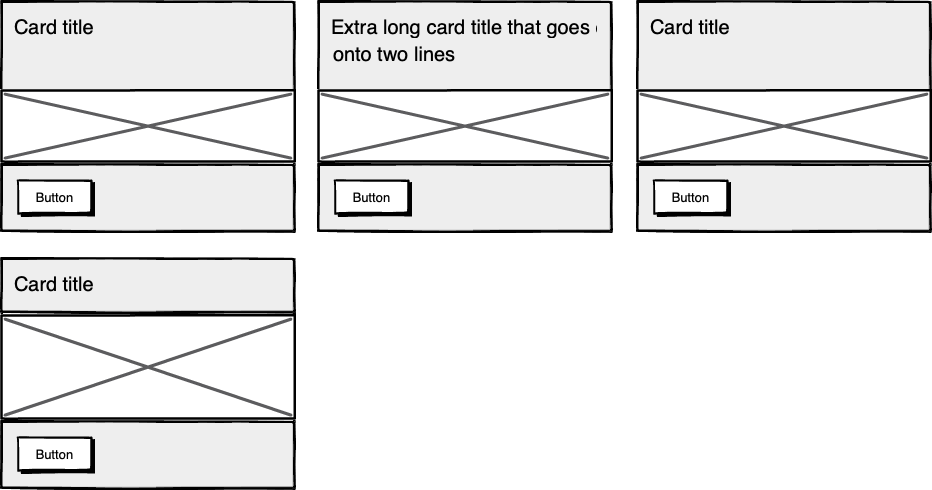 Cards responding to content in sibling cards
Cards responding to content in sibling cards
.wrapper {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(150px, 1fr));
grid-template-rows: auto 1fr auto;
gap: 10px;
}
.sub-grid {
display: grid;
grid-row: span 3;
grid-template-rows: subgrid; /* sets rows to parent grid */
}
CSS Grid allows us to separate layout and content, thereby enabling flexible designs. Meanwhile, Subgrid allows us to create designs that can adapt in order to suit morphing content. Subgrid at the time of writing is only supported in Firefox but the above code can be implemented behind an @supports feature query.
Intrinsic layoutsI'd be remiss not to mention intrinsic layouts, the term created by Jen Simmons to describe a mixture of new and old CSS features used to create layouts that respond to available space.
Responsive layouts have flexible columns using percentages. Intrinsic layouts, on the other hand, use the fr unit to create flexible columns that won't ever shrink so much that they render the content illegible.
fr units is a way to say I want you to distribute the extra space in this way, but...don't ever make it smaller than the content that's inside of it.
—Jen Simmons, "Designing Intrinsic Layouts"
Intrinsic layouts can also utilize a mixture of fixed and flexible units, allowing the content to dictate the space it takes up.
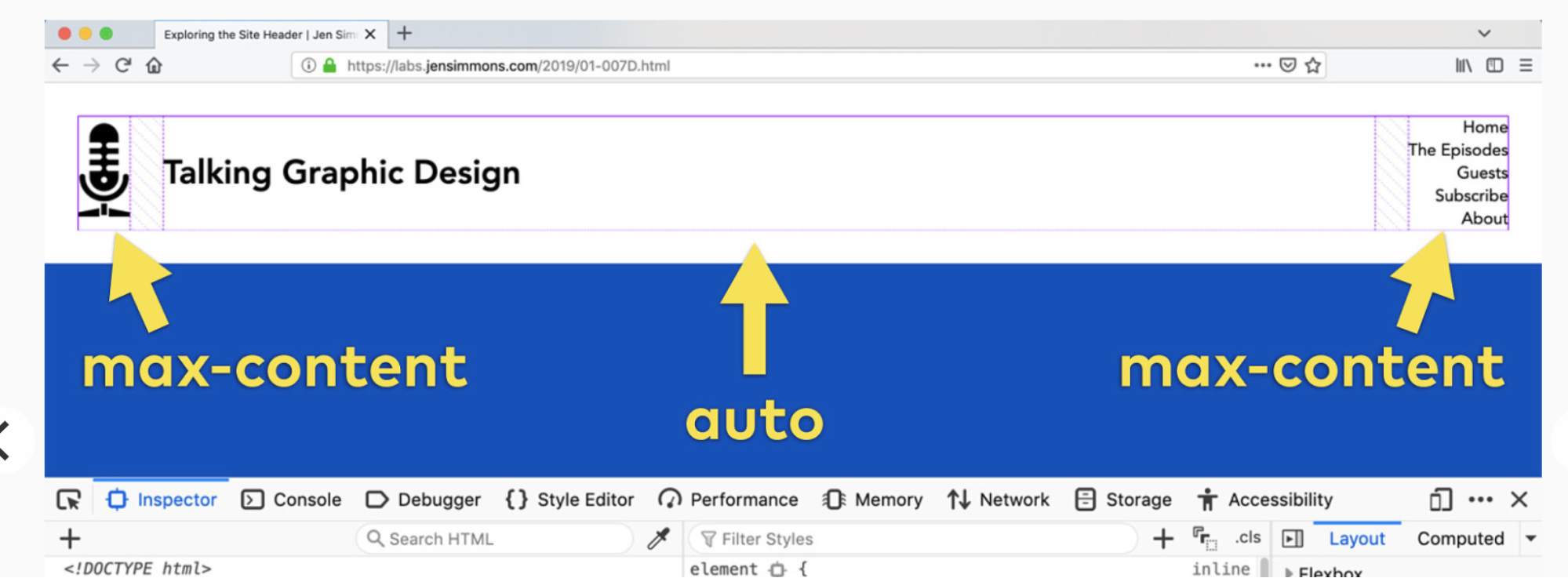 Slide from "Designing Intrinsic Layouts" by Jen Simmons
Slide from "Designing Intrinsic Layouts" by Jen Simmons
What makes intrinsic design stand out is that it not only creates designs that can withstand future devices but also helps scale design without losing flexibility. Components and patterns can be lifted and reused without the prerequisite of having the same breakpoints or the same amount of content as in the previous implementation.
We can now create designs that adapt to the space they have, the content within them, and the content around them. With an intrinsic approach, we can construct responsive components without depending on container queries.
Another 2010 moment?This intrinsic approach should in my view be every bit as groundbreaking as responsive web design was ten years ago. For me, it's another "everything changed" moment.
But it doesn't seem to be moving quite as fast; I haven't yet had that same career-changing moment I had with responsive design, despite the widely shared and brilliant talk that brought it to my attention.
One reason for that could be that I now work in a large organization, which is quite different from the design agency role I had in 2010. In my agency days, every new project was a clean slate, a chance to try something new. Nowadays, projects use existing tools and frameworks and are often improvements to existing websites with an existing codebase.
Another could be that I feel more prepared for change now. In 2010 I was new to design in general; the shift was frightening and required a lot of learning. Also, an intrinsic approach isn't exactly all-new; it's about using existing skills and existing CSS knowledge in a different way.
You can't framework your way out of a content problemAnother reason for the slightly slower adoption of intrinsic design could be the lack of quick-fix framework solutions available to kick-start the change.
Responsive grid systems were all over the place ten years ago. With a framework like Bootstrap or Skeleton, you had a responsive design template at your fingertips.
Intrinsic design and frameworks do not go hand in hand quite so well because the benefit of having a selection of units is a hindrance when it comes to creating layout templates. The beauty of intrinsic design is combining different units and experimenting with techniques to get the best for your content.
And then there are design tools. We probably all, at some point in our careers, used Photoshop templates for desktop, tablet, and mobile devices to drop designs in and show how the site would look at all three stages.
How do you do that now, with each component responding to content and layouts flexing as and when they need to? This type of design must happen in the browser, which personally I'm a big fan of.
The debate about "whether designers should code" is another that has rumbled on for years. When designing a digital product, we should, at the very least, design for a best- and worst-case scenario when it comes to content. To do this in a graphics-based software package is far from ideal. In code, we can add longer sentences, more radio buttons, and extra tabs, and watch in real time as the design adapts. Does it still work? Is the design too reliant on the current content?
Personally, I look forward to the day intrinsic design is the standard for design, when a design component can be truly flexible and adapt to both its space and content with no reliance on device or container dimensions.
Content firstContent is not constant. After all, to design for the unknown or unexpected we need to account for content changes like our earlier Subgrid card example that allowed the cards to respond to adjustments to their own content and the content of sibling elements.
Thankfully, there's more to CSS than layout, and plenty of properties and values can help us put content first. Subgrid and pseudo-elements like ::first-line and ::first-letter help to separate design from markup so we can create designs that allow for changes.
Instead of old markup hacks like this—
<p> <span >First line of text with different styling</span>... </p>
—we can target content based on where it appears.
.element::first-line {
font-size: 1.4em;
}
.element::first-letter {
color: red;
}
Much bigger additions to CSS include logical properties, which change the way we construct designs using logical dimensions (start and end) instead of physical ones (left and right), something CSS Grid also does with functions like min(), max(), and clamp().
This flexibility allows for directional changes according to content, a common requirement when we need to present content in multiple languages. In the past, this was often achieved with Sass mixins but was often limited to switching from left-to-right to right-to-left orientation.
In the Sass version, directional variables need to be set.
$direction: rtl; $opposite-direction: ltr; $start-direction: right; $end-direction: left;
These variables can be used as values—
body {
direction: $direction;
text-align: $start-direction;
}
—or as properties.
margin-#{$end-direction}: 10px;
padding-#{$start-direction}: 10px;
However, now we have native logical properties, removing the reliance on both Sass (or a similar tool) and pre-planning that necessitated using variables throughout a codebase. These properties also start to break apart the tight coupling between a design and strict physical dimensions, creating more flexibility for changes in language and in direction.
margin-block-end: 10px; padding-block-start: 10px;
There are also native start and end values for properties like text-align, which means we can replace text-align: right with text-align: start.
Like the earlier examples, these properties help to build out designs that aren't constrained to one language; the design will reflect the content's needs.
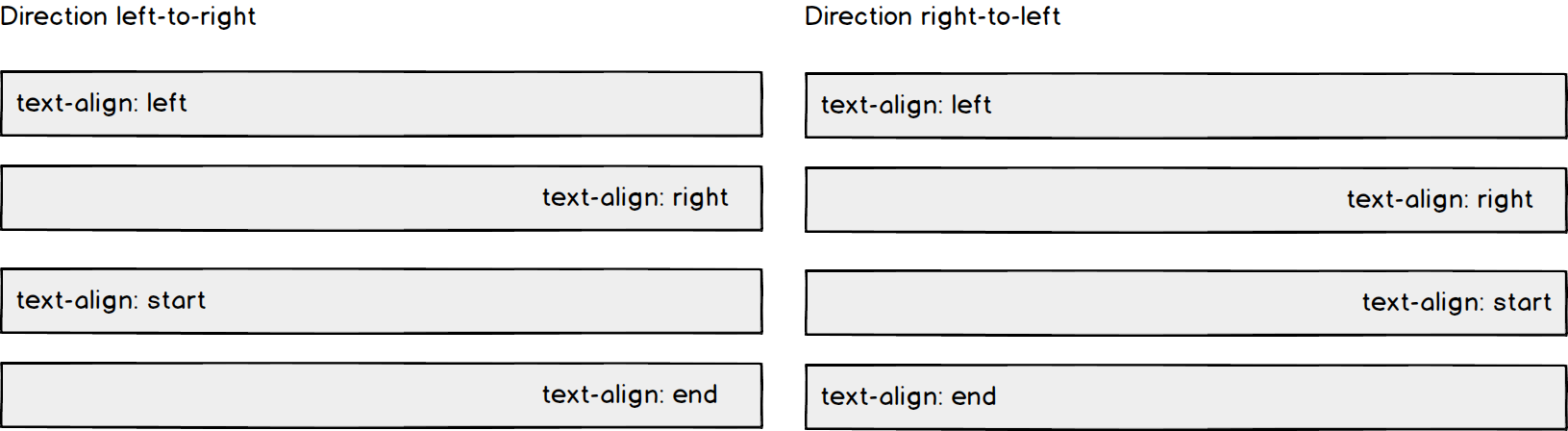 Fixed and fluid
Fixed and fluid
We briefly covered the power of combining fixed widths with fluid widths with intrinsic layouts. The min() and max() functions are a similar concept, allowing you to specify a fixed value with a flexible alternative.
For min() this means setting a fluid minimum value and a maximum fixed value.
.element {
width: min(50%, 300px);
}
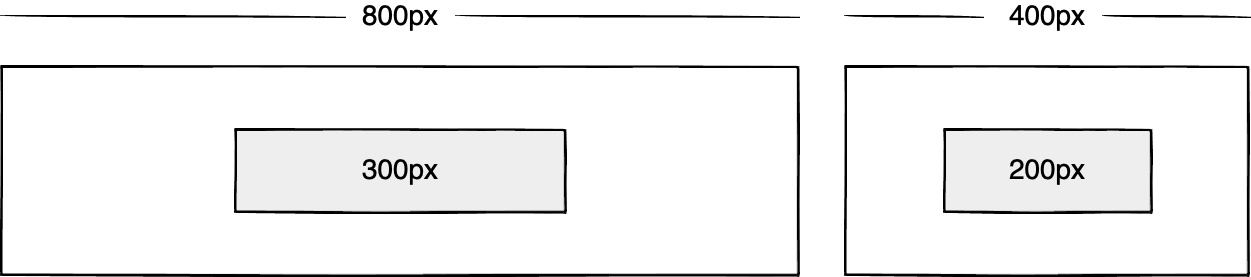
The element in the figure above will be 50% of its container as long as the element's width doesn't exceed 300px.
For max() we can set a flexible max value and a minimum fixed value.
.element {
width: max(50%, 300px);
}
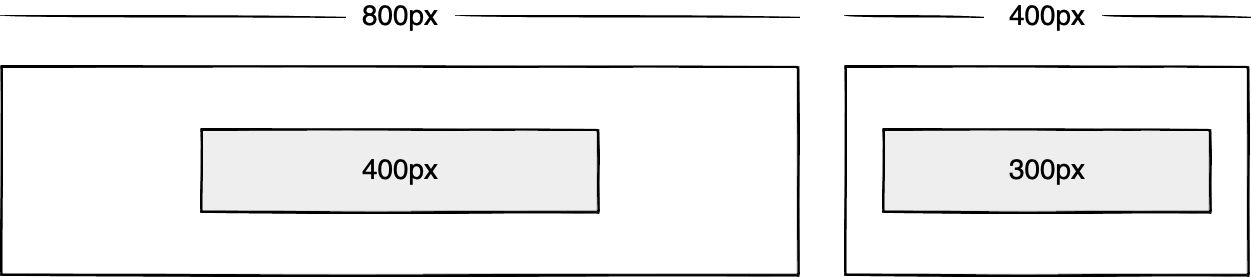
Now the element will be 50% of its container as long as the element's width is at least 300px. This means we can set limits but allow content to react to the available space.
The clamp() function builds on this by allowing us to set a preferred value with a third parameter. Now we can allow the element to shrink or grow if it needs to without getting to a point where it becomes unusable.
.element {
width: clamp(300px, 50%, 600px);
}

This time, the element's width will be 50% (the preferred value) of its container but never less than 300px and never more than 600px.
With these techniques, we have a content-first approach to responsive design. We can separate content from markup, meaning the changes users make will not affect the design. We can start to future-proof designs by planning for unexpected changes in language or direction. And we can increase flexibility by setting desired dimensions alongside flexible alternatives, allowing for more or less content to be displayed correctly.
Situation firstThanks to what we've discussed so far, we can cover device flexibility by changing our approach, designing around content and space instead of catering to devices. But what about that last bit of Jeffrey Zeldman's quote, "...situations you haven't imagined"?
It's a very different thing to design for someone seated at a desktop computer as opposed to someone using a mobile phone and moving through a crowded street in glaring sunshine. Situations and environments are hard to plan for or predict because they change as people react to their own unique challenges and tasks.
This is why choice is so important. One size never fits all, so we need to design for multiple scenarios to create equal experiences for all our users.
Thankfully, there is a lot we can do to provide choice.
Responsible design"There are parts of the world where mobile data is prohibitively expensive, and where there is little or no broadband infrastructure."
"I Used the Web for a Day on a 50 MB Budget"
Chris Ashton
One of the biggest assumptions we make is that people interacting with our designs have a good wifi connection and a wide screen monitor. But in the real world, our users may be commuters traveling on trains or other forms of transport using smaller mobile devices that can experience drops in connectivity. There is nothing more frustrating than a web page that won't load, but there are ways we can help users use less data or deal with sporadic connectivity.
The srcset attribute allows the browser to decide which image to serve. This means we can create smaller 'cropped' images to display on mobile devices in turn using less bandwidth and less data.
<img
src="image-file.jpg"
srcset="large.jpg 1024w,
medium.jpg 640w,
small.jpg 320w"
alt="Image alt text" />
The preload attribute can also help us to think about how and when media is downloaded. It can be used to tell a browser about any critical assets that need to be downloaded with high priority, improving perceived performance and the user experience.
<link rel="stylesheet" href="style.css"> <!--Standard stylesheet markup--> <link rel="preload" href="style.css" as="style"> <!--Preload stylesheet markup-->
There's also native lazy loading, which indicates assets that should only be downloaded when they are needed.
<img src="image.png" loading="lazy" alt="…">
With srcset, preload, and lazy loading, we can start to tailor a user's experience based on the situation they find themselves in. What none of this does, however, is allow the user themselves to decide what they want downloaded, as the decision is usually the browser's to make.
So how can we put users in control?
The return of media queriesMedia queries have always been about much more than device sizes. They allow content to adapt to different situations, with screen size being just one of them.
We've long been able to check for media types like print and speech and features such as hover, resolution, and color. These checks allow us to provide options that suit more than one scenario; it's less about one-size-fits-all and more about serving adaptable content.
As of this writing, the Media Queries Level 5 spec is still under development. It introduces some really exciting queries that in the future will help us design for multiple other unexpected situations.
For example, there's a light-level feature that allows you to modify styles if a user is in sunlight or darkness. Paired with custom properties, these features allow us to quickly create designs or themes for specific environments.
@media (light-level: normal) {
--background-color: #fff;
--text-color: #0b0c0c;
}
@media (light-level: dim) {
--background-color: #efd226;
--text-color: #0b0c0c;
}
Another key feature of the Level 5 spec is personalization. Instead of creating designs that are the same for everyone, users can choose what works for them. This is achieved by using features like prefers-reduced-data, prefers-color-scheme, and prefers-reduced-motion, the latter two of which already enjoy broad browser support. These features tap into preferences set via the operating system or browser so people don't have to spend time making each site they visit more usable.
Media queries like this go beyond choices made by a browser to grant more control to the user.
Expect the unexpectedIn the end, the one thing we should always expect is for things to change. Devices in particular change faster than we can keep up, with foldable screens already on the market.
We can't design the same way we have for this ever-changing landscape, but we can design for content. By putting content first and allowing that content to adapt to whatever space surrounds it, we can create more robust, flexible designs that increase the longevity of our products.
A lot of the CSS discussed here is about moving away from layouts and putting content at the heart of design. From responsive components to fixed and fluid units, there is so much more we can do to take a more intrinsic approach. Even better, we can test these techniques during the design phase by designing in-browser and watching how our designs adapt in real-time.
When it comes to unexpected situations, we need to make sure our products are usable when people need them, whenever and wherever that might be. We can move closer to achieving this by involving users in our design decisions, by creating choice via browsers, and by giving control to our users with user-preference-based media queries.
Good design for the unexpected should allow for change, provide choice, and give control to those we serve: our users themselves.
Musings on whether a virtual reality or a computer generated reality could ever match our real reality. I wrote my first version of this essay in 2008, while in Pinedale, Wyoming, visiting my daughter Isabel and doing some cross-country skiing among the aspen trees. The trees have great patterns like eyes on them. Nice examples […]
The post Here's to the Real World first appeared on Rudy's Blog.
It's the first volume of the Lightspeed Trilogy, and the second volume is well underway.

This internal council document was only recently unearthed in our archives. It refers to a secret governmental emergency plan to "purify" the town following some kind of "infestation or plague," the details of which have now been lost.

Although we can now no longer be entirely sure what Plan C consisted of, the image of a nuclear mushroom cloud offers us a clear indication of the council's intention. Our archivists have postulated that the council might have thought it simpler and more cost effective to remove all living things than to target specific vermin and/or undesirable microscopic pathogens.
What also seems clear is that an unidentified but enthusiastic council employee took it upon themselves to extend Plan C to almost every eventuality, in effect making the nuclear Plan C simply the only plan.
The notion that the council planned to employ a nuclear option is further supported by a minor story in a local newspaper from the time. In October 1979, seven-year-old schoolboy Nigel Johnson, mixed up his family's contribution to his school's annual harvest festival. Instead of the intended box containing four cans of oxtail soup and spaghetti hoops in tomato sauce, he took a quarter tonne of enriched uranium and other weapons-grade nuclear materials.
The boy's father, a local councillor, when questioned how his son could have found such materials at home, claimed ignorance. "Boys are always picking up things like this in the playground," he said and added "it's the fault of liberal teachers and communist dinner ladies and I firmly believe they should be among the first to be cleansed."
4.30pm - 5.05pm GMT, 8 December 2021.
Register for free here.


After my recent review of Pump Street Chocolate's Eccles bar, I was contacted and asked if I'd be interested in writing about some of their Christmas collection. And so it was that a few days later, a delicious delivery arrived on my doorstep.
This year, Pump Street Chocolate have several Christmas themed items, which they’ve organised into different collections to suit various tastes and budgets.
Each collection comes gift wrapped with a Christmas card. I really like this approach, as it simplifies the process of finding a beautiful gift, while adding variety and giving the whole thing a touch of class. Pump Street are known for their elegantly simple packaging, but these collections have a real wow factor which is sure to get a positive response from anyone lucky enough to receive one.
That said, if you prefer to keep things simpler, all of the Christmas products are available to buy individually as well.

The first item I received was this Father Christmas made from 65% Ecuadorian dark chocolate. It comes in this attractive – and sturdy – cardboard tube that kept it in perfect condition. I know from experience that packaging irregular shaped items to be sent through the post is no easy task, so it’s great to see that it’s as effective as it is beautiful.

What does it taste like? Well I can’t actually tell you that, because this little beauty is going to be part of my own Christmas this year. But I’m pretty sure it’s going to be delicious.

The other item I was sent was a collection of Christmas themed bars in this very nice box. It’s a simple cardboard affair with a nicely printed paper sleeve, but it feels like quality. Balancing that line between simplicity, sustainability and elegance is something Pump Street do oh so well, and this box is right on point. Most importantly, it also kept the four enclosed bars in perfect condition.
The bars are:
- Eccles 55%
- Grenada Milk & Nutmeg 60%
- Gingerbread 62%
- Panettone 70%

Of course, I’ve already reviewed the Eccles 55% bar, which is absolutely fabulous. Here’s a quick summary of the others:
Grenada Milk & Nutmeg 60%A 60% dark chocolate made with cocoa beans from the Crayfish Bay estate in Grenada and flavoured with locally grown Grenadian nutmeg.
Gingerbread 62%Made with Pump Street Bakery’s Gingerbread Cookies spiced with ginger, cinnamon and cardamom in a Jamaican 62% dark chocolate.
Panettone 70%A traditional Panettone made with almonds and candied fruit in a 70% St Vincent origin dark chocolate.
All in all, I wouldn’t hesitate in recommending any of the Pump Street Chocolate Christmas collections for the chocolate lover in your life. But you don’t have to limit yourself to just the Christmas themed options; I would be happy to recommend any of their creations at any time of the year. They are unique craft chocolate gifts that taste as good as they look.
Information- Buy it online from:
- Contains dark chocolate, milk chocolate.
- Cacao Origin: Ecuador, Grenada, Jamaica, St Vincent
- Filed under bean to bar, christmas, pump street, uk.
The post Pump Street Chocolate Christmas Collections appeared first on Chocablog.


Pump Street Chocolate are one of Britain's best known and best loved bean-to-bar chocolate makers. Started by father and daughter Chris and Jo Brennan in 2017 as a sideline to their village bakery in Suffolk, they have quickly grown to be one of the world's most respected makers.
Being a spin-off from the bakery, they are well known for combining baked goods with their chocolate. In particular, their Sourdough and Rye bars take bread from the bakery and refine it into the chocolate itself. To combine bread and chocolate is no easy task, but Pump Street consistently manage to capture the flavour and texture of their bread in the chocolate, marrying the two expertly.
Combining an Eccles cake and chocolate is another matter entirely. A Pump Street Eccles cake contains raisins, currants, brown sugar and alcohol, all of which can potentially contain water – the enemy of chocolate! If you tried to simply grind one into chocolate, you'd likely end up with a thick, sticky mess.
I'm not entirely sure how they have produced this bar, but the chocolate itself tastes just like a traditional Eccles cake; bready and friuity with a hint of brandy, but you also get whole currants and raisins and just a hint of brandy. The result is very identifiably an Eccles cake, rather than some other kind of fruit cake flavoured chocolate. Each of the flavours – bread, fruit, spice and alcohol – are there and identifiable, but none of them detract from the chocolate.
I love this bar and highly recommend you check it out, along with the rest of the Pump Street range. The bakery series bars are always the most interesting to me, but Pump Street have proved themselves to be some of the best in the world, so you really can't go wrong whatever you choose.
Thanks to The Foodie Bag for supplying the photography background and other equipment used in this post.
Information- Buy it online from:
- Contains dark chocolate (55% cocoa solids).
- Cacao Origin: Ecuador
- Filed under bread, eccles, pump street, uk.
The post Pump Street Chocolate 55% Ecuador With Eccles Cake appeared first on Chocablog.

The story has been long in the making. Sometime in the early 1990s I had an idea for a story called 'Nineteen Eighty-Nine', in which events like those of 1989 in our world happen in the world of George Orwell's Nineteen Eighty-Four. I wrote it and sent it to Interzone, and they sent me a kind rejection note suggesting that I try a local fanzine. I sent it to the local fanzine New Dawn Fades, and they rejected it. The editor softened the blow by encouraging me to write something else for them. They later accepted, I think, a review and a poem. But for the moment, I was done with short stories. After that, there was nothing for it but to write a novel.
That's the story I've told now and again, usually with the punch-line that the best thing about the story was the title, because it tells you exactly what the story is about.
Now I'm going to have to retire that anecdote.
Earlier this year, shortly after I had read that Orwell's fiction was now out of copyright, Ian Whates emailed me to ask for a story for a new venture he was planning. I pitched 'Nineteen Eighty-Nine'. Ian was keen, so I looked at my old story (or what I could find of it), decided it was beyond help, and wrote an entirely new story. I'm fairly sure it's an improvement on my first attempt.
One inspiration for the new version was the article 'If there is Hope' by Tony Keen, in Journey Planet #3 (pdf). Another was the article Orwell on Workers and Other Animals, by Gwydion M. Williams, which makes the intriguing point that 1945 is missing from the world of Nineteen Eighty-Four.
While writing the story I chanced on a clue to Orwell's pessimism that, as far as I know, has escaped scholarly attention. Orwell, it turns out, had read and been impressed by George Walford's pamphlet The Intellectual and the People.
Walford drew on his mentor Harold Walsby's The Domain of Ideologies, the founding text of what Walford later called Systematic Ideology. This argued that the major social outlooks form a historical, numerical, and political series in decreasing order of antiquity, size, unity, and radicalism. The (historically) oldest and (currently) largest group is the apolitical, followed by the conservative, the reformist, the revolutionary, and the anarchist ... with the tiniest, least effectual and most extreme group being the Systematic Ideologists themselves, who understand the whole process but can't think what to do about it.
More about this another time, but it seems to me significant that Orwell attributed political apathy, ignorance and indifference to - not 'perhaps the largest single group' of the population, as Walford did - but to the vast majority: 85%.
I got asked to blurb the UK reissue of Lynne Tillman 's first book Weird Fucks a couple of days ago... which reminded me of what happened when I first attempted to obtain a copy....
A month or so after first meeting Lynne at a party in NCY in the spring of 1989, I was in Paris to interview Ralph Rumney about the Situationist show at the Pompidou Centre for Art Monthly. Rumney asked me if there was anyone in Paris I wanted to be introduced to and I said I'd really like to meet Gil J. Wolman, who I knew he knew. We just went around to Wolman's because he didn't have a phone but sadly he was out. Rumney suggested we try Jim Haynes who lived nearby, nice guy but hardly as exciting to me as getting to meet the man who'd made L'Anticoncept. We caught Jim at home and at that time he was making various literary works available by photocopying them individually when people asked for them. Weird Fucks was one of those books. I asked Jim to make me a copy of Lynne's novel and he looked around for the art work but couldn't find it. Embarrassed he'd mislaid the originals of the book I wanted, he insisted on giving me a copy of his autobiography Thanks For Coming published by Faber. It seemed like a day of disappointments with first not getting to meet Wolman, then not getting Lynne's book. However, later when I examined Thanks For Coming I discovered it reproduced a page from International Times that included a photograph of my mother at Alex Trocchi's 1969 Arts Lab event State of Revolt. Years later I discovered that Lynne organised the State of Revolt shortly after graduating from college and then moving to London..... So I unknowingly left Jim Hayne's pad with a little bit of Lynne's and my own family history crossing 20 years earlier.


MIKE: What writers and books inspired you to become a writer ?
HOME: It was never my plan to become a writer. As a kid I read a lot but I was much more into rock and roll and in particular glam rock than the idea of being a writer. At the start of the seventies my favourite band was T.Rex but I liked most glam stuff as long as it had a decent stomp from Sweet through to Iron Virgin. I'm old enough to remember when Rebels Rule was getting some heavy radio play and at the time I couldn't believe it didn't become a hit and Iron Virgin disappeared. The couple of years before punk was a bit of a desert as far as new music went - so I went backwards into northern soul coz I knew a lot of people into that but also British mod and what became known as freakbeat, I was listening to earlier Pretty Things and Downliners Sect in 1975. Back then I didn't realise my taste in northern soul was very mod orientated, more Twisted Wheel than Wigan, I only found out about those distinctions later. I got into punk in the summer of 1976 after seeing the Pistols on So It Goes, and immediately discovered Nuggets and all that USA porto-punk - I knew Lou Reed's solo stuff from the seventies but the Stooges, Patti Smith, Flamin' Groovies and MC5 were all new to me as a 14 year-old in 1976. But punk wasn't nearly as popular at my school as northern soul and then jazz funk for the hipster kids, or disco for those that just followed the charts.
As far as writers from that era go there were a whole raft of pulp writers doing everything from horror to youthsploitation but if I was gonna pull out one key influence it would be the Mike Norman hells angels books that I first read when I was 11 or 12, around the same time I was getting into kung fu films…. I was also reading a lot of Michael Moorcock but more Elric titles than Jerry Cornelius, I read Moorcock's more experimental stuff later.Of course loads of kids I knew read The Rats by James Herbert around 1974/5 that and the skinhead books were probably the biggest sensations in my milieu at the time. A lot of the white boys at my school were also into Sven Hassel but I didn't like nazi shit so I didn't read them and neither did the girls (although many dug stuff like The Rats). Some of the African and Afro-Caribbean kids at my school also read those books but the Muslim kids who made up about 25% of the pupils weren't interested in any of that stuff at all There's an interview with Mick Norman, his real name was Laurence James, on my website, coz the first four books he wrote are really important to me and he was also the editor for the earlier Richard Allen skinhead books. Sadly he died 20 years ago but I was glad I got to know him at the end of his life. https://www.stewarthomesociety.org/interviews/james.htm
MIKE: You seem to always have some kind of project on the go, are you type of person who struggles to take it easy or is it a case of stay busy to pay bills ?
HOME: I just like doing things so I don't really like to take it easy. I don't think making money is a good motivation for doing anything other than a 9 to 5 work, although its great if my stuff makes a few bob and I can continue to avoid a regular job…. But I'm curious about many things including exercise systems and I never have the time to try our all the fitness regimes that fascinate me coz generally I can't set aside more than a few hours a day to workout, although on the odd occasions I've gone on a sports holiday and done 6 or 7 hours a day of training I've really enjoyed it but of course you have to mix hardcore strength and cardio with gentler stuff like stretching, it would be counterproductive to spend that much time on nonstop weightlifting for a week or two!
MIKE I first read you back in 93, 94 Red London & No Pity but have not kept up with all your work through the years, what books of yours would you reccomend to people new to you ?
HOME: There is a lot of variation between the different books and which to recommend would depend on someones's interests and tastes. No Pity and Red London were part of a cycle of early books riffing on youthsploitation fiction - of those books the last Slow Death really puts a polish on what I was doing but in some ways Defiant Pose is my favourite and I think it has the single best scene, one where the Houses of Parliament are burned to the ground while the main character gets his cock out and recites an incendiary revolutionary tract. But it was 69 Things To Do With A Dead Princess that got the attention of the literary types as it's more experimental and shows my interest in writers like Alain Robbe-Grillet and Ann Quin. I'm very fond of Tainted Love which is fiction but closely based on my mother's life once she came to London when she was 16 in 1960 - she was working with the likes of Christine Keeler as a hostess at Murray's Cabaret Club before I was born, then involved in the early LSD scene but sadly died of heroin overdose in 1979. She packed a lot into her short but incredible life. I did her story as a novel so as to avoid problems with certain people who were still living but most of what's in it is true. I had to change a few things around to avoid libel problems as that one came out with a corporate publisher.
MIKE: I absolutely loved She's My Witch that I read around Xmas time , I think it's my favourite book of yours of ones I have read, can you tell us a bit about it ?
HOME: That came out of observing what was happening to people who'd been going to punk and garage rock gigs for a long time but I simultaneously wanted to do a story similar to my mother's but for a generation down. So rather than coming to London from South Wales like my mother, the main character Maria has come to London from Valencia - it's the same trajectory as my mother but a woman from my generation rather than the previous one. So instead of modern jazz and beatniks, the subcultural interest is punk rock. And there is an involvement with witchcraft rather than Indian gurus. I didn't make a big thing out of it in Tainted Love but one of my mother's favourite books was the BDSM classic Story of O by Pauline Réage AKA Anne Desclos. So while in Tainted Love my mother does high class hostessing, as she did in real life, Maria in She's My Witch is a former dominatrix. Over the years quite a few woman who've worked as a dominatrix have told me they like my fiction, so I've got to know a few. Recently I've been making art with Itziar Bilbao Urrutia, who as her name implies is from Bilbao and for a couple of decades has been the premier suspension bondage dominatrix in London. But I wrote the first draft of Witch before I met Itzi. The end of the story also parallels my mother's life, Maria dies from a heroin overdose.
In some ways Tainted Love and Witch addresses something that few punks wanted to deal with back in the seventies, which is how close a lot of what we did was to the earlier freak subculture, so I wanted to draw that out with stories of two lives a generation apart. I also thought it was interesting to address albeit obliquely the Ruta Destroy Valencia party scene of the post-Franco period. There's not much about it in English and it was nice to start to correct that. I was just struck going to punk and garage gigs in London a decade or so ago by how many people from the Iberian peninsula I met there who'd moved to London and who'd gone to all those amazing clubs to the south of Valencia back in the day. Of course there are loads of other subcultural scenes from that and other times which have been ignored. Just before I left school in 78 a few of the kids in my year who'd been very into northern soul were getting into the Britfunk scene and were moving over to being jazzfunkateers - that whole thing was huge around the same time as punk in the UK but its been largely ignored too, so it was nice to see a piece about it by Alexis Petridis in The Guardian last week.
MIKE: You edited Denizen of the Dead book which was great fun if you dislike gentrification, were you happy with that ?
HOME: When I originally had the idea for Denizen of the Dead I thought I'd do a novel based on these luxury investment blocks that are being built all around me and across London. But on reflection it made more sense to do an anthology with different writers because it was meant to be a form of protest and that should be collective. Novels are a lot easier to get attention for than short story collections but I think I made the right decision to do an anthology. I'm really happy with the book and I particularly like the fact it has the sigil spells in it, I worked with some witches to do a protest called Hex In The Park against gentrification in east central London in 2017 and when I said I was doing the book they said I had to have a spell against Neo-liberalism in it and they'd do it. That wouldn't have happened if I'd just done a novel on my own, so I'm pleased it panned out the way it did. Also if London had been gentrified in the late-seventies like it is now, we'd have never had those huge punk rock and Britfunk scenes, there just wouldn't have been the venues for them. Lower property prices do an enormous amount for creativity, gentrification kills it. There's some film of Hex In The Park on my YouTube channel: https://youtu.be/nYMQiBlY4eg
MIKE: I just started 9 Lives of Ray the Cat Jones, your latest book, tell us a bit about that ?
HOME: Many of my books are entirely made up but like Tainted Love that is based on a true story but done as fiction because it wasn't possible to get to the truth about everything to do with my mum's cousin Ray Jones. There are a lot fo criminals in my family but Ray is the most famous one. I hadn't intended to do a book about him but I was talking to the writer Paul Buck one day and he said he didn't believe the story about my relative's escape from Pentonville although he'd included it in his book The E-List about prison escapes. The version of the story Paul had came from Mad Frankie Fraser and I thought it was bullshit too, so I asked Paul why he hadn't researched the incident. Paul said he didn't know how to do that but I did, so I went back through old newspapers and of course it turned out the Frankie Fraser version was a pretty stupid exaggeration of a very successful escape.Another interesting thing about Ray was he was a burglar with left-wing views when most London criminals leaned to the right - maybe that's because like my mother he grew up in South Wales and came to London as a young adult. Anyway I found the books about crime in London in the 50s and 60s which mentioned Ray pretty fictional, so I figured I'd do the story as a novel. I had a fair bit of true material to work from including Ray's own outline of his life alongside newspaper reports of his court appearances going back to the early 1940s. I thought it was a story that needed telling. It originally came out in 2014 but it was soon out of print, so it's just been reissued. There aren't too many books about class conscious cat burglars so I'm proud to have done one.
MIKE: How have you coped with lockdown? Has it affected you much in terms of promoting your work, or has it been more of a pain to your social life ?
HOME: Worst thing about lockdown has been not being able to go out and do talks and readings coz I'd pick up money for that and sell a few books at the same time. Not being able to go out in person definitely has a negative effect on book sales, so that's a downer. And of course I miss all the beautiful people I used to encounter at garage gigs too! I've got a foldout weights bench and a load of weights, so I'm happy enough at home because I can workout - glad I got all that stuff cheap over the years coz lockdown really made exercise equipment expensive. My view of lockdown was it was an unfortunate necessity to halt Covid, I just think the UK government handled it really badly, they should have acted sooner and been stricter so that we didn't have to endure such long lockdown periods. Johnson and his cronies really need to be held to account for how badly they handled things, and those most directly involved in stupidity like the Eat Out To Help Out scheme really do deserve some form of punishment. It seems like they were more interested in corruptly handing out money to their posh mates than our welfare.
MIKE: What five albums would you grab if house was on fire? As you are a writer would you grab any books as well ?
HOME: Coz I've not been getting to any gigs due to the pandemic I'd go for all live albums right now…. which wouldn't necessarily be the case in other situations. So in a soul groove Aretha Franklin Live at Fillmore West and Major Lance Live At The Torch, Punk rock would have to be Jayne County Rock 'N' Roll Resurrection (Live 1980) and the Adam and the Ants In Bondage 1978-79 bootleg, for the live 1978 Marquee set included on it. I saw the Ants a load of times at the Marquee in 1978, as well as at other places but never saw them after the last appearance of the old Ants at the Electric Ballroom at the end of December 1979. They really were the best band regularly playing London back in 1978/9, so it's a real shame there aren't better recordings of some of those songs! Final album would have be to be a toss up between Slade Alive and Hawkwind's Space Ritual, which ever came to hand first but both are great examples of post-sixties but pre-punk rock and roll. Books? I'd have to save my sixties hardback and paperback copies of Terry Taylor's Baron's Court All Change - he was the inspiration for the narrator of Absolute Beginners by Colin MacInnes and was an incredible guy and friend of my mum. Baron's Court is about early mod culture at the end of the fifties/beginning of the sixties straight from the horse's mouth and published in 1961. it's also the first British novel to mention LSD!
MIKE: What are you working on currently ?
HOME: Well as I can't go out to get inspiration it's a lockdown novel about a guy going crazy in his one bedroom council flat in Islington…. while practising ninjitsu on Zoom and watching a load of old ninja movies. I've got another book called Art School Orgy finished but that has some legal issues so may be hard to get published immediately. Had the same problem with Denizen of the Dead, publishers really don't like any risk of legal action even if it's pretty unlikely. I'd like to be making some films too but that will probably have to wait until I can work with others on them, once we're on the other side of the pandemic.
MIKE: I read something about Joe England saying you inspired him, does it feel good to be passing the torch so to speak, not that you are coming to end of career ?
HOME: Always nice to be told you're an inspiration but especially by someone whose work grooves you! We all need to get ideas from somewhere, we're not creating in a vacuum. I got a load of inspiration from other writers too, so yeah the torch has to move on…. although I've no plans to stop writing for the time being I may shift to more non-fiction for a while. My last non-fiction book Re-Enter The Dragon: Genre Theory, Brucesploitation and the Sleazy Joys of Lowbrow Cinema came out in 2018, so it would be nice to follow that up with another film book…. but then my love of martial arts and exercise might also lead to some more sport orientated titles too.
This interview original appeared as a Facebook punk post.
She's My Witch by Stewart Home (London Books 2020)
This novel tells the story of a social-media driven romance between a Spanish Witch and a London born fitness instructor, in London between 2011 and 2014.
It moves through a background of the physical space of London, but more importantly through a re-imagined London-scape of memories, dreams, and reflections. The couple's relationship is shaped by overlays of legends and patterns and archetypal characters from the lovers' fascination with shlock music and exploitation cinema.
The narrative is punctuated with a sequence from the Swiss IJJ Tarot deck, in numerical order, each chapter is headed with the image of a Major Arcana Tarot card. It begins with The Fool and ends with the World.
In his lecture about the Tarot, Carl Jung noted that "man always felt the need of finding an access through the unconscious to the meaning of an actual condition, because there is a sort of correspondence or a likeness between the prevailing condition and the condition of the collective unconscious." Jung's experiments with divination were intended to accelerate the process of "individuation," the move toward wholeness and integrity, by means of playful combinations of archetypes.
In She's My Witch, the playful archetypes come from popular fiction, the dominatrix, the fitness coach, the ex-skinhead - and their reminiscences of Screaming Lord Sutch; the Angry Brigade and the Valencia Rave scene. As in a lot of Home's previous fiction, the plot is constructed around pulp archetypes, rather than individualised characters. For each reference there is an "occult" element. The themes are of "otherness": the underground world of secret knowledge that permeates an understanding of the hidden; the unofficial secret histories where identities are fluid, genders are blurred and shapes are shifted.
The witchcraft operates in a specific set of dates and times - a contemporary folk history post Rave and pre-Brexit - when social-media began to become paramount in shaping social interactions and bewitching collective unconscious.
As the mystical psychologist and filmmaker, Alejandro Jodorowsky, puts it, "the Tarot will teach you how to create a soul."
Stewart Home She's My Witch ISBN 978-0-9957217-4-6 (2020) London Books Paperback £9.99
This book review by Nigel Ayers first appeared in print in The Enquiring Eye: Journal of the Museum of Witchcraft & Magic, Issue 4, Autumn 2020. The magazine can be bought online here.
She's My Witch by Stewart Home can be bought online here.
Other reviews of She's My Witch included those at 3AM Magazine, The Morning Star and 3.16 Magazine.
B. From what I've heard, the English literary press is a little afraid of you. What was their reaction to the publication of Tainted Love?
H. I've got the press cuttings somewhere but I'd have to look them out. The book that really made a difference to perceptions of me as a writer was 69 Things To Do With A Dead Princess, which was my seventh novel. Tainted Love was my ninth novel but I was doing non-fiction books as well, cultural commentary on anti-art movements and punk rock. Before Dead Princess I just had a reputation as a troublemaker among literary types but when that book came out I got praised for having a subversive grip on literary form. Tainted Love is one of only two books of mine that was sold in English through a literary agent, so it was on a corporate publisher Virgin. I don't think people were really expecting to find me on that type of publisher or to do a book based on my mother's life. I don't remember much about the reviews but I do remember my agent saying Virgin had done a really good job of publicising the book which made me laugh. I don't think their press department knew what to do with me but they got some radio coverage on the BBC and even sent a new PR girl they'd hired to take me to the radio station… that was unusual too because I was used to going and doing those things on my own rather than than having someone from the publisher to hold my hand. Of course it is nice to have someone looking after you every step of the way but it isn't necessary. Anyway all the coverage the agent liked I engineered from my own contacts which were pretty good by that time, and of course because the press came through me it was positive. But even today I think a lot of literary types are still frightened of me - and also puzzled by some of my friendships with other writers because they don't understand what I have in common with say Lynne Tillman or Chloe Aridjis.
B. I can imagine many were surprised to read that Tainted Love's main character is your mother, Julia-Callan Thompson, although it's not exactly biographical. How much of the book is true, and how much is fiction?
H. As far as I can tell it's mostly true, the fictional element comes from me writing it in the first person as my mother to tell the story, although she is renamed Jilly rather than Julie because I'm treating it as fiction. About 20 years ago I did a lot of research into my mother's life and talked to everyone I could get hold of who knew her and was willing to chat. It was difficult to get people to go into any detail was her sex work, although it was obvious to me she'd been doing that. Her friends mostly didn't want to talk about that aspect of her life but I forced the issue with a few of them. With a lot of people I had to keep going back to them to get fuller stories, and of course in some instances it looked to me like they or their partners were also doing sex work but I wouldn't challenge the sometimes utterly unbelievable tales some came up with to show this wasn't the case.I was interested in my mother and not bothered about getting to the bottom of her friend's lives.
I spent years trying to get hold of Terry Taylor and when I finally did he was much more frank about my mother and sex work for the simple reason that I was, as he put it, hip enough to appreciate her. Of course there were variant versions of stories about my mother and instances where different sources or even the same source at different times told contradictory tales. I often had to make critical judgements about what was and wasn't true, on the whole those weren't hard calls as some sources were obviously more reliable than others. I also had my mother's diary, address book and some other papers that all helped. I've put some non-fiction about my mother and that probably gives a good idea of how I arrived at the version of her life-story I used in the novel. There was an enormous amount of research involved. In terms of the non-fiction about my mother maybe a good place to start is with The Real Dharma Bums (https://www.stewarthomesociety.org/praxis/dharmabums.htm) and to then move on to 2 Ladbroke Grove Hipsters of the 1960s (https://stewarthomesociety.org/blog/2009/03/18/grainger-trina-2-ladbroke-grove-hipsters-of-the-1960s/). Those are about the two great loves of her life. That said, I'm not claiming to be right on every detail of her life.
B. The novel portrays London's subcultures of the sixties in a different light to the usual - less sugar-coated if you will. Do you think that people often view the different subcultures of that era as having little to no correlation, when the reality was rather the opposite?
H. I think the problem is that people like things they can recognise and so they want a familiar story and recognisable names. But if you actually examine the historical evidence things turn out to be very different to the fairy-tales that are told again and again. That's obviously in terms of drug culture to take just one example. When I was looking into my mother's life I knew she knew Terry Taylor and I knew he'd been the real-life inspiration for the main character in Absolute Beginners by Colin MacInnes. Since Terry had written a book Baron's Court, All Change I thought I should read it and was really surprised to discover it was a lost classic about the birth of British mod culture. Now the standard understanding was that stylish mods took amphetamines and the sloppily dressed kids were into dope. But in Baron's Court it's the other way around and Terry obviously knew the score on that and was giving an accurate albeit fictional description of those scenes. Terry, my mother and various other characters were also connected to Victor James Kapur. Back then the story was Operation Julie in the 1970s was the first big acid bust in the UK. Talking to people from my mother's circle I got to know about the big bust of Kapur's two London labs in 1967, although no one I spoke to could remember the name of the chemist and I had to chase it up in old newspaper stories (which weren't hard to find). When I finally spoke to Terry Taylor, he of course remembered Kapur and was able to name him, but I'd identified the chemist from press reports by then. I brought the story of the UKs first major acid factory bust back into circulation in an essay I did for the book Psychedelic Art, Social Crisis and Counterculture in the 1960s edited by Christoph Grunenberg and Jonathan Harris in 2005. Subsequently it was taken up by Andy Roberts in his 2008 book Albion Dreaming: A Social History of LSD in Britain and has subsequently spread further. So now anybody who knows anything about UK acid culture knows Operation Julie wasn't the first major manufacturing bust but for about 30 years that fairytale was the dominant story in the media at least.
That said you can go to other areas of British subculture and discover the dominant stories about them aren't true. For example the idea that the skinhead cult started in the east end of London in 1969. Anyone who cares to look at photos of the Hounslow mod/skinhead band Neat Change can see a couple of members of this group were west London skinheads before they broke up in 1968, and their singer Jimmy Edwards told me they were skinheads in 1966! No one was much interested in that until I put an interview with Jimmy Edwards on my website in 2010 alongside some pictures of the band which I got from their guitarist Brian Sprackling, I don't think they'd been published before I put them on my site, they certainly weren't online. Since the band broke up in 1968, it's obvious they adopted the skinhead look before then and probably by 1967 and at a stretch in 1966 as their singer Jimmy Edwards claimed. Whatever way you look at it there is clear evidence there that there were skinheads in west London before 1969, so skinhead didn't originate in east London in the last year of the sixties as is so often - and completely wrongly - claimed. I only had small versions of the photos on my site but a few people picked up on what I'd done and reused them larger elsewhere (as I had bigger versions from Brian). The original interview I did with Jimmy Edwards is here, sadly he's not alive any longer: <https://www.stewarthomesociety.org/interviews/edwards.htm>
So the history of these subcultures is totally mythologised and most people don't understand much about their real evolution. They are more closely connected than many of those involved in them want to admit. In the late-seventies, I'd switch continually between punk, mod, rude boy and skin styles - I couldn't see the point of getting hung up on just one. Some where less fluid in the adoption of subcultures but. minority were like me. One of the reasons my book has the title Tainted Love is because when I was at school I had a friend whose older brother worked in a factory and would come home while I was hanging out with his sibling. In the mid-seventies a lot of the kids at my school were into boot boy culture which had evolved out of skinhead and suedehead, and although we were down south a lot of the boot boys were also into northern soul. My friend's brother really liked northern tunes and in the mid-seventies Tainted Love was considered a hot northern soul spin, although obviously later it became too well known to be considered very cool on that scene. Anyway, my friend's brother would come in from his factory job and put on a record and drink a cup of tea before going to tinker with his motorbike or whatever, and the record he put on most often was Tainted Love. The older brother had been adopted so I always associated that tune with kids who'd been separated from their mothers. But one of the oddities about my friend's brother was that apart from northern soul, he was really obsessed with the prog rock band Greenslade, so aside from some northern tunes, I first became acquainted with a some of the more obscure progressive rock bands because of him too.
B. In the book you state; "Anyone who thinks you can understand the history of London in the sixties by looking at the lives of Mary Quant, Twiggy, Bailey and The Shrimp, Mick Jagger, Michael Caine and Terrence Stamp, is sadly deluded". Could you elaborate on this?
H. History from below is always more interesting than the stories of so-called 'great' men and it usually is men, although I've quite consciously pulled out the names of some well-known women from the sixties. There's a much more interesting story to be told about the sixties than that to be found in the memoirs of the more prominent sixties figures and those who are impressed by them and write about that decade as if it consists only of them. That's partly why I wanted to tell my mother's story but as fiction, because biography and autobiography always and already is fiction. I also remember the sixties since I was born at the start of the decade and for me it wasn't all about The Beatles, I remember waiting for the bus to go to school when The Beatles broke up and some of the older kids were really cut up about it but I didn't give a damn coz I wasn't into The Beatles. In terms of media the sixties for me was much more about spy flicks and TV shows and stuff like that. I really used to love The Man From UNCLE, I used to stay up late to watch it when I was five years old. So there isn't just one sixties, there are many sixties that people experienced in London, and even more variations of the sixties experienced around the world. Nearly a decade after I did Tainted Love I wrote a book based on the life of my mother's cousin Ray The Cat Jones who was a well-known burglar who made a front page headline grabbing escape from Pentonville Prison in London in 1958. He was a lot older than my mother and his life covered a longer time period, but in my book he encounters my mother's world in the sixties and seventies and its completely alien to him and his experiences. His sixties is very different to my mother's sixties. But again it's a history from below and while The 9 Lives of Ray The Cat Jones is a novel and fictional, it's probably truer to life than vast majority of ghost-written criminal autobiographies.
B. Lots of celebrities appear, though many of them in very questionable situations. The John Lennon and Brian Jones cameos come to mind. Weren't you afraid of getting into legal problems?
H. I have my mother's address book and John Lennon is in it alongside a lot of other pop musicians and cultural figures, there are an incredible number of well known people in there - but I found the lesser knowns more interesting to research. One publisher rejected the book because they didn't like the stuff about Lennon which is as far as I can tell pretty true to life. I thought everyone knew Lennon could be a complete arsehole. However there were no libel issues with Lennon because the dead aren't protected by libel laws and he was dead long before I wrote the book.
There were two other figures I wanted to include from the pop scene of the sixties but both were still alive when I wrote the book - and still are now - I'd heard stories about them and my mother but couldn't use them because they are rich enough to sue and in England the libel laws are about protecting protecting the rich not the truth. One of them is nearly as well known as Lennon so including him would have been a huge risk and probably no publisher would have taken the book if I'd insisted he was in it. So Brian Jones was a substitute for these two figures and he behaves like Brain Jones - I read several books about him to get a grasp on that - rather than those he is a substitute for.
If you read the pop picker sections of Tainted Love and look at Robert Frank's Cocksucker Blues documentary of the Rolling Stones 1972 US tour, then you'll see how you might re-read the film to make it as true to life as my writing. There's a woman presented as a groupie but she's a junkie and to me looks like a pro. My impression is the managements and record companies preferred professional sex workers to groupies because they didn't expected to be treated as special or for some kind of lasting relationship to develop, so they were generally much less trouble than groupies. As a result pros would be put in for the band by those working with them because it was considered safe, and of course a lot of sex workers used drugs and would deal them on the side, so it was all handy. That's not to say the pop star in question necessarily knew they were dealing with a sex worker because they weren't the person parting with dosh for the service.
Eckhart Schmidt's 1982 movie The Fan doesn't deal with the pro side of things but it's a fictional exploration of just how badly things can go wrong with when a pop musician sleeps with a fan. I see fiction as a much more direct route and honest way to get to the truth in terms of individual lives than biography and especially autobiography where you couldn't substitute Brain Jones for those who are still alive and protected by wealth. Another figure I didn't put into Tainted Love because they were living when I wrote the book is Sean Connery. My mother claimed that the Bond actor paid for a good time with her when she was working as a hostess at Churchills in Bond Street in 1964. Of course, the fact my mother said this doesn't make it true but since it would be hard to prove one way or the other, it would have been tempting to use if Connery had died younger than he eventually did. That said, there's more evidence for the pop musicians than the actor.
B. The novel's timeline reaches the end of the seventies, with counterculture already fully amortised as a mass phenomenon. In your view, was it a failed revolution or just a by-product of the birth of the late-capitalist consumer society?
H. Elements of the counterculture were revolutionary but it wasn't revolutionary across the board, in fact it was quite a mixed bag but under capitalism we all reproduce our own alienation. I do think en bloc it was more than just a a by-product of late-capitalist consumerism, although the latter is characteristic of parts of it. But there's also a danger of fetishising the sixties and overlooking the flappers and cocaine frenzies of the twenties, or the Zoot boys of the forties.
B. The use and abuse of drugs is a recurrent theme in the novel and, for that generation, was more than just a hedonistic escape. The use of illegal substances is probably more widespread today than ever but detached from these countercultural or psychedelic values. What do you think about drugs and their relationship with counterculture?
H. Drugs were absolutely crucial to the counterculture, alongside sex work they financed a lot of it but of course they were more than that since there was a deep interest in expanding consciousness in parts of the beatnik and hippie subcultures. That's one of the things missing from the straighter parts of the revolutionary milieu, the understanding that mature communism isn't just about the return at a higher level of the anti-economic forms of primitive communist societies but also about reclaiming the characteristic modes of consciousness of such social forms, which we could say is characterised by shamanism. I'd agree drug use is more widespread today and also largely detached from a psychedelic desire to expand consciousness. My most recent novel in English She's My Witch addresses that in an oblique way, since the main character Maria is into both occult modes of consciousness and drugs but they are separate pursuits to her in a way they were not for my mother in the sixties. She's My Witch is very much an attempt to take a subcultural life-story that is similar to my mother's but a generation down so it is punk rock and witchcraft rather than beatnik jazz and Indian gurus that fire Maria's imagination. Despite my mother coming from South Wales and Maria in Witch from the mountains to the west of Valencia, they both end up in London and die prematurely from a heroin overdose. The style of the books is rather different but thematically they are very much linked but with the crucial different that in the earlier one an interest in drugs and expanded states of of consciousness are linked in a way they are not in the more recent novel.
B. Paradoxically, drug usage was utilised by the authorities to justify repression and abuse. The toughest parts of the novel are those in which police officers appear.
H. It was very hard to get out of my mother's friends how badly she was abused by the police. Terry Taylor had left London and wasn't in regular touch with her when that was happening, so I had to get it from other people. In Tainted Love I'm recording what I dragged out of people since they weren't too willing to tell me. But I don't think that level of abuse will surprise anyone whose been at the sharp end of London policing. Strangely at the end of September 2020 one of the most notorious of the bent coppers as far as the London counterculture goes, Norman Pilcher, put his name to a book called Bent Coppers: The Story of The Man Who Arrested John Lennon, George Harrison and Brian Jones, I haven't bothered to read it because while he tells of corruption all around him, he now claims he wasn't involved in it, which is a blatant lie. Nearly 20 years ago I asked to speak to one ex-cop who'd lodged a blatantly false report about my mother. He refused to talk to me but I hope I made this retired thug feel uncomfortable. I would have done the same for others if I could have got hold of them. I assume they're mostly dead now.
B. Tainted Love was published over 15 years ago. Do you think the sixties still have something to teach us?
H. Every age has something to teach us, so of course the sixties does too. As Marx famously said: "Men make their own history, but they do not make it as they please; they do not make it under self-selected circumstances, but under circumstances existing already, given and transmitted from the past. The tradition of all dead generations weighs like a nightmare on the brains of the living."
Interview by Alejandro Alvarfer. A slightly shortened version of this interview can be found in issue 7 of Bruxismo which at the time I of posting it here was still available for sale from the following link. https://colectivobruxista.es/producto/bruxismo7/?v=a33c1ea972fc

I never much cared for marzipan as a child. I think it was a combination of the texture and flavour that didn’t appeal to me. Although it could simply have been the fact that I was only ever offered bad marzipan.
Looking back at some of my old marzipan reviews, it’s clear I wasn’t much of a fan, well into adulthood. But over the years my tastes have changed. I’ve also been lucky enough to try much higher quality confections, and it’s fair to say I’ve come around to the marvels of marzipan.
Recently, a representative of Niederegger, one of Europe’s best known marzipan producers, got in touch to ask if I’d like to try some of their latest range and a few days later, a rather delightful box of treats arrived in the post. This chonky 125g monster immediately caught my eye.
Described as a ‘loaf’, I can see the resemblance , however to me it looks more like a tightly wrapped German sausage.

Once unwrapped, we can see it’s actually a rather unusual dome-shaped chocolate bar. Cutting through it reveals a thin chocolate shell and a whole lot of marzipan.
Cutting into it and as you can see, it looks great. It’s a substantial feast, full of toffee-hazelnut marzipan goodness. And you’ll be pleased to know, it tastes great too.
Looking back, I think one of the things I didn’t like about the marzipan I had as a child was the ultra-smooth uniform texture that didn’t feel particularly pleasant in the mouth. This marzipan crumbles. It has bits. There’s stuff going on that just makes it more interesting that the overwhelming blandness of the cheap, packet marzipan that covered so many childhood cakes.

If I have one complaint it’s that the toffee flavour is a little subtle. The hazelnuts are definitely there, but the toffee is a little lost. That said, the flavour balance and level of sweetness is great. Not too sweet to be sickly, but sweet enough to mean that one bite is never enough. It took all my strength and courage not to eat the whole bar in one go.
Looking at the Niederegger website, there’s a few other flavours in the “loaf” range; Strawberry Cheesecake, Hazelnut Praline and Double Chocolate although they appear to be smaller 75g bars. I’ll definitely be seeking them out. I suggest you do to.
Information- Buy it online from:
- Contains dark chocolate (50% cocoa solids).
- Filed under germany, hazelnut, marzipan, niederegger.
The post Niederegger Loaf of the Year Hazelnut Toffee appeared first on Chocablog.

I don’t get a chance to review a lot of bean-to-bar chocolate these days. That’s partly because I don’t get sent chocolate for review quite as often as I used to, but also because a maker has to be pretty special to catch my eye in a world where new chocolate companies are popping up every week.

I’d heard of Fossa Chocolate when my friend Jess offered to send me a few bars, but I’d never tried them for myself.

Fossa are a small maker based in Singapore. They work closely with farmers, co-operatives and local ingredient suppliers to produce some extraordinary and unusual flavours. I’ve just got three to try here, but I can say right from the start that I’ll be seeking out more!

First off, I have to say how much I like this kind of packaging. It’s simple, elegant and plastic free. The bars are easy to reseal after you break a piece off, and you don’t have to wrestle with it to close it up neatly. The simple colour scheme adds a touch of class and makes it easy to tell the varieties apart.

I wanted to start my taste journey with the unflavoured dark chocolate; the 70% Indonesia Pak Eddy. The tasting notes on the bar say “Creamy almonds with notes of raisins and floral undertones”, but as we all know, everyone perceives flavours slightly differently, and there will always be minor differences between batches of craft chocolate anyway.
The bar has a great snap and a wonderful, rich aroma. It has a great melt too. A small piece on the tongue quickly and evenly starts to melt away releasing all its wonderful flavour. It’s chocolatey at first, but the more it melts, the more of those fruity, raisin flavour notes come forward. The balance is spot on, not too sweet, but not a hint of bitterness. Wonderful stuff.

Next up, I wanted to try the one I knew would be most challenging. “Salted Egg Cereal – Your favourite tze-char dish in a bar”.
I confess I didn’t know what tze-char was, but Wikipedia tells me that it’s a Singaporean term used to “describe a Chinese food stall which provides a wide selection of common and affordable dishes”. So, a local dish that will likely be much more familiar to Singaporean people. Although, I’m not sure if they would be familiar with it in chocolate bar form!
I’m not a big fan of the flavour of egg (eggs are best used in cakes, as everyone knows), and as expected I did find it a little challenging. It’s a flavoured white chocolate, a little softer than the dark chocolate, but with a very pleasant creamy, cereal aroma.

The first taste is of a pleasant white chocolate, but as it melts, you get more of the egg flavour and a decent amount of spicy heat. A quick glance at the ingredients tells me it does contain curry leaves and chilli padi.
This is a tough one for me to review, because I’m not personally keen on the flavour, but it is clearly very well made and well balanced. I think it will appeal to those a little more familiar with “the original” than me.

Finally, we have Honey Orchid Dancong Hongcha Tea. A quick glance at the Fossa website tells me:
“Mi Lan Xiang (Honey Orchid) is a dancong tea cultivated in the Phoenix Mountain of Guangdong Province.
This lot was hand-harvested from Zhen Ya village in Spring 2010. Made into a Hongcha (western black tea) and further aged for eight years, this tea is incredibly smooth and creamy with very low astringence. It has a characteristic lychee fragrance and red date sweetness. Complemented by the biscuity Kokoa Kamili cacao from Tanzania, it is a delicious bar to be slowly savoured.”
There’s a lot to love here. First off, I love tea flavoured chocolates. They’re difficult to make, but when done right can be truly wonderful. I also love lychee flavour notes in chocolate, and I truly love the Kokoa Kamili cocoa beans from Tanzania. I’ve worked with them myself, and they’re amongst my favourite in the world.
So does the chocolate live up to all that? Totally.
Those lychee tasting notes are spot on. In fact, you’d be forgiven for thinking this bar wasn’t packed full of real lychee fruit. But it isn’t; the only flavouring here is tea. And while there is a little hint of a more recognisable tea flavour toward the end, it’s that smooth, tropical fruit flavour that shines through. I love this bar. It makes me want to seek some of the tea to try on its own.
Overall, an outstanding little selection of bars from Fossa. Their range is quite large, so I’m looking forward to trying more soon. You should seek some out too.
Information- Buy it online from:
- Contains dark chocolate, milk chocolate, white chocolate.
- Cacao Origin: Indonesia, Tanzania
- Filed under bean to bar, egg, fossa, singapore, tea.
The post Fossa Chocolate, Singapore appeared first on Chocablog.
The ARPANET changed computing forever by proving that computers of wildly different manufacture could be connected using standardized protocols. In my post on the historical significance of the ARPANET, I mentioned a few of those protocols, but didn't describe them in any detail. So I wanted to take a closer look at them. I also wanted to see how much of the design of those early protocols survives in the protocols we use today.
The ARPANET protocols were, like our modern internet protocols, organized into layers.1 The protocols in the higher layers ran on top of the protocols in the lower layers. Today the TCP/IP suite has five layers (the Physical, Link, Network, Transport, and Application layers), but the ARPANET had only three layers—or possibly four, depending on how you count them.
I'm going to explain how each of these layers worked, but first an aside about who built what in the ARPANET, which you need to know to understand why the layers were divided up as they were.
Some Quick Historical ContextThe ARPANET was funded by the US federal government, specifically the Advanced Research Projects Agency within the Department of Defense (hence the name "ARPANET"). The US government did not directly build the network; instead, it contracted the work out to a Boston-based consulting firm called Bolt, Beranek, and Newman, more commonly known as BBN.
BBN, in turn, handled many of the responsibilities for implementing the network but not all of them. What BBN did was design and maintain a machine known as the Interface Message Processor, or IMP. The IMP was a customized Honeywell minicomputer, one of which was delivered to each site across the country that was to be connected to the ARPANET. The IMP served as a gateway to the ARPANET for up to four hosts at each host site. It was basically a router. BBN controlled the software running on the IMPs that forwarded packets from IMP to IMP, but the firm had no direct control over the machines that would connect to the IMPs and become the actual hosts on the ARPANET.
The host machines were controlled by the computer scientists that were the end users of the network. These computer scientists, at host sites across the country, were responsible for writing the software that would allow the hosts to talk to each other. The IMPs gave hosts the ability to send messages to each other, but that was not much use unless the hosts agreed on a format to use for the messages. To solve that problem, a motley crew consisting in large part of graduate students from the various host sites formed themselves into the Network Working Group, which sought to specify protocols for the host computers to use.
So if you imagine a single successful network interaction over the ARPANET, (sending an email, say), some bits of engineering that made the interaction successful were the responsibility of one set of people (BBN), while other bits of engineering were the responsibility of another set of people (the Network Working Group and the engineers at each host site). That organizational and logistical happenstance probably played a big role in motivating the layered approach used for protocols on the ARPANET, which in turn influenced the layered approach used for TCP/IP.
Okay, Back to the Protocols The ARPANET protocol hierarchy.
The ARPANET protocol hierarchy.
The protocol layers were organized into a hierarchy. At the very bottom was "level 0."2 This is the layer that in some sense doesn't count, because on the ARPANET this layer was controlled entirely by BBN, so there was no need for a standard protocol. Level 0 governed how data passed between the IMPs. Inside of BBN, there were rules governing how IMPs did this; outside of BBN, the IMP sub-network was a black box that just passed on any data that you gave it. So level 0 was a layer without a real protocol, in the sense of a publicly known and agreed-upon set of rules, and its existence could be ignored by software running on the ARPANET hosts. Loosely speaking, it handled everything that falls under the Physical, Link, and Internet layers of the TCP/IP suite today, and even quite a lot of the Transport layer, which is something I'll come back to at the end of this post.
The "level 1" layer established the interface between the ARPANET hosts and the IMPs they were connected to. It was an API, if you like, for the black box level 0 that BBN had built. It was also referred to at the time as the IMP-Host Protocol. This protocol had to be written and published because, when the ARPANET was first being set up, each host site had to write its own software to interface with the IMP. They wouldn't have known how to do that unless BBN gave them some guidance.
The IMP-Host Protocol was specified by BBN in a lengthy document called BBN Report 1822. The document was revised many times as the ARPANET evolved; what I'm going to describe here is roughly the way the IMP-Host protocol worked as it was initially designed. According to BBN's rules, hosts could pass messages to their IMPs no longer than 8095 bits, and each message had a leader that included the destination host number and something called a link number.3 The IMP would examine the designation host number and then dutifully forward the message into the network. When messages were received from a remote host, the receiving IMP would replace the destination host number with the source host number before passing it on to the local host. Messages were not actually what passed between the IMPs themselves—the IMPs broke the messages down into smaller packets for transfer over the network—but that detail was hidden from the hosts.
 The Host-IMP message leader format, as of 1969. Diagram from BBN Report
1763.
The Host-IMP message leader format, as of 1969. Diagram from BBN Report
1763.
The link number, which could be any number from 0 to 255, served two purposes. It was used by higher level protocols to establish more than one channel of communication between any two hosts on the network, since it was conceivable that there might be more than one local user talking to the same destination host at any given time. (In other words, the link numbers allowed communication to be multiplexed between hosts.) But it was also used at the level 1 layer to control the amount of traffic that could be sent between hosts, which was necessary to prevent faster computers from overwhelming slower ones. As initially designed, the IMP-Host Protocol limited each host to sending just one message at a time over each link. Once a given host had sent a message along a link to a remote host, it would have to wait to receive a special kind of message called an RFNM (Request for Next Message) from the remote IMP before sending the next message along the same link. Later revisions to this system, made to improve performance, allowed a host to have up to eight messages in transit to another host at a given time.4
The "level 2" layer is where things really start to get interesting, because it was this layer and the one above it that BBN and the Department of Defense left entirely to the academics and the Network Working Group to invent for themselves. The level 2 layer comprised the Host-Host Protocol, which was first sketched in RFC 9 and first officially specified by RFC 54. A more readable explanation of the Host-Host Protocol is given in the ARPANET Protocol Handbook.
The Host-Host Protocol governed how hosts created and managed connections with each other. A connection was a one-way data pipeline between a write socket on one host and a read socket on another host. The "socket" concept was introduced on top of the limited level-1 link facility (remember that the link number can only be one of 256 values) to give programs a way of addressing a particular process running on a remote host. Read sockets were even-numbered while write sockets were odd-numbered; whether a socket was a read socket or a write socket was referred to as the socket's gender. There were no "port numbers" like in TCP. Connections could be opened, manipulated, and closed by specially formatted Host-Host control messages sent between hosts using link 0, which was reserved for that purpose. Once control messages were exchanged over link 0 to establish a connection, further data messages could then be sent using another link number picked by the receiver.
Host-Host control messages were identified by a three-letter mnemonic. A connection was established when two hosts exchanged a STR (sender-to-receiver) message and a matching RTS (receiver-to-sender) message—these control messages were both known as Request for Connection messages. Connections could be closed by the CLS (close) control message. There were further control messages that changed the rate at which data messages were sent from sender to receiver, which were needed to ensure again that faster hosts did not overwhelm slower hosts. The flow control already provided by the level 1 protocol was apparently not sufficient at level 2; I suspect this was because receiving an RFNM from a remote IMP was only a guarantee that the remote IMP had passed the message on to the destination host, not that the host had fully processed the message. There was also an INR (interrupt-by-receiver) control message and an INS (interrupt-by-sender) control message that were primarily for use by higher-level protocols.
The higher-level protocols all lived in "level 3", which was the Application layer of the ARPANET. The Telnet protocol, which provided a virtual teletype connection to another host, was perhaps the most important of these protocols, but there were many others in this level too, such as FTP for transferring files and various experiments with protocols for sending email.
One protocol in this level was not like the others: the Initial Connection Protocol (ICP). ICP was considered to be a level-3 protocol, but really it was a kind of level-2.5 protocol, since other level-3 protocols depended on it. ICP was needed because the connections provided by the Host-Host Protocol at level 2 were only one-way, but most applications required a two-way (i.e. full-duplex) connection to do anything interesting. ICP specified a two-step process whereby a client running on one host could connect to a long-running server process on another host. The first step involved establishing a one-way connection from the server to the client using the server process' well-known socket number. The server would then send a new socket number to the client over the established connection. At that point, the existing connection would be discarded and two new connections would be opened, a read connection based on the transmitted socket number and a write connection based on the transmitted socket number plus one. This little dance was a necessary prelude to most things—it was the first step in establishing a Telnet connection, for example.
That finishes our ascent of the ARPANET protocol hierarchy. You may have been expecting me to mention a "Network Control Protocol" at some point. Before I sat down to do research for this post and my last one, I definitely thought that the ARPANET ran on a protocol called NCP. The acronym is occasionally used to refer to the ARPANET protocols as a whole, which might be why I had that idea. RFC 801, for example, talks about transitioning the ARPANET from "NCP" to "TCP" in a way that makes it sound like NCP is an ARPANET protocol equivalent to TCP. But there has never been a "Network Control Protocol" for the ARPANET (even if Encyclopedia Britannica thinks so), and I suspect people have mistakenly unpacked "NCP" as "Network Control Protocol" when really it stands for "Network Control Program." The Network Control Program was the kernel-level program running in each host responsible for handling network communication, equivalent to the TCP/IP stack in an operating system today. "NCP", as it's used in RFC 801, is a metonym, not a protocol.
A Comparison with TCP/IPThe ARPANET protocols were all later supplanted by the TCP/IP protocols (with the exception of Telnet and FTP, which were easily adapted to run on top of TCP). Whereas the ARPANET protocols were all based on the assumption that the network was built and administered by a single entity (BBN), the TCP/IP protocol suite was designed for an inter-net, a network of networks where everything would be more fluid and unreliable. That led to some of the more immediately obvious differences between our modern protocol suite and the ARPANET protocols, such as how we now distinguish between a Network layer and a Transport layer. The Transport layer-like functionality that in the ARPANET was partly implemented by the IMPs is now the sole responsibility of the hosts at the network edge.
What I find most interesting about the ARPANET protocols though is how so much of the transport-layer functionality now in TCP went through a janky adolescence on the ARPANET. I'm not a networking expert, so I pulled out my college networks textbook (Kurose and Ross, let's go), and they give a pretty great outline of what a transport layer is responsible for in general. To summarize their explanation, a transport layer protocol must minimally do the following things. Here segment is basically equivalent to message as the term was used on the ARPANET:
- Provide a delivery service between processes and not just host machines (transport layer multiplexing and demultiplexing)
- Provide integrity checking on a per-segment basis (i.e. make sure there is no data corruption in transit)
A transport layer could also, like TCP does, provide reliable data transfer, which means:
- Segments are delivered in order
- No segments go missing
- Segments aren't delivered so fast that they get dropped by the receiver (flow control)
It seems like there was some confusion on the ARPANET about how to do multiplexing and demultiplexing so that processes could communicate—BBN introduced the link number to do that at the IMP-Host level, but it turned out that socket numbers were necessary at the Host-Host level on top of that anyway. Then the link number was just used for flow control at the IMP-Host level, but BBN seems to have later abandoned that in favor of doing flow control between unique pairs of hosts, meaning that the link number started out as this overloaded thing only to basically became vestigial. TCP now uses port numbers instead, doing flow control over each TCP connection separately. The process-process multiplexing and demultiplexing lives entirely inside TCP and does not leak into a lower layer like on the ARPANET.
It's also interesting to see, in light of how Kurose and Ross develop the ideas behind TCP, that the ARPANET started out with what Kurose and Ross would call a strict "stop-and-wait" approach to reliable data transfer at the IMP-Host level. The "stop-and-wait" approach is to transmit a segment and then refuse to transmit any more segments until an acknowledgment for the most recently transmitted segment has been received. It's a simple approach, but it means that only one segment is ever in flight across the network, making for a very slow protocol—which is why Kurose and Ross present "stop-and-wait" as merely a stepping stone on the way to a fully featured transport layer protocol. On the ARPANET, "stop-and-wait" was how things worked for a while, since, at the IMP-Host level, a Request for Next Message had to be received in response to every outgoing message before any further messages could be sent. To be fair to BBN, they at first thought this would be necessary to provide flow control between hosts, so the slowdown was intentional. As I've already mentioned, the RFNM requirement was later relaxed for the sake of better performance, and the IMPs started attaching sequence numbers to messages and keeping track of a "window" of messages in flight in the more or less the same way that TCP implementations do today.5
So the ARPANET showed that communication between heterogeneous computing systems is possible if you get everyone to agree on some baseline rules. That is, as I've previously argued, the ARPANET's most important legacy. But what I hope this closer look at those baseline rules has revealed is just how much the ARPANET protocols also influenced the protocols we use today. There was certainly a lot of awkwardness in the way that transport-layer responsibilities were shared between the hosts and the IMPs, sometimes redundantly. And it's really almost funny in retrospect that hosts could at first only send each other a single message at a time over any given link. But the ARPANET experiment was a unique opportunity to learn those lessons by actually building and operating a network, and it seems those lessons were put to good use when it came time to upgrade to the internet as we know it today.
If you enjoyed this post, more like it come out every four weeks! Follow @TwoBitHistory on Twitter or subscribe to the RSS feed to make sure you know when a new post is out.
Previously on TwoBitHistory…
Trying to get back on this horse!
— TwoBitHistory (@TwoBitHistory) February 7, 2021
My latest post is my take (surprising and clever, of course) on why the ARPANET was such an important breakthrough, with a fun focus on the conference where the ARPANET was shown off for the first time:https://t.co/8SRY39c3St
-
The protocol layering thing was invented by the Network Working Group. This argument is made in RFC 871. The layering thing was also a natural extension of how BBN divided responsibilities between hosts and IMPs, so BBN deserves some credit too. ↩
-
The "level" terminology was used by the Network Working Group. See e.g. RFC 100. ↩
-
In later revisions of the IMP-Host protocol, the leader was expanded and the link number was upgraded to a message ID. But the Host-Host protocol continued to make use of only the high-order eight bits of the message ID field, treating it as a link number. See the "Host-to-Host" protocol section of the ARPANET Protocol Handbook. ↩
-
John M. McQuillan and David C. Walden. "The ARPA Network Design Decisions," p. 284, https://www.walden-family.com/public/whole-paper.pdf. Accessed 8 March 2021. ↩
-
Ibid. ↩

A year is a long time in blogging, but it’s a whopping thirteen years since we last looked at a product from Summerdown Farms in Hampshire.
Back in 2008, Simon looked at some Summerdown peppermint creams. I confess I hadn’t gone through the complete Chocablog archives when they got in touch to ask if they could send a care package, but given the time that has passed, I’m happy looking at them again. As well as Peppermint Creams, Summerdown Farms sent some Peppermint Thins, some Peppermint Tea (not eligible for review on Chocablog, of course!) and a rather lovely mug.
Just a side note to PR people sending gifts; I cannot be bribed. Ever. But… it is a very nice mug.

First things first, it’s important to note that Summerdown is a peppermint farm, not a chocolate maker or chocolatier. They grow Black Mitcham variety peppermint on their 100 acre farm, then the peppermint oil to two unnamed chocolate makers in the north of England. This is a perfectly normal thing to do, but it does mean we don’t have a lot of information about the actual chocolate here.
One thing Summerdown did tell me is that the cocoa is sourced through the Cocoa Horizons project. Cocoa Horizons is a Barry Callebaut initiative (their slightly dubious answer to Fair Trade), so we can assume this is a standard Callebaut dark chocolate blend. One thing the label does tell us is that it’s 55% cocoa solids.

The precise details of the chocolate, however, are not especially relevant here. From the moment you open the box, you’re greeted by the strong, fresh aroma of peppermint. When you bite into one, that Black Mitcham peppermint is really all you can taste. The chocolate is their primarily as a vessel to hold the fondant cream in place.
That’s not to say the flavour is overpowering. It’s actually relatively restrained and well rounded, but mint is one of those flavours that naturally tends to hide everything else. The mint flavour here is actually very pleasant and refreshing. The texture is good too, with a nice snap to the thin chocolate shell and a very smooth creamy fondant.
The flavour does linger in the mouth long after the chocolate has gone, but it does so in a very pleasant way.
Peppermint Thins
Also included in my care package was a box of Peppermint thins. These are thin, solid discs of chocolate flavoured with peppermint oil. They’re nice enough as a refreshing after dinner type mint, but they’re just not quite as interesting as the peppermint creams.I also noticed they al have scuffed looking edges, so they’re just not quite as attractive. The flavour is very similar to the peppermint creams, but you do just get a hint of the dark chocolate flavour here as well. I would call these inoffensive rather than spectacular.
Love Or Hate?I’ve never been the biggest fan of mint flavoured chocolate, especially strong peppermint. I wondered if I was alone, so I posted a poll on Twitter and was a little surprised by the result.
I'm really interested, how do you feel about the chocolate and mint combination?
— Dom Ramsey (@DomRamsey) February 11, 2021
If you’re one of the 78% of people that say they love mint chocolate, then I think you’ll enjoy these, especially the peppermint creams. They’re a great alternative to some of the better known chocolate mint brands, and it just seems like a lot of attention has been paid to flavour balance.
Highly recommended for mint lovers, but if you’re one of the 22% then I don’t think these will change your mind just yet.
Information- Buy it online from:
- Contains dark chocolate (55% cocoa solids).
- Filed under mint, summerdown, uk.
The post Summerdown Farms Peppermint Chocolates appeared first on Chocablog.
If you run an image search for the word "ARPANET," you will find lots of maps showing how the government research network expanded steadily across the country throughout the late '60s and early '70s. I'm guessing that most people reading or hearing about the ARPANET for the first time encounter one of these maps.
Obviously, the maps are interesting—it's hard to believe that there were once so few networked computers that their locations could all be conveyed with what is really pretty lo-fi cartography. (We're talking 1960s overhead projector diagrams here. You know the vibe.) But the problem with the maps, drawn as they are with bold lines stretching across the continent, is that they reinforce the idea that the ARPANET's paramount achievement was connecting computers across the vast distances of the United States for the first time.
Today, the internet is a lifeline that keeps us tethered to each other even as an airborne virus has us all locked up indoors. So it's easy to imagine that, if the ARPANET was the first draft of the internet, then surely the world that existed before it was entirely disconnected, since that's where we'd be without the internet today, right? The ARPANET must have been a big deal because it connected people via computers when that hadn't before been possible.
That view doesn't get the history quite right. It also undersells what made the ARPANET such a breakthrough.
The DebutThe Washington Hilton stands near the top of a small rise about a mile and a half northeast of the National Mall. Its two white-painted modern facades sweep out in broad semicircles like the wings of a bird. The New York Times, reporting on the hotel's completion in 1965, remarked that the building looks "like a sea gull perched on a hilltop nest."1
The hotel hides its most famous feature below ground. Underneath the driveway roundabout is an enormous ovoid event space known as the International Ballroom, which was for many years the largest pillar-less ballroom in DC. In 1967, the Doors played a concert there. In 1968, Jimi Hendrix also played a concert there. In 1972, a somewhat more sedate act took over the ballroom to put on the inaugural International Conference on Computing Communication, where a promising research project known as the ARPANET was demonstrated publicly for the first time.
The 1972 ICCC, which took place from October 24th to 26th, was attended by about 800 people.2 It brought together all of the leading researchers in the nascent field of computer networking. According to internet pioneer Bob Kahn, "if somebody had dropped a bomb on the Washington Hilton, it would have destroyed almost all of the networking community in the US at that point."3
Not all of the attendees were computer scientists, however. An advertisement for the conference claimed it would be "user-focused" and geared toward "lawyers, medical men, economists, and government men as well as engineers and communicators."4 Some of the conference's sessions were highly technical, such as the session titled "Data Network Design Problems I" and its sequel session, "Data Network Design Problems II." But most of the sessions were, as promised, focused on the potential social and economic impacts of computer networking. One session, eerily prescient today, sought to foster a discussion about how the legal system could act proactively "to safeguard the right of privacy in the computer data bank."5
The ARPANET demonstration was intended as a side attraction of sorts for the attendees. Between sessions, which were held either in the International Ballroom or elsewhere on the lower level of the hotel, attendees were free to wander into the Georgetown Ballroom (a smaller ballroom/conference room down the hall from the big one),6 where there were 40 terminals from a variety of manufacturers set up to access the ARPANET.7 These terminals were dumb terminals—they only handled input and output and could do no computation on their own. (In fact, in 1972, it's likely that all of these terminals were hardcopy terminals, i.e. teletype machines.) The terminals were all hooked up to a computer known as a Terminal Interface Message Processor or TIP, which sat on a raised platform in the middle of the room. The TIP was a kind of archaic router specially designed to connect dumb terminals to the ARPANET. Using the terminals and the TIP, the ICCC attendees could experiment with logging on and accessing some of the computers at the 29 host sites then comprising the ARPANET.8
To exhibit the network's capabilities, researchers at the host sites across the country had collaborated to prepare 19 simple "scenarios" for users to experiment with. These scenarios were compiled into a booklet that was handed to conference attendees as they tentatively approached the maze of wiring and terminals.9 The scenarios were meant to prove that the new technology worked but also that it was useful, because so far the ARPANET was "a highway system without cars," and its Pentagon funders hoped that a public demonstration would excite more interest in the network.10
The scenarios thus showed off a diverse selection of the software that could be accessed over the ARPANET: There were programming language interpreters, one for a Lisp-based language at MIT and another for a numerical computing environment called Speakeasy hosted at UCLA; there were games, including a chess program and an implementation of Conway's Game of Life; and—perhaps most popular among the conference attendees—there were several AI chat programs, including the famous ELIZA chat program developed at MIT by Joseph Weizenbaum.
The researchers who had prepared the scenarios were careful to list each command that users were expected to enter at their terminals. This was especially important because the sequence of commands used to connect to any given ARPANET host could vary depending on the host in question. To experiment with the AI chess program hosted on the MIT Artificial Intelligence Laboratory's PDP-10 minicomputer, for instance, conference attendees were instructed to enter the following:
[LF], [SP], and [CR] below stand for the line feed, space, and carriage return keys respectively. I've explained each command after //, but this syntax was not used for the annotations in the original.
@r [LF] // Reset the TIP @e [SP] r [LF] // "Echo remote" setting, host echoes characters rather than TIP @L [SP] 134 [LF] // Connect to host number 134 :login [SP] iccXXX [CR] // Login to the MIT AI Lab's system, where "XXX" should be user's initials :chess [CR] // Start chess program
If conference attendees were successfully able to enter those commands, their reward was the opportunity to play around with some of the most cutting-edge chess software available at the time, where the layout of the board was represented like this:
BR BN BB BQ BK BB BN BR BP BP BP BP ** BP BP BP -- ** -- ** -- ** -- ** ** -- ** -- BP -- ** -- -- ** -- ** WP ** -- ** ** -- ** -- ** -- ** -- WP WP WP WP -- WP WP WP WR WN WB WQ WK WB WN WR
In contrast, to connect to UCLA's IBM System/360 and run the Speakeasy numerical computing environment, conference attendees had to enter the following:
@r [LF] // Reset the TIP @t [SP] o [SP] L [LF] // "Transmit on line feed" setting @i [SP] L [LF] // "Insert line feed" setting, i.e. send line feed with each carriage return @L [SP] 65 [LF] // Connect to host number 65 tso // Connect to IBM Time-Sharing Option system logon [SP] icX [CR] // Log in with username, where "X" should be a freely chosen digit iccc [CR] // This is the password (so secure!) speakez [CR] // Start Speakeasy
Successfully running that gauntlet gave attendees the power to multiply and transpose and do other operations on matrices as quickly as they could input them at their terminal:
:+! a=m*transpose(m);a [CR] :+! eigenvals(a) [CR]
Many of the attendees were impressed by the demonstration, but not for the reasons that we, from our present-day vantage point, might assume. The key piece of context hard to keep in mind today is that, in 1972, being able to use a computer remotely, even from a different city, was not new. Teletype devices had been used to talk to distant computers for decades already. Almost a full five years before the ICCC, Bill Gates was in a Seattle high school using a teletype to run his first BASIC programs on a General Electric computer housed elsewhere in the city. Merely logging in to a host computer and running a few commands or playing a text-based game was routine. The software on display here was pretty neat, but the two scenarios I've told you about so far could ostensibly have been experienced without going over the ARPANET.
Of course, something new was happening under the hood. The lawyers, policy-makers, and economists at the ICCC might have been enamored with the clever chess program and the chat bots, but the networking experts would have been more interested in two other scenarios that did a better job of demonstrating what the ARPANET project had achieved.
The first of these scenarios involved a program called NETWRK running on MIT's ITS operating system. The NETWRK command was the entrypoint for several subcommands that could report various aspects of the ARPANET's operating status. The SURVEY subcommand reported which hosts on the network were functioning and available (they all fit on a single list), while the SUMMARY.OF.SURVEY subcommand aggregated the results of past SURVEY runs to report an "up percentage" for each host as well as how long, on average, it took for each host to respond to messages. The output of the SUMMARY.OF.SURVEY subcommand was a table that looked like this:
--HOST-- -#- -%-UP- -RESP- UCLA-NMC 001 097% 00.80 SRI-ARC 002 068% 01.23 UCSB-75 003 059% 00.63 ...
The host number field, as you can see, has room for no more than three digits (ha!). Other NETWRK subcommands allowed users to look at summary of survey results over a longer historical period or to examine the log of survey results for a single host.
The second of these scenarios featured a piece of software called the SRI-ARC Online System being developed at Stanford. This was a fancy piece of software with lots of functionality (it was the software system that Douglas Engelbart demoed in the "Mother of All Demos"), but one of the many things it could do was make use of what was essentially a file hosting service run on the host at UC Santa Barbara. From a terminal at the Washington Hilton, conference attendees could copy a file created at Stanford onto the host at UCSB simply by running a copy command and answering a few of the computer's questions:
[ESC], [SP], and [CR] below stand for the escape, space, and carriage return keys respectively. The words in parentheses are prompts printed by the computer. The escape key is used to autocomplete the filename on the third line. The file being copied here is called <system>sample.txt;1, where the trailing one indicates the file's version number and <system> indicates the directory. This was a convention for filenames used by the TENEX operating system.11
@copy (TO/FROM UCSB) to (FILE) <system>sample [ESC] .TXT;1 [CR] (CREATE/REPLACE) create
These two scenarios might not look all that different from the first two, but they were remarkable. They were remarkable because they made it clear that, on the ARPANET, humans could talk to computers but computers could also talk to each other. The SURVEY results collected at MIT weren't collected by a human regularly logging in to each machine to check if it was up—they were collected by a program that knew how to talk to the other machines on the network. Likewise, the file transfer from Stanford to UCSB didn't involve any humans sitting at terminals at either Stanford or UCSB—the user at a terminal in Washington DC was able to get the two computers to talk each other merely by invoking a piece of software. Even more, it didn't matter which of the 40 terminals in the Ballroom you were sitting at, because you could view the MIT network monitoring statistics or store files at UCSB using any of the terminals with almost the same sequence of commands.
This is what was totally new about the ARPANET. The ICCC demonstration didn't just involve a human communicating with a distant computer. It wasn't just a demonstration of remote I/O. It was a demonstration of software remotely communicating with other software, something nobody had seen before.
To really appreciate why it was this aspect of the ARPANET project that was important and not the wires-across-the-country, physical connection thing that the host maps suggest (the wires were leased phone lines anyhow and were already there!), consider that, before the ARPANET project began in 1966, the ARPA offices in the Pentagon had a terminal room. Inside it were three terminals. Each connected to a different computer; one computer was at MIT, one was at UC Berkeley, and another was in Santa Monica.12 It was convenient for the ARPA staff that they could use these three computers even from Washington DC. But what was inconvenient for them was that they had to buy and maintain terminals from three different manufacturers, remember three different login procedures, and familiarize themselves with three different computing environments in order to use the computers. The terminals might have been right next to each other, but they were merely extensions of the host computing systems on the other end of the wire and operated as differently as the computers did. Communicating with a distant computer was possible before the ARPANET; the problem was that the heterogeneity of computing systems limited how sophisticated the communication could be.
Come Together, Right NowSo what I'm trying to drive home here is that there is an important distinction between statement A, "the ARPANET connected people in different locations via computers for the first time," and statement B, "the ARPANET connected computer systems to each other for the first time." That might seem like splitting hairs, but statement A elides some illuminating history in a way that statement B does not.
To begin with, the historian Joy Lisi Rankin has shown that people were socializing in cyberspace well before the ARPANET came along. In A People's History of Computing in the United States, she describes several different digital communities that existed across the country on time-sharing networks prior to or apart from the ARPANET. These time-sharing networks were not, technically speaking, computer networks, since they consisted of a single mainframe computer running computations in a basement somewhere for many dumb terminals, like some portly chthonic creature with tentacles sprawling across the country. But they nevertheless enabled most of the social behavior now connoted by the word "network" in a post-Facebook world. For example, on the Kiewit Network, which was an extension of the Dartmouth Time-Sharing System to colleges and high schools across the Northeast, high school students collaboratively maintained a "gossip file" that allowed them to keep track of the exciting goings-on at other schools, "creating social connections from Connecticut to Maine."13 Meanwhile, women at Mount Holyoke College corresponded with men at Dartmouth over the network, perhaps to arrange dates or keep in touch with boyfriends.14 This was all happening in the 1960s. Rankin argues that by ignoring these early time-sharing networks we impoverish our understanding of how American digital culture developed over the last 50 years, leaving room for a "Silicon Valley mythology" that credits everything to the individual genius of a select few founding fathers.
As for the ARPANET itself, if we recognize that the key challenge was connecting the computer systems and not just the physical computers, then that might change what we choose to emphasize when we tell the story of the innovations that made the ARPANET possible. The ARPANET was the first ever packet-switched network, and lots of impressive engineering went into making that happen. I think it's a mistake, though, to say that the ARPANET was a breakthrough because it was the first packet-switched network and then leave it at that. The ARPANET was meant to make it easier for computer scientists across the country to collaborate; that project was as much about figuring out how different operating systems and programs written in different languages would interface with each other than it was about figuring out how to efficiently ferry data back and forth between Massachusetts and California. So the ARPANET was the first packet-switched network, but it was also an amazing standards success story—something I find especially interesting given how many times I've written about failed standards on this blog.
Inventing the protocols for the ARPANET was an afterthought even at the time, so naturally the job fell to a group made up largely of graduate students. This group, later known as the Network Working Group, met for the first time at UC Santa Barbara in August of 1968.15 There were 12 people present at that first meeting, most of whom were representatives from the four universities that were to be the first host sites on the ARPANET when the equipment was ready.16 Steve Crocker, then a graduate student at UCLA, attended; he told me over a Zoom call that it was all young guys at that first meeting, and that Elmer Shapiro, who chaired the meeting, was probably the oldest one there at around 38. ARPA had not put anyone in charge of figuring out how the computers would communicate once they were connected, but it was obvious that some coordination was necessary. As the group continued to meet, Crocker kept expecting some "legitimate adult" with more experience and authority to fly out from the East Coast to take over, but that never happened. The Network Working Group had ARPA's tacit approval—all those meetings involved lots of long road trips, and ARPA money covered the travel expenses—so they were it.17
The Network Working Group faced a huge challenge. Nobody had ever sat down to connect computer systems together in a general-purpose way; that flew against all of the assumptions that prevailed in computing in the late 1960s:
The typical mainframe of the period behaved as if it were the only computer in the universe. There was no obvious or easy way to engage two diverse machines in even the minimal communication needed to move bits back and forth. You could connect machines, but once connected, what would they say to each other? In those days a computer interacted with devices that were attached to it, like a monarch communicating with his subjects. Everything connected to the main computer performed a specific task, and each peripheral device was presumed to be ready at all times for a fetch-my-slippers type command…. Computers were strictly designed for this kind of interaction; they send instructions to subordinate card readers, terminals, and tape units, and they initiate all dialogues. But if another device in effect tapped the computer on the shoulder with a signal and said, "Hi, I'm a computer too," the receiving machine would be stumped.18
As a result, the Network Working Group's progress was initially slow.19 The group did not settle on an "official" specification for any protocol until June, 1970, nearly two years after the group's first meeting.20
But by the time the ARPANET was to be shown off at the 1972 ICCC, all the key protocols were in place. A scenario like the chess scenario exercised many of them. When a user ran the command @e r, short for @echo remote, that instructed the TIP to make use of a facility in the new TELNET virtual teletype protocol to inform the remote host that it should echo the user's input. When a user then ran the command @L 134, short for @login 134, that caused the TIP to invoke the Initial Connection Protocol with host 134, which in turn would cause the remote host to allocate all the necessary resources for the connection and drop the user into a TELNET session. (The file transfer scenario I described may well have made use of the File Transfer Protocol, though that protocol was only ready shortly before the conference.21) All of these protocols were known as "level three" protocols, and below them were the host-to-host protocol at level two (which defined the basic format for the messages the hosts should expect from each other), and the host-to-IMP protocol at level one (which defined how hosts communicated with the routing equipment they were linked to). Incredibly, the protocols all worked.
In my view, the Network Working Group was able to get everything together in time and just generally excel at its task because it adopted an open and informal approach to standardization, as exemplified by the famous Request for Comments (RFC) series of documents. These documents, originally circulated among the members of the Network Working Group by snail mail, were a way of keeping in touch between meetings and soliciting feedback to ideas. The "Request for Comments" framing was suggested by Steve Crocker, who authored the first RFC and supervised the RFC mailing list in the early years, in an attempt to emphasize the open-ended and collaborative nature of what the group was trying to do. That framing, and the availability of the documents themselves, made the protocol design process into a melting pot of contributions and riffs on other people's contributions where the best ideas could emerge without anyone losing face. The RFC process was a smashing success and is still used to specify internet standards today, half a century later.
It's this legacy of the Network Working Group that I think we should highlight when we talk about ARPANET's impact. Though today one of the most magical things about the internet is that it can connect us with people on the other side of the planet, it's only slightly facetious to say that that technology has been with us since the 19th century. Physical distance was conquered well before the ARPANET by the telegraph. The kind of distance conquered by the ARPANET was instead the logical distance between the operating systems, character codes, programming languages, and organizational policies employed at each host site. Implementing the first packet-switched network was of course a major feat of engineering that should also be mentioned, but the problem of agreeing on standards to connect computers that had never been designed to play nice with each other was the harder of the two big problems involved in building the ARPANET—and its solution was the most miraculous part of the ARPANET story.
In 1981, ARPA issued a "Completion Report" reviewing the first decade of the ARPANET's history. In a section with the belabored title, "Technical Aspects of the Effort Which Were Successful and Aspects of the Effort Which Did Not Materialize as Originally Envisaged," the authors wrote:
Possibly the most difficult task undertaken in the development of the ARPANET was the attempt—which proved successful—to make a number of independent host computer systems of varying manufacture, and varying operating systems within a single manufactured type, communicate with each other despite their diverse characteristics.22
There you have it from no less a source than the federal government of the United States.
If you enjoyed this post, more like it come out every four weeks! Follow @TwoBitHistory on Twitter or subscribe to the RSS feed to make sure you know when a new post is out.
Previously on TwoBitHistory…
It's been too long, I know, but I finally got around to writing a new post. This one is about how REST APIs should really be known as FIOH APIs instead (Fuck It, Overload HTTP):https://t.co/xjMZVZgsEz
— TwoBitHistory (@TwoBitHistory) June 28, 2020
-
"Hilton Hotel Opens in Capital Today." The New York Times, 20 March 1965, https://www.nytimes.com/1965/03/20/archives/hilton-hotel-opens-in-capital-today.html?searchResultPosition=1. Accessed 7 Feb. 2021. ↩
-
James Pelkey. Entrepreneurial Capitalism and Innovation: A History of Computer Communications 1968-1988, Chapter 4, Section 12, 2007, http://www.historyofcomputercommunications.info/Book/4/4.12-ICCC%20Demonstration71-72.html. Accessed 7 Feb. 2021. ↩
-
Katie Hafner and Matthew Lyon. Where Wizards Stay Up Late: The Origins of the Internet. New York, Simon & Schuster, 1996, p. 178. ↩
-
"International Conference on Computer Communication." Computer, vol. 5, no. 4, 1972, p. c2, https://www.computer.org/csdl/magazine/co/1972/04/01641562/13rRUxNmPIA. Accessed 7 Feb. 2021. ↩
-
"Program for the International Conference on Computer Communication." The Papers of Clay T. Whitehead, Box 42, https://d3so5znv45ku4h.cloudfront.net/Box+042/013_Speech-International+Conference+on+Computer+Communications,+Washington,+DC,+October+24,+1972.pdf. Accessed 7 Feb. 2021. ↩
-
It's actually not clear to me which room was used for the ARPANET demonstration. Lots of sources talk about a "ballroom," but the Washington Hilton seems to consider the room with the name "Georgetown" more of a meeting room. So perhaps the demonstration was in the International Ballroom instead. But RFC 372 alludes to a booking of the "Georgetown Ballroom" for the demonstration. A floorplan of the Washington Hilton can be found here. ↩
-
Hafner, p. 179. ↩
-
ibid., p. 178. ↩
-
Bob Metcalfe. "Scenarios for Using the ARPANET." Collections-Computer History Museum, https://www.computerhistory.org/collections/catalog/102784024. Accessed 7 Feb. 2021. ↩
-
Hafner, p. 176. ↩
-
Robert H. Thomas. "Planning for ACCAT Remote Site Operations." BBN Report No. 3677, October 1977, https://apps.dtic.mil/sti/pdfs/ADA046366.pdf. Accessed 7 Feb. 2021. ↩
-
Hafner, p. 12. ↩
-
Joy Lisi Rankin. A People's History of Computing in the United States. Cambridge, MA, Harvard University Press, 2018, p. 84. ↩
-
Rankin, p. 93. ↩
-
Steve Crocker. Personal interview. 17 Dec. 2020. ↩
-
Crocker sent me the minutes for this meeting. The document lists everyone who attended. ↩
-
Steve Crocker. Personal interview. ↩
-
Hafner, p. 146. ↩
-
"Completion Report / A History of the ARPANET: The First Decade." BBN Report No. 4799, April 1981, https://walden-family.com/bbn/arpanet-completion-report.pdf, p. II-13. ↩
-
I'm referring here to RFC 54, "Official Protocol Proffering." ↩
-
Hafner, p. 175. ↩
-
"Completion Report / A History of the ARPANET: The First Decade," p. II-29. ↩

Between the end of September and the end of November this year, Horsham briefly had a pop-up cycle lane, created in the space of less than a day by the addition of some bolt-down plastic wands and painted markings, converting one lane of our four/five lane wide inner ring road into a cycle lane.

The Albion Way pop-up lane. Note that, thanks to a watering down of the original scheme, it only went in one direction, and was therefore unlikely to attract people who weren’t already inclined to cycle here before the protection was added.
The reaction to this scheme (and the others across the major towns and cities of West Sussex) was predictably vitriolic and the County Council, whose commitment to active travel is as shallow as a film of diesel on a puddle, rapidly announced they were removing every single one of them – spitefully, even the one that didn’t reduce capacity for motoring.
The opposition to this lane from people driving in the town centre – whose journeys were now sometimes taking longer than before – involved a great deal of what can only be described as selective concern. ‘Concern’ for the safety of people cycling at junctions like the one pictured in the photograph above – concern for safe cycling that has evaporated now that the scheme has been removed. ‘Concern’ that the cycle lane was ‘causing’ pollution (spoiler alert – none of the pop-up cycle lane schemes in West Sussex actually made any difference to air quality) – a concern that manifested itself only in a demand the road should revert to being entirely dominated by private motor vehicles in order to ‘solve’ the problem, and not in anything as meaningful as actually reducing the amount of driving, or stopping altogether. As with the ‘concern’ for the safety of people cycling, don’t bank on these same people raising the issue of air pollution any time soon, unless another opportunity arises from them to shamelessly use it as an argument for prioritising their driving at the expense of modes of transport that don’t pollute.
But the most obviously superficial ‘concern’ was for the emergency services, who were apparently going to get stuck in the congestion ’caused’ by the cycle lane. In turn this would lead, inevitably, to houses burning down, criminals escaping, and people dying in the back of ambulances unable to get to hospital in time.
This was all complete nonsense, of course, because the new arrangement was an obvious and objective improvement for the emergency services. It replaced two potentially clogged lanes of motor traffic (with no way through for an emergency vehicle) with a coned-off open lane that people cycling could easily move out of, if required. Far from being a potential disaster, the new lane provided an easy route for the emergency services to zoom past any stationary motor traffic, getting their patients to hospital, or to the scene of a crime or a fire, far faster than they would do without it.

It is immediately obvious that the cycle lane is exactly the same width as the previous general traffic lane, and consequently an easy way for the emergency services to bypass any static motor traffic.
Shamefully, these bogus ‘concerns’ were reported as apparent fact, without any kind of correction or clarification, in an editorial by the local newspaper celebrating the decision to remove the lane –
“the traffic piled up in the halved capacity for motorists – leading to jams, congestion, pollution and a fear that emergency vehicles would be unable to make headway in a hurry”
Quite why a newspaper which claims to be reputable and trustworthy chose to regurgitate this easily-disprovable silliness about delay to the emergency services even after the decision to remove the lane had already been taken is, frankly, a mystery – not least because the benefits to the emergency services of this lane being in place had already been pointed out to their reporters, several times. (And the newspaper’s offices are actually located on this road – the building next to the giant multi storey car park in the video below – so it wouldn’t have been at all difficult for them to conduct some on-the-ground research).
Needless to say, a few days after this was printed, the pop-up lane was gone, and with the November lockdown ending, the road is once again stacked with two parallel queues of motor vehicles at every traffic light – two queues that will be very difficult for the emergency services to negotiate.
When this road had a pop-up bike lane, people complained it would delay the emergency services, even though the emergency services could use the lane to bypass queues. Now the lane has gone, ambulances *are* going to be delayed, and yet there's complete silence. Funny that. pic.twitter.com/PLCAOSueku
— Mark Treasure (@AsEasyAsRiding) December 4, 2020
Naturally, you might expect that those people who were genuinely concerned about delay to the emergency services would be even more concerned now, given that the lane that allowed the emergency services to bypass queues has gone, replaced, all too frequently, with static motor vehicles. But just as the road has reverted to being entirely dominated by cars, so we seem to have reverted to not caring at all about delays to the emergency services, or indeed to not caring about air quality, or about the safety of the children attempting to cycle around a town that remains unremittingly hostile to their mode of transport – children who, for the first time ever, I saw choosing to cycle on this road.

We won’t be seeing this again any time soon – nor will be seeing any concern for the safety of this boy, now that the lane has gone
The case of the equally short-lived pop-up lane on Kensington High Street presents remarkable parallels. Notably, the space occupied by the pop-up lane, now removed amid claims that it apparently ’caused’ congestion, despite carrying thousands of people a day, has been replaced by intermittently parked-up motor vehicles.
So you take away a safe cycle lane used by thousands a day so a few 'entitled' SUVs can park restricting the entire lane anyway

It’s fair to say that 2020 hasn’t been the best year for most of us. I’m sure you’re looking forward to it being over as much as I am, and what better way to celebrate the end of a terrible year than by treating yourself to some great Zotter Chocolate.
When I’m looking to cheer myself, I’ll usually go for filled or flavoured chocolates more than single origin, high cocoa percentage craft chocolate. It’s quite easy to end up just buying cheep chocolate and feeling guilty, but Zotter is one chocolate maker that lets me satisfy my cravings in the knowledge that I’m getting the best quality, ethically sourced bean-to-bar chocolate at the same time. I’ve reviewed several of their chocolates before, and even visited the factory a few years ago – something I would highly recommend once we can all travel again!

With that in mind, I hit up the Zotter website and bought myself a little selection of Christmas themed chocolates to lift my spirits. Here’s what I ended up with.
Star With Almond PralineZotter’s Mi-Xing Bar range allows you to create your own large chocolate slabs in a huge variety of shapes and flavours. You can choose your base couverture, add fillings and toppings and really make it your own. For the lazy (like myself), they also have a “Best Of” selection of pre-designed slabs, and that’s what we have here.
There’s certainly a lot going here in this chocolate star – so much so that it’s practically a meal in itself. This is a raspberry, caramel and white chocolate couverture star with almond praline with mini cinnamon chocolate stars, cacao nibs covered in white chocolate, crispy passion fruit chocolate pieces, green tea leaves.

What I like best about this is that each bite is gives you a slightly different combination of flavours. At 100g it’s the size of a large chocolate bar, but it’s so much more interesting. And I guess you could also put it on top of your Christmas Tree (well out of reach of small, hungry children of course).
Vegan Heart With Hemp PralineZotter have a lot of options for vegans, but I thought I’d go for one of the more unusual ones with this heart.

The underlying coconut flavour is quite strong in this one, and for my tastes it’s just a little bit too strong and I didn’t get a lot of flavour from the hemp. I did like the raspberry mini hearts and I think this would have worked very well with a more of that raspberry flavour. It’s just a touch too coconutty for my own tastes, and I think if I’d designed it myself I would have gone for a different base couverture.
Still. What could be more 2020 than eating your own broken heart?

Zotter Chocolate Hand Scooped Bars
These filled bars are probably what Zotter is most famous for. They come in a vast range of weird and wonderful flavours, several of which I’ve reviewed here over the years. I picked out a few from their Christmas range to try.

White chocolate mousse with a white chocolate coating tastes exactly like you think it might. It’s creamy, sweet, soft and smooth. In terms of flavour, it’s very simple but it’s also more than a little addictive. White chocolate fans will love it.

The name doesn’t give much away, but this bar has a marzipan and red wine filling that strongly evokes Christmas for me. The red wine flavour is strong, but balanced well with the marzipan so neither gets lost. I suspect such a strongly flavoured chocolate might be polarising, but I love it.
Fröhliche Weihnachten (Spiced Marzipan on Cinnamon Praline)Another marzipan filling, this time with a hint of cinnamon spice and a subtly crunchy praline. The flavour is much less intense than the previous bar, making it very easy to eat the whole bar in 2 minutes flat. Ask me how I know.
Aus der Weihnachtswerkstatt (From The Christmas Workshop)French white nougat with pistachios and hazelnuts in 60% dark milk chocolate. Who doesn’t love a good nougat? This one is a soft, whipped nougat with plenty of flavour and crunch from the nuts. There’s a lovely subtle honey flavour underlying the nuttiness and the whole thing works exceptionally well with the rich dark milk chocolate coating.

A blend of butter caramel and praline with small crunchy caramel crisps in 50% milk chocolate. The filling for this one looks like the mousse-style fillings of the other bars, but it has a strong buttery caramel flavour. There’s a hint of nuttiness in the flavour and a nice little crunch to the texture. Again very well matched flavours, although this one is just a little too sweet for my own tastes. Of course, I still ate the entire bar in no time at all.
Glücksbringer (Lucky Charm)A sweet 40% milk chocolate mousse with 60% dark milk chocolate coating. Very simple flavours here, but they work so well. The best part of this bar though is the texture. The soft creamy mousse filling is reminiscent of a Milky Way bar, but obviously done much, much better. The chocolate shell is thick enough to give a decent crunch when you bite into it before the mousse melts in the mouth. Perfect execution.
Overall, I’m very happy with my choices here, but the truth is that Zotter’s selection is so big that they have something to suit every taste and mood. Whether it’s as a gift to someone you love, or a treat for yourself you can’t really go wrong. When I ordered, international shipping was free for orders over 35 Euros and everything arrived in perfect condition in less than a week.
Zotter Chocolate Christmas Photo Gallery












 Information
Information
- Buy it online from:
- Contains dark chocolate, milk chocolate, other types, white chocolate (50, 60% cocoa solids).
- Filed under austria, christmas, zotter.
The post Zotter Chocolate Christmas 2020 Selection appeared first on Chocablog.
I’ve long held the suspicion that the use of ‘encouragement’ in relation to cycling is a classic example of a weasel word. It’s a word that sounds positive (after all, who could possibly object to cycling being encouraged?) – but that, when it comes to its use in practice, amounts to an abdication of responsibility. ‘Encouragement’ involves persuading people to do something, and… that’s about it. We want you to cycle, but we’re going to do very little to help you. In fact, we might even ‘encourage’ you to cycle while we are actively making things worse.
‘Encouraging people to cycle’ has become the stock phrase of councils and authorities that want to sound like they’re in favour of cycling, but don’t want to actually enable it. Councils who might like the idea of more people spontaneously choosing to cycle on their roads, but aren’t at all keen on having to do anything to all to help them to do so – hard, uncomfortable political decisions like reallocating road space away from motor traffic, or filtering residential streets to make them safe enough to cycle on.
So it’s not at all surprising that two prominent Conservative politicians who have been campaigning to remove an objectively successful protected cycle lane on Kensington High Street are, of course, in favour of ‘encouragement’.

At first glance, you might think that politicians who were genuinely ‘strongly in favour of encouraging active travel’ wouldn’t be writing letters urging a council to remove a protected cycle lane that has seen a near three-fold increase in cycling levels, and that greatly reduces crash risk on a road with an appalling collision record. You certainly wouldn’t expect them to be stating how strongly in favour of encouraging active travel they are, in the very same letter calling for the removal of that protected cycle lane – which it should be stressed is (while it lasts) the only one in the entire borough. How can that possibly make sense?
Of course, there is no contradiction here. ‘Encouragement’ sounds nice, but when politicians say they are ‘strongly in favour of encouraging active travel’, it’s quite clear that the phrase doesn’t commit them to do anything at all that will actually make a difference. They say ‘strongly in favour of encouraging active travel’, but what they actually mean is ‘strongly in favour of persuading you to cycle, but without doing anything to help you.’
In much the same way, politicians can say they are ‘strongly in favour of encouraging children to eat healthily’, while voting against free school meals. With a moment’s scrutiny, ‘encouragement’ quickly becomes meaningless.
As if to remove any doubt about how keen they are on ‘encouraging’ cycling, here are the same two politicians celebrating the decision to remove the lane, while simultaneously urging the council to find ‘other ways encourage cycling’.
Thank you to @RBKC & @jthalassites for listening to residents & residents associations & acting to remove a cycle lane that wasn't working for most local people & businesses. @FelicityBuchan is right to urge the Council to find other ways to encourage cycling & active walking. pic.twitter.com/3j4v012NVI
— Tony Devenish (@Tony_Devenish) November 30, 2020
Naturally, these ‘other ways to encourage cycling’ aren’t spelt out. And why would they be? That’s not the job of an encourager. The limit of their ambition is to be in favour of you cycling if that’s something that you want to do, and to attempt to persuade you to do it if you don’t want to. Cycling is your choice.
That’s what ‘encouragement’ amounts to. It means nothing, and that’s why it gets used so often in relation to cycling. You’re on your own.

It’s been a while since I’ve done a full-on chocolate review, but when Kate and Janet from The Mallow Tailor got in touch and asked if I’d like to try some of their filled chocolates, I couldn’t say no. After all, it’s 2020 and I deserve a little more quality chocolate in my life.
As is often the case, it turns out that saying yes to chocolate was a good decision on my part.

Based in the Brecon Beacons area of South Wales, The Mallow Tailor specialise in beautiful chocolates filled marshmallow, caramel and fruit ganaches. And as you can see, first impressions are very good!
Filled Chocolates
I decided to cut into one of the chocolates to get a better look and was rewarded with this glorious sight.
This is the Salted Caramel in a dark chocolate shell and as you can see from the photos, it has the perfect consistency. The filling is smooth, sweet and perfectly gooey. It’s the kind of chocolate you need to be a little careful with. Bite into it without thinking, and and you’re going to end up with caramel all over your clothes.
Luckily, I’m an expert caramel consumer with many years experience and hardly made any mess. Much.

The chocolate has a strong resemblance to Paul A Young‘s famous salted caramel, both in appearance and flavour. That’s no bad thing, of course. The one thing that sets Paul’s chocolates apart though, is his choice of chocolate that perfectly complements the fillings. This Mallow Tailor can’t quite match that, and the dark chocolate shells do have a noticeable cocoa flavour
Next up was a raspberry ganache in white chocolate. Again, the filling was wonderfully smooth with a subtle but well balanced flavour. I particularly liked the balance of sweetness in this one; something that’s quite difficult to get right in a white chocolate.

The Lime Ganache in a dark chocolate shell is another well balanced chocolate. The lime is zesty and zingy, but doesn’t overpower the chocolate. This is the flavour that worked best for me with the Belgian dark chocolate that The Mallow Tailor are using.

I could tell the box wasn’t going to last long, so decided to plough on with my scientific endeavours and stuff my face some more. The Marshmallow in a milk chocolate shell was surprisingly good. I wasn’t expecting much from a mallow filled chocolate, but I can see why this is their signature creation. The filling had a nice soft texture and a very pleasant vanilla flavour that worked well with the choice of chocolate.
Finally I tried the Caramallow; a combination of salted caramel and marshmallow. I was at first expecting this to be some kind of mixture of the two fillings; a foamy caramel of some sort. Instead, we have two distinct layers in a dark chocolate shell. It’s a pretty good combination, although I think personally I do prefer the flavours separately.
Stollen Slab
Also included in my little care package was this interesting little bar. Kate calls it a “deconstructed stollen” covered in milk chocolate. I’m told that it’s made with raisins, cranberries and fresh nutmeg which are steeped in Barti rum and combined with big chunks of marzipan. And I love it. I do have a bit of a thing for marzipan in chocolate, and that’s what has had me nibbling on this bar throughout the day.
I’m so pleased to have discovered The Mallow Tailor, particularly at a time when we could all use a bit of a chocolate pick-me-up. At the start of another lockdown in the UK, we should all be thinking about supporting small local businesses, but it’s also a great time to show the ones we love that we’re thinking of them. And what better way than with the gift of chocolate.
Information- Buy it online from:
- Contains dark chocolate, milk chocolate, white chocolate.
- Filed under caramel, lime, marshmallow, marzipan, raspberry, salted caramel, stollen, the mallow tailor, uk.
The post The Mallow Tailor Chocolates appeared first on Chocablog.

AVAILABLE NOWA large format map that comes in a bespoke folder, with a Scarfolk visa and souvenir postcard. A limited-edition (1st 1000 orders only), web-exclusive version also includes a Scarfolk bookmark made of genuine imitation leather. (Available from Herb Lester Assoc., Waterstones, Foyles, Blackwells, Book Depository)
It was entirely predictable that the recent review of the Highway Code, which includes a rephrasing of the advice on ‘two abreast’ cycling, would provide fruitful material for lazy opinion columnists and shock jocks, respectively filling newspaper pages and the air waves with confected outrage and re-heated clichés about selfishness, self-righteousness, and whining about how frustrating it is to be stuck behind a bunch of lycra-clad, testosterone-fuelled Bradley Wiggins wannabees riding five abreast, for twenty miles down winding country lanes, with a hundred cars queuing behind… (yes, yes, we get the idea).
What I find remarkable about these discussions is the brazenness with which an intrinsically selfish demand – that other people should travel in single file, unable to easily talk to each other, look at one another, and engage in a natural human way, purely for the convenience of someone driving a far larger (and typically empty) vehicle – is presented as being entirely reasonable.
To see how odd this is, we only need to reframe this demand from one being made by motorists of cyclists, to one being made by cyclists of pedestrians.
How reasonable would it be for me to demand that people walking on shared use paths should do so in single file, the person behind staring fixedly at the back of their companion, purely for my convenience and to avoid any delay to my journey as I pedal along? And not just that, how would it sound if I described pedestrians walking side-by-side (or even, gasp, three or four abreast!) as selfish, thoughtlessly causing frustration to cyclists? I’m sure you would agree that it would sound deeply entitled, and frankly ridiculous. But this is precisely the logic of those motorists who routinely make exactly this kind of demand.
It’s not hard to imagine other ‘reasonable’ demands by motorists that suddenly become deeply unreasonable, once those demands are being made by people cycling. One occurred to me by chance last week.
Behind the local Sainsbury’s, there’s a shared use path that runs into the town centre. It’s not a particularly good path, but it’s an important connection for people that know about it, and thankfully it has street lighting, which is necessary for several reasons, not least among them being that it doesn’t feel particularly socially safe without it. (The rear of the supermarket is a large, oppressive brick wall, and the path isn’t overlooked).
The evenings have drawn in quickly, and after a long hot summer I am now using this path in the dark. Last week, one of the street lamps wasn’t working, and this meant I had to cycle through a patch of darkness. And it just so happened that on this particular evening, concealed within that patch of darkness, there were two pedestrians lurking (or more accurately, just walking home, minding their own business).
Because the path isn’t busy at the best of times, I have to admit that I was complacent when I was cycling along, and simply wasn’t expecting anyone to be there in the darkness. However, I wasn’t so complacent that I was going to cycle into anyone, or anything (I have a pretty good reason not to cycle into people or things – namely that I would get hurt myself), and as soon as my headlight beam illuminated them, I was able to respond, easing off and steering around them, without any alarm, bar a mild bit of surprise that there were people there that I hadn’t anticipated.
For the briefest of moments, a thought – a selfish thought – flashed through my head that these people could have made themselves more easy for me to see. Perhaps some brighter coloured clothing, or some reflectives, or even a torch. It was pitch black, and they did seem to be wearing dark clothing.
But of course – just as with a demand that people should walk around in single file so I am not held up while cycling – that would be a ridiculous expectation. They were just walking in the town centre, on a path away from any roads, and it simply shouldn’t be necessary to change the clothing they are wearing, or add hi-viz or lights, merely so that idiots on bikes don’t crash into them on a shared path.
For the minutes remaining on the rest of my journey, I pondered the absurdity of writing a letter to the local paper asking, “as a cyclist”, for thoughtless pedestrians to “make themselves seen!” on shared use paths. I could even throw in an anecdote about how so many pedestrians have the temerity to be “invisible”, about how I’m always nearly having an accident because of them, and add in some language about how “irresponsible” it is of people to just walk around in ordinary clothes without making any effort to prevent cyclists from riding into them in the dark.

Such a letter would undoubtedly provoke a strong reaction. A cyclist, a self-righteous cyclist no less, demanding that ordinary citizens make accommodations for his dangerous behaviour! But again, this is the kind of letter that motorists write all the time, without even any apparent reflection on the selfishness of this kind of demand. Their expectation is that the people they are putting at risk should “make themselves seen”, and that to do otherwise is irresponsible.
Indeed, this goes beyond mere letter writing – the whole philosophy of people walking and cycling “making themselves seen” is embedded in mainstream road safety, reflected (excuse the pun) in the kind of advice that local authorities and police forces pump out at this time of year.
As the nights start to draw in, here are some tips for a safe evening journey from @SussexSRP:
Wear bright or reflective clothing when dark
When crossing, never assume you have been seen
If cycling, make sure you have working front and back lights#BeBrightBeSeen— Horsham District Council (@HorshamDC) October 24, 2020
Now the clocks have gone back the evenings are getting darker a lot earlier. I'm amazed at the number of cyclists around who are all but invisible!! Lights are a legal requirement and bright clothing & a helmet are a very good idea for your survival… #BeSeen pic.twitter.com/gJJ6AfUGWc
— Sgt Olly Tayler (@DC_PoliceBiker) October 27, 2020
By analogy, I wonder how far I would get suggesting that “invisible” pedestrians should consider luminous yellow jackets “a very good idea for their survival” when being menaced by people cycling who aren’t bothering to ride to the conditions.
An even more extreme example would be me arguing that people walking should wear helmets to protect their heads, in the event that I crash into them when cycling. I could even garnish that demand with a suggestion that helmetless pedestrians are actually being irresponsible for not protecting their brains, or even some guilt-mongering about how a cyclist would feel if a pedestrian they hit died because they weren’t wearing a helmet.
Sounds selfish, if not callous, right? Welcome to the world of motoring, where advising people to wear safety equipment to “protect themselves” from the consequences of bad driving is… extremely normal.

Cartoon by Beztweets
One final form of this double standard (there will undoubtedly be many others). Take the ubiquitous demand that cyclists should always use “the perfectly good cycle path”, rather than sharing (or more accurately attempting to share) with motor traffic on the road. Let’s skip over the fact that no-one in their right mind would choose to “share” with sociopathic motorists if this cycle path was indeed “perfectly good”, and again consider what a pedestrian-cyclist form of this argument would take.
Imagine a road with a shared use footway on one side of it, and a pedestrian-only footway on the other, and then imagine me, a cyclist, demanding that pedestrians walk on the “perfectly good” footpath on the other side of the road, rather than walking on the shared use footway that I regularly cycle on, getting in my way, and holding me up. Again, I could garnish this with some suggestions about how it would be “so much safer” for them to use the pedestrian only footway, and that I can’t understand why they would put themselves at risk on the shared use side, when there is a safer option on the other side of the road. Yes, it might be more inconvenient for you as a pedestrian, but don’t you care about your safety? Don’t you worry about me cycling into you?
I've been thinking about this tweet a lot. Imagine how silly it would sound to suggest that people shouldn't walk in cycle-ped shared space areas, and that they should have to use the pedestrian-only pavements that are "just for them"
--- Lady at bus stop, a few months ago.
You might think it bad taste to talk about vaping in the middle of a pandemic, and you'd be right. But this hasn't stopped a slew of public health bodies, politicians, and activists from doing just that, so I see no reason to unilaterally disarm.
I've been meaning to blog about vaping for a while. My Twitter feed sometimes seems to be about little else, rather to my embarrassment whenever I scroll through it. So I'll start by explaining why it matters to me. As with many vapers, my story begins with smoking.
To cut that long story short: I smoked, first a pipe then cigarettes, from my early twenties to my late fifties. I tried to quit many times. The annual ratchet of tax rises in the Budget reliably brought on another attempt. Surely I'll stop, I told myself, when they're over 50p a pack! Not even the £10 pack did the trick. Neither did Allen Carr's book, willpower, shame, and the pub smoking ban. One day about ten years ago I saw an electronic cigarette in a petrol station, and bought it. It was shaped like a cigarette and had a tip that glowed when you drew on it. After buying a few of these and finding it inconvenient when they ran down I soon was ordering the same brand with rechargeable batteries and replaceable cartridges. I was still smoking cigarettes, but a bit less than before, and the ecig made pub conversations much more convivial and less often interrupted than they'd become. The kick was feeble, the nicotine faint, the taste indifferent, but it was better than nothing.
Then a student in a mid-morning break at Napier showed me a more advanced e-cig, with a refillable tank, and told me where to get them. That very lunchtime I hastened over the hill to Emporium Vapour at Gorgie Road, and bought a starter kit. Within weeks, and without trying, I'd gone from smoking a pack of cigarettes a day to a pack a month. I went from tobacco flavours to fruit, menthol, spearmint... eventually settling on Kiwi and Strawberry, a half dozen tiny bottles of which I've just ordered. I smoked what turned out to be my last cigarette in the early hours of New Year's Day, 2016. Vaping had succeeded where decades of New Year resolutions had failed.
In the meantime, I'd been through the battle over the EU's Tobacco Products Directive, which saw concerted efforts to ban or severely restrict vaping and frantic, largely self-funded efforts by vapers to save it. We all learned a lesson in how EU laws are made. The vaunted principles of transparency, evidence, proportionality and subsidiarity didn't, let's say, stand out. The outcome was some pointless, petty and harmful regulation that wasn't as bad as we'd feared - and thousands more people in Britain who hated the EU and were active, informed and outspoken about it on social media. I'm not saying it swung the referendum, but it can't have helped.
The real threat to vaping, however, came from the United States. As long as vaping was a hipster fad, it could be fought by ridicule and junk science, of which there was plenty. The typical experiment involved burning out ecig coils and forcing mice to breathe the resulting toxic smoke for a month. The results of the mouse autopsies could then be turned into excited press releases and even more excitable headlines.
Another line of attack was that the vaping industry - or, absurdly, the tobacco industry - was 'targeting kids'. In US usage, 'kids' can mean anything from toddlers to graduates, but let's be generous and assume it meant in this case teenagers. The massed ranks of mom and pop businesses and evangelical ex-smoker start-ups that made up Big Vape in those days were allegedly targeting teenagers with 'kid-friendly' flavours: sweet and fruit flavours, sometimes with names reminiscent of the kind of candies actual kids like. 'Gummy bears' was a common talking point. The slogan, repeated to this day, was 'Flavours hook kids'. The claim makes sense until you give it a moment's thought.
When you do give it a moment's thought, you recall that teenagers are anxious to put away childish things, to take on the trappings of adulthood as quickly they can, and to defy the conventions and pieties of the adult world as annoyingly as they can. This is, of course, one reason why they smoke cigarettes. If you wanted to appeal to teenagers, your ideal vape flavour branding would be redolent of tobacco harvested by slaves, shipped by pirates, imported by smugglers and smoked by highwaymen.
The real 'target' (i.e. market) for fruit and sweet flavoured vapes was people like me: adult smokers and ex-smokers and would-be ex-smokers. Smokers who take up vaping usually start with imitations of their familiar tobacco flavours, but fairly soon (perhaps because the imitations are not all that convincing - copying tobacco flavour has turned out to be surprisingly difficult) move on to sweet and fruit flavours. If these flavours are presented as having the generic tastes of sweets they enjoyed in childhood (and may not have tasted since, for the sake of their teeth or their waistlines) all the better -- it adds a touch of harmless nostalgia.
And that market - unlike the pocket-money, illegal market of high-school students - is huge. But open-tank vaping doesn't appeal to all of them. If only there was a product as convenient as cigarettes! A start-up company set out to design just that, and succeeded. Juul is a slim device with a USB-cable rechargeable battery and replaceable cartridges of liquid. It gives the same instant nicotine kick as a cigarette. So I'm told - thanks the above-mentioned petty EU regulations, the high-nicotine pods aren't available here.
The trouble with Juul was that these devices really did appeal to teenagers, mainly if not wholly the very teenagers who would otherwise have been (or indeed already were) smoking cigarettes. Juul and similar devices are easy to conceal, almost undetectable in discreet use, and leave no tell-tale smell. This duly set off a moral panic - at the same time as the prevalence of actual cigarette smoking among teenagers dropped to a historic low. The 'Flavours hook kids' nonsense has driven ban after ban on flavoured vaping liquids. This was (and is) bad enough.
Then came disaster.
Cannabis use is illegal in the US at a federal level, but in the past decade some states have legalised it: first for medicinal use, then recreationally. The possibility of vaping cannabis didn't escape attention, and was soon realised. Legal weed stores sell an eye-watering variety of vape pens and cartridges, as well as cannabis cakes, candies and for all I know actual leaf. Because it's legal in some places but not in others an illegal market soon sprang up. Some of the criminal entrepreneurs supplying it found that they could cut cannabis-based oils with thickening agents, one of them Vitamin E acetate. This turned out to be deadly. More and more people were rushed to hospital, and scores have died, with severe lung injuries. The source of the problem was soon exposed by the legal cannabis industry. It was obscured at first because the victims had often been vaping cannabis illegally (because of their age or location) and admitted only to 'vaping' or even, more alarmingly, to 'juuling'. Blood tests, however, soon showed what they'd been vaping. It wasn't nicotine.
The lie ran around the world before the truth got its boots on. Certain US public health authorities, notably the Centers for Disease Control, did their utmost to warn against 'vaping' and 'e-cigarette use' in general and almost nothing to warn against vaping illegal cannabis in particular. The misconception, to put it no more strongly, persists and is reinforced by various public health authorities, lazy journalists, and anti-vaping activists to this day.
That's why the little old lady at the bus stop kindly advised me to go back to smoking.
I’m supposed to be writing about the upcoming election right? Because my job as an American citizen at this pivotal moment in our nation’s history is to help spread all the psychological warfare tactics being deployed by all sides to get us to be afraid and either vote or not.
Screw that. By the way: Vote! That’s all I’m going to say right now. It’s not that I’m not busy with local politics (hence the silence on this blog). Rather, it’s that I suspect that your adrenal glands are getting worn out by the psywar, so I wanted to give you a little respite. Over the last month, I’ve read two very different visions of space for the 21st Century, and I wanted to share them.
One is the US Space Force’s “Capstone Publication”: Doctrine for Space Forces. It’s an interesting mix of apparently thoughtful “how do we fight a war in space” analysis (which happens to be useful for SFF types at least), combined with a certain amount of macho posturing and “boots in the sky rhetoric,” to make it look like they’re more than a bunch of satellite jockeys working from home and keeping their cats off their laptops. Which I’m sure they are. This is good stuff to read if you’re interested in the putative realities of warfighting in near-Earth orbit and how it fits together with all the other various and diverse ways we have of hurting each other. But much of it is perhaps too familiar for precisely those reasons.
On the other side is something (apparently) completely different: JP Aerospace, aka “America’s Other Space Program,” a little outfit in the Sacramento area that seems to be developing its space hardware as a non-profit running on donations and contracts. The JP is John Powell, and I’m a bit late to his game. For the last 20 years or more, he’s been promoting what he calls “The Airship to Orbit Program” (you can buy his 2008 book at his website. Or Amazon–it comes out of the same warehouse. It’s worth reading, not just for the program, but if you want to learn about all the upper layers of our atmosphere). His vision of how to get to orbit is a slower, safer, three-step operation using ginormous airships.
Stage one is an A-shaped “Ascender” that’s around 900 feet long. The arms of the A are helium or hydrogen-filled polypropylene balloons inside a wing-shaped nylon sleeve, while the crossbar of the A has a couple of electric-powered high altitude propellers. It’s a semi-blimp with a keel that’s a large carbon fiber space frame truss, while the top of the wing-bag is a carbon fiber deck that mounts thin solar panels and carries the pipes and pumps for moving the lifting gas between internal gas bags. Semi-blimp means its halfway between a blimp (which has no hard internal structure other than the nose cone and possibly fins) and a dirigible, which has a full internal structure. Or you could call it a keeled airship. This beast can carry about 20 people up to 140,000 feet in about two hours. Basically, the Ascender takes off, points its nose up 70 degrees (it’s basically a huge, slow flying wing) and ascends to 60,000 feet on buoyancy alone. At that point, the wings and propellers take over so that it can fly the rest of the way up. It has to be so huge and light to fly at high altitude in very thin air.
At 140,000 feet (space officially starts around 330,000 feet up), the Ascender docks with Stage 2: Dark Sky Station. This is a starfish shaped, rigid-keeled airship/station. Each arm of the star is around 2 miles long, and it can house 100-200 people indefinitely with resupply. Its gasbags are inflated with hydrogen, but there’s so little oxygen at this elevation that combustion is not an issue. The Dark Sky Station (dark because the sky is black at this elevation) is a combination tourist attraction, transshipment hub, and research center. People visit to see the sights, drop a paper airplane, catch Stage 3 to orbit, or go up there to do astronomy, aerobiology, or unload cargo that needs to go to orbit whatever. It’s a commercial venture.
Stage 3, the Orbital Airship, is assembled at the Dark Sky Station and flies to orbit. This is another A-shaped, keeled airship, except each wing is around 6000 feet long and there’s no cross-bar. It has electrical propulsion units (design TBA, but anything from VASIMR to advanced ion is possible), and it’s so large because it has to fly in *really* thin air. It climbs to 270,00 feet on a mixture of buoyancy and wing lift. Above that, level, it flies using its wings for lift, gradually picking up speed (over most of a day or 5) at the top of the atmosphere until it achieves orbital speed at 17,500 mph and is flying on propulsion alone. At that point, its job is to either rendezvous with a spacecraft or space station or possibly release satellites. To get back down to the Dark Sky Station, the orbital airship merely tips its nose up, and its enormous surface area acts as a really nice, gradual aerobrake without heating too hot. It drops and slows until it can match velocity with the DSS and do it again. This ship is not designed to ever land. To fly at that altitude, the gas bags are about the consistency of vegetable bags at the grocery store, and the nylon skin is not much thicker. It would break apart in the lower atmosphere, but it can get lift out of what would have been a decent vacuum at sea level in the 19th century. It’s also so big and ponderous that even a simple turn would take something like an hour to execute. This flies like an oil tanker, not a jet fighter.
Now about the practicalities: JP has flown over 100 development missions consisting of balloon rigs and sounding rockets, and built Ascenders up to 160 feet long for the USAF, so he’s not blowing smoke. He’s designed high altitude propellers and demonstrated that they work on rigs launched up to 100,000 feet. He’s flown a number of small dark-sky stations (10-30′ wide) and demonstrated that the five-armed starfish is the most stable design. He’s recycling a lot of the same designs and technology for all three designs, and he’s testing them out as he gets funds to fly missions with his crew of merry space pioneers. One of his basic workhorse designs, the two-balloon, two propeller “tandem” design was developed and flown for around $30,000. While he ran his company on government contracts prior to the 2008 crash, he’s currently running the whole thing as a non-profit. He’ll haul your stuff up into the upper atmosphere for quite affordable rates (or free if it fits in a ping-pong ball), and he does several launches a year, testing his technology a piece at a time and flying other people’s stuff to pay the way.
A couple of other design challenges: how can balloons fly at Mach 22 (escape velocity), and what happens when something hits an airship?
Balloons flown by the NASA and the USAF have already gone Mach 10 in the high atmosphere/near Earth orbit, so it’s not impossible. No one apparently knows if a balloon with mile-long wings can pull off the stunt, but our intuitions about friction and lift get weird in near-vacuum conditions.
The other common concern is “what if it gets a hole?” And the simple answer is this isn’t a problem. The gas is in multiple bags, not one . This is a normal dirigible design going back a century. The problem with having one gas bag per wing is that gas can slosh around, and once it gets to one end and the ship goes vertical, things get hairy. Blimps have multiple gas bags inside the outer envelope as do dirigibles. They also normally have air ballast bags inside them to keep the gas where it belongs (outside air performs the same function as water ballast in a submarine).
Anyway, getting back to safety, if a gas bag gets holed, it can be replaced in flight. They’ve been testing having large gas bags on reels and unreeling them as they get inflated. It works well enough. Another line is the WW I bombing of London by Zeppelins. It took some time to figure out how to shoot down the dirigibles. The problem wasn’t hitting them with bullets, it was that the bullets simply passed through, rather than igniting the hydrogen inside. The holes leaked slowly enough that the airships didn’t go down, and sometimes the bags could simply be patched in flight. The Zeppelins weren’t shot down until the British figured out special incendiary bullet pairs to pierce the bags and physically ignite them from the inside. Then, once they got the right fuel-air mixture from the holed bags, the hydrogen finally ignited and brought down the Zeppelin.
In the case of a meteor hitting an orbital airship at Mach whatever, the space debris passes right through, and the crew patches up the hole. The ship’s shape is inflated by nitrogen (at very low pressure, I suspect), so it’s a matter of patching holes and replacing stuff. The carbon fiber truss is probably also fairly easy to replace, and it looks like the ships will have multiple trusses per keel. According to his book (and the enclosed pictures), a 100 feet of the truss he uses as airship keels weighs around 20 lbs. Having multiple trusses and carrying spares on the ship isn’t that hard. Patching it in a freezing vacuum gets interesting, but that’s not the same as the shuttle breaking up over Texas.
So that’s two visions of space overall. On one side, we have a very colonialist take of shredding treaties and militarizing space before the other side does it to us. Which sounds depressingly familiar, but I’m a well enough trained nationalist to feel a faint patriotic stirring at the thought of boots in the sky. On the other side, we’ve got this scrappy little outfit with a really different take on how to get to orbit, that’s shoestringing successes at a tiny fraction of what the rocketeers are charging to light candles and launch stuff. They may be dreamers, kind of goofy, and definitely not suits, but they’re getting stuff done for cheap, which is more than we can say for most aerospace companies.
These worlds aren’t mutually exclusive: JP Aeronautics did build its early Ascenders under contract to the Air Force. In the book Powell says that the biggest Ascender he built for the USAF was destroyed because the officer in charge ordered them to fly the airship in a high wind (which the prototype wasn’t designed to handle at that early stage). The resulting fiasco destroyed the airship, after which the USAF cancelled the contract and JP figured out how to launch balloons in high winds regardless. However, in an interview, Powell says that some of his work was given to the military and ended up in places he doesn’t know about. So it’s possible that the USAF (or even the Space Force) is flying ultra-high altitude airships based on JP Aeronautics designs. They may even be manned observation platforms. After all, even the Stage One Ascender is designed to operate at 140,000 feet, while the SR-71 allegedly has a ceiling of 85,000 feet and the U2 operates below 70,000 feet. Yes, these airships are slow. However, they don’t have a lot of metal in them or much that can burn, so it’s not clear to me how you track or even shoot one down. If a missile puts a hole in an airship that’s 900 feet long, unless it shatters all the keel, it probably can just be patched in flight.
But I think the vision of JP Aeronautics is a bit closer to sustainable than the jet, rocket, and missile crew are. While the airships would need square miles of plastic sheeting, they’re low-energy and electric-powered. In the worst case scenario, they can be inflated with hydrogen too. Figure out a way to make them out of sustainable materials and they can still fly. It’s a lot harder to do that with a metal and ceramic rocket.
Couple these airships with Brian McConnell and Alex Tolley’s spacecoach, and you’ve got the rudiments of a sustainable solarpunk space transportation system. And perhaps that’s an alternative vision you can play with for a bit, before descending back into the high stress memescape the politicos want our day to day lives to be.

Regular readers will know I’m a big fan of Jennifer Earle’s Chocolate Ecstasy Tours; walking tours of some of London’s best chocolate shops and sweet treat establishments.
Unfortunately, the current pandemic has meant that these tours have had to go on hold, and Jen has had to look for other ways to keep the spirit of the tours going, while giving a much needed boost to some of the smaller chocolatiers and chocolate makers who have struggled during the lockdown period. To that end, she has come up with a couple of great ideas for finding great chocolate without ever leaving the comfort of your home.
First up, Jen has created a directory of online sellers, an extensive list of small producers in the UK who are selling sweet treats and baked goods online. It’s a great place to find a chocolate gift for a loved one or a pick-me-up for yourself!
More recently, she has introduced a new and exciting idea, the Online Mystery Chocolate Tasting, and she was kind enough to send me a tasting pack for the latest tasting.
When you sign up for an Online Mystery Chocolate Tasting, you’ll be sent one of these packs in the post and a link to join the Zoom videoconferencing event via email. One of the great things about the tastings is that anyone can join the Zoom event and watch along, but obviously you’re only going to get the full experience if you have the tasting pack.

On this occassion, Jen had invited master chocolatier Paul A Young along to talk about the chocolates as we tasted them. Although structured, the discussion was quite informal and conversational. Paul gave some insights on how he uses particular flavour profiles in his own work, and after tasting and discussing each piece of chocolate, Jen revealed what it was and gave plenty of background information about the maker.

In our case, all the producers were British bean-to-bar chocolate makers, but it’s important to note that there will be different chocolates – and types of chocolate – for each tasting event. Otherwise, of course, it wouldn’t be a mystery! If you are looking to find out more about the chocolates, or have specific dietary requirements, then you can drop Jen an email beforehand just to check the chocolates in your chosen session are suitable.

While the video chat was limited to Jen and Paul, the rest of us were able to make comments via the Zoom chat as well as give quick feedback via the “Thumbs Up” feature. This was a great way to involve everyone while avoiding any chaos that may have resulted from everyone being allowed to speak. There were over 70 people in the call, so this was probably for the best!
I really enjoyed the format of this online tasting, and thoroughly recommend it to anyone who loves chocolate. It’s a great little gift, or something to do as a couple on the sofa (the tasting packs contain enough chocolate for two) and you can engage as much or as little as you are comfortable with. I really appreciated the fact that anyone can come along and join in, and Jen has also made the video from this tasting available in full. You can watch it below.
At the time of writing, the next tasting event is August 12th 2020 with Bettina Campolucci Bardi of Bettina’s kitchen. Tasting packs cost £19.95 and you can purchase yours here.
Information- Filed under chocolate ecstasy tours, jennifer earle, paul a young.
The post Online Mystery Chocolate Tasting With Chocolate Ecstasy Tours appeared first on Chocablog.

It's been a while since I've looked at any mass market confectionery chocolate, but these new Galaxy Vegan chocolate bars really caught my eye when they were announced recently.
In theory, creating vegan chocolate is easy. All dark chocolate should be dairy free and therefore vegan. But if you want to replicate the sweetness and creaminess of a milk chocolate, it's a lot more difficult.
There are a few options that manufacturers can use to replace the milk in milk chocolate, but they all have drawbacks. A common one is rice flour, but if you'd ever tried a pure rice milk chocolate, you'll know it doesn't really taste much like milk chocolate. Rice lacks the creaminess or the fat content to give that satisfying milk chocolate flavour and mouthfeel.
Some manufacturers use oat or almond flours, but they have drawbacks of their own, not least of which is the fact that they add a distinct flavour to the chocolate.
One dairy alternative that we don't see very often is hazelnut paste. Of course, there are many chocolate products that contain hazelnuts, including everything from Nutella to high end gianduja, but it's rarely marketed as a vegan milk chocolate alternative.
For these new Galaxy Vegan bars, Mars has opted to use a combination of hazelnut and rice flour to replace the dairy. Hazelnuts have a high fat content, which is great for replicating the mouthfeel of milk chocolate, but they do also have a strong flavour. I suspect that's one of the reasons why rice has been used as well in the chocolate recipe. The hazelnut gives creaminess, but the rice helps to offset the flavour and give the chocolate "body". Hazelnut paste is a thick liquid at room temperature, so if too much were used, the chocolate would end up very soft.
So how well does it work in these bars?To my surprise, very well indeed.
There are three flavours in the range; Caramelised Hazelnut, Caramel & Sea Salt and Smooth Orange. There's no "unflavoured" option, likely because they're all going to taste of hazelnuts to some extent. They are smooth and creamy, and you might never guess they were dairy free if you hadn't been told.
I particularly liked the Smooth Orange, but other friends who sampled them preferred the Caramel & Sea Salt.
For a product that I'd class as a "supermarket chocolate", these are a great choice for vegans and non-vegans alike. You pay a little more than a standard Galaxy bar, but you're getting a large (100g) bar and a product with a very clean ingredients list. There's no palm oil or shea, and only natural flavourings and a little sunflower lecithin added.
I'm sure the increased price and the very fact that it says "Vegan" on the front will annoy some, but I'd be quite happy to eat any of these, which is more than I can say for most confectionery chocolate these days.
InformationThe post Galaxy Vegan Chocolate appeared first on Chocablog.

Until a few days ago, I didn’t realise how much I needed a hot chocolate shaker in my life. This little plastic cup from The Chocolate Society has changed the way I make hot chocolate for good.
What is a hot chocolate shaker? Put simply, it’s just a cup with a lid that allows you to make a perfectly smooth hot chocolate by shaking chocolate with hot milk or water. The simple act of shaking helps the drink form an emulsion much more effectively than stirring or whisking.

If you try to shake a hot drink in a normal jar or bottle however, you’re more than likely going to be faced with an explosion of hot liquid. The problem is that heat from the liquid causes the air in container to expand rapidly, effectively turning the whole thing into a hot chocolate bomb. It’s not something I recommend trying at home.
Al Garnsworthy at The Chocolate Society thought about this problem and came up with a fantastically elegant solution; an expanding rubber lid that pops up when the pressure inside the jar increases. It’s a simple idea, but it works incredibly well.


There’s also a few other design features that make this a must-have device for any hot chocolate lover. Most importantly is the way the lid firmly seals onto the jar. Let’s not forget you’re going to be shaking a container full of hot liquid, so it’s absolutely vital that lid stays firmly in place when shaking. I was a little nervous the first time I tried the shaker, but I needn’t have worried. As long as you’re careful to make sure the lid is nice and tight, the seal is good and strong.
After a couple of seconds shaking, the lid pops up. After about 10 seconds shaking, your hot chocolate is ready.

The other nice design touch is the jar is insulated with a double wall, meaning it stays cool to the touch at all times. It’s made from a very strong plastic and feels like it can take a lot of abuse and keep going for years. It’s dishwasher safe, but because there’s no nasty residue, it’s really easy to wash by hand too.

But the best thing about the Hot Chocolate Shaker is the quality of the drink it makes. With traditional hot chocolate making methods, I always find some residue at the bottom of the mug or pan I’m making it in, even after thorough whisking. Every time I’ve tried the shaker, I’ve produced a perfectly smooth drink with no residue at all. It actually tastes better because more of the chocolate is emulsified and less is left behind.
I know there are fancy hot chocolate making machines on the market at the moment, and I’ve not tried any of those. They may be wonderful and produce an even more satisfying experience, but I love the simplicity of my hot chocolate shaker. I can take it to work, heat some milk in the microwave and make myself a fast and delicious drink that’s as good as any I’ve had.
It’s currently on sale for under £20, which is great deal for such an effective kitchen gadget. If you love hot chocolate or know someone who does, do yourself a favour and pick one up.
My hot chocolate shaker was provided free of charge for review by The Chocolate Society.
Information- Buy it online from:
- Filed under chocolate society, hot chocolate, hot chocolate shaker.
The post Chocolate Society Hot Chocolate Shaker appeared first on Chocablog.

On 7 September, 1976, dozens of children, including every single pupil from class 3, Scarfolk High School, vanished on their way to school. A police operation was launched but no clues were ever found. The children were pronounced dead the following Monday, a mere three days later.
Every year thereafter, the police commissioned their sketch artist to draw, in the style of a school photograph, how the missing children might have looked (albeit with their faces removed) had they not disappeared in mysterious circumstances. This was sent to the bereaved parents of class 3 at an exorbitant cost of £31.25.
In the 1979 class sketch, one parent noticed a small label on one of the faceless figure's clothes that contained a code word only their child could have known.
Under mounting pressure from parents, the police eventually raided their artist's studio and found 347 children in his cellar where many had been held captive for several years. The police immediately seized and confined the children as evidence in a crime investigation, which, after much dithering, ultimately never went to court leaving the families no choice but to pursue a private prosecution against the kidnapper.
As the children had already been pronounced dead and the cost of amending the relevant paperwork was high, they were given away as prizes in the Scarfolk police raffle, which helped pay the legal fees of their sketch artist, who, it turns out, was the son of Scarfolk's police commissioner.
RESTful APIs are everywhere. This is funny, because how many people really know what "RESTful" is supposed to mean?
I think most of us can empathize with this Hacker News poster:
I've read several articles about REST, even a bit of the original paper. But I still have quite a vague idea about what it is. I'm beginning to think that nobody knows, that it's simply a very poorly defined concept.
I had planned to write a blog post exploring how REST came to be such a dominant paradigm for communication across the internet. I started my research by reading Roy Fielding's 2000 dissertation, which introduced REST to the world. After reading Fielding's dissertation, I realized that the much more interesting story here is how Fielding's ideas came to be so widely misunderstood.
Many more people know that Fielding's dissertation is where REST came from than have read the dissertation (fair enough), so misconceptions about what the dissertation actually contains are pervasive.
The biggest of these misconceptions is that the dissertation directly addresses the problem of building APIs. I had always assumed, as I imagine many people do, that REST was intended from the get-go as an architectural model for web APIs built on top of HTTP. I thought perhaps that there had been some chaotic experimental period where people were building APIs on top of HTTP all wrong, and then Fielding came along and presented REST as the sane way to do things. But the timeline doesn't make sense here: APIs for web services, in the sense that we know them today, weren't a thing until a few years after Fielding published his dissertation.
Fielding's dissertation (titled "Architectural Styles and the Design of Network-based Software Architectures") is not about how to build APIs on top of HTTP but rather about HTTP itself. Fielding contributed to the HTTP/1.0 specification and co-authored the HTTP/1.1 specification, which was published in 1999. He was interested in the architectural lessons that could be drawn from the design of the HTTP protocol; his dissertation presents REST as a distillation of the architectural principles that guided the standardization process for HTTP/1.1. Fielding used these principles to make decisions about which proposals to incorporate into HTTP/1.1. For example, he rejected a proposal to batch requests using new MGET and MHEAD methods because he felt the proposal violated the constraints prescribed by REST, especially the constraint that messages in a REST system should be easy to proxy and cache.1 So HTTP/1.1 was instead designed around persistent connections over which multiple HTTP requests can be sent. (Fielding also felt that cookies are not RESTful because they add state to what should be a stateless system, but their usage was already entrenched.2) REST, for Fielding, was not a guide to building HTTP-based systems but a guide to extending HTTP.
This isn't to say that Fielding doesn't think REST could be used to build other systems. It's just that he assumes these other systems will also be "distributed hypermedia systems." This is another misconception people have about REST: that it is a general architecture you can use for any kind of networked application. But you could sum up the part of the dissertation where Fielding introduces REST as, essentially, "Listen, we just designed HTTP, so if you also find yourself designing a distributed hypermedia system you should use this cool architecture we worked out called REST to make things easier." It's not obvious why Fielding thinks anyone would ever attempt to build such a thing given that the web already exists; perhaps in 2000 it seemed like there was room for more than one distributed hypermedia system in the world. Anyway, Fielding makes clear that REST is intended as a solution for the scalability and consistency problems that arise when trying to connect hypermedia across the internet, not as an architectural model for distributed applications in general.
We remember Fielding's dissertation now as the dissertation that introduced REST, but really the dissertation is about how much one-size-fits-all software architectures suck, and how you can better pick a software architecture appropriate for your needs. Only a single chapter of the dissertation is devoted to REST itself; much of the word count is spent on a taxonomy of alternative architectural styles3 that one could use for networked applications. Among these is the Pipe-and-Filter (PF) style, inspired by Unix pipes, along with various refinements of the Client-Server style (CS), such as Layered-Client-Server (LCS), Client-Cache-Stateless-Server (C$SS), and Layered-Client-Cache-Stateless-Server (LC$SS). The acronyms get unwieldy but Fielding's point is that you can mix and match constraints imposed by existing styles to derive new styles. REST gets derived this way and could instead have been called—but for obvious reasons was not—Uniform-Layered-Code-on-Demand-Client-Cache-Stateless-Server (ULCODC$SS). Fielding establishes this taxonomy to emphasize that different constraints are appropriate for different applications and that this last group of constraints were the ones he felt worked best for HTTP.
This is the deep, deep irony of REST's ubiquity today. REST gets blindly used for all sorts of networked applications now, but Fielding originally offered REST as an illustration of how to derive a software architecture tailored to an individual application's particular needs.
I struggle to understand how this happened, because Fielding is so explicit about the pitfalls of not letting form follow function. He warns, almost at the very beginning of the dissertation, that "design-by-buzzword is a common occurrence" brought on by a failure to properly appreciate software architecture.4 He picks up this theme again several pages later:
Some architectural styles are often portrayed as "silver bullet" solutions for all forms of software. However, a good designer should select a style that matches the needs of a particular problem being solved.5
REST itself is an especially poor "silver bullet" solution, because, as Fielding later points out, it incorporates trade-offs that may not be appropriate unless you are building a distributed hypermedia application:
REST is designed to be efficient for large-grain hypermedia data transfer, optimizing for the common case of the Web, but resulting in an interface that is not optimal for other forms of architectural interaction.6
Fielding came up with REST because the web posed a thorny problem of "anarchic scalability," by which Fielding means the need to connect documents in a performant way across organizational and national boundaries. The constraints that REST imposes were carefully chosen to solve this anarchic scalability problem. Web service APIs that are public-facing have to deal with a similar problem, so one can see why REST is relevant there. Yet today it would not be at all surprising to find that an engineering team has built a backend using REST even though the backend only talks to clients that the engineering team has full control over. We have all become the architect in this Monty Python sketch, who designs an apartment building in the style of a slaughterhouse because slaughterhouses are the only thing he has experience building. (Fielding uses a line from this sketch as an epigraph for his dissertation: "Excuse me… did you say 'knives'?")
So, given that Fielding's dissertation was all about avoiding silver bullet software architectures, how did REST become a de facto standard for web services of every kind?
My theory is that, in the mid-2000s, the people who were sick of SOAP and wanted to do something else needed their own four-letter acronym.
I'm only half-joking here. SOAP, or the Simple Object Access Protocol, is a verbose and complicated protocol that you cannot use without first understanding a bunch of interrelated XML specifications. Early web services offered APIs based on SOAP, but, as more and more APIs started being offered in the mid-2000s, software developers burned by SOAP's complexity migrated away en masse.
Among this crowd, SOAP inspired contempt. Ruby-on-Rails dropped SOAP support in 2007, leading to this emblematic comment from Rails creator David Heinemeier Hansson: "We feel that SOAP is overly complicated. It's been taken over by the enterprise people, and when that happens, usually nothing good comes of it."7 The "enterprise people" wanted everything to be formally specified, but the get-shit-done crowd saw that as a waste of time.
If the get-shit-done crowd wasn't going to use SOAP, they still needed some standard way of doing things. Since everyone was using HTTP, and since everyone would keep using HTTP at least as a transport layer because of all the proxying and caching support, the simplest possible thing to do was just rely on HTTP's existing semantics. So that's what they did. They could have called their approach Fuck It, Overload HTTP (FIOH), and that would have been an accurate name, as anyone who has ever tried to decide what HTTP status code to return for a business logic error can attest. But that would have seemed recklessly blasé next to all the formal specification work that went into SOAP.
Luckily, there was this dissertation out there, written by a co-author of the HTTP/1.1 specification, that had something vaguely to do with extending HTTP and could offer FIOH a veneer of academic respectability. So REST was appropriated to give cover for what was really just FIOH.
I'm not saying that this is exactly how things happened, or that there was an actual conspiracy among irreverent startup types to misappropriate REST, but this story helps me understand how REST became a model for web service APIs when Fielding's dissertation isn't about web service APIs at all. Adopting REST's constraints makes some sense, especially for public-facing APIs that do cross organizational boundaries and thus benefit from REST's "uniform interface." That link must have been the kernel of why REST first got mentioned in connection with building APIs on the web. But imagining a separate approach called "FIOH," that borrowed the "REST" name partly just for marketing reasons, helps me account for the many disparities between what today we know as RESTful APIs and the REST architectural style that Fielding originally described.
REST purists often complain, for example, that so-called REST APIs aren't actually REST APIs because they do not use Hypermedia as The Engine of Application State (HATEOAS). Fielding himself has made this criticism. According to him, a real REST API is supposed to allow you to navigate all its endpoints from a base endpoint by following links. If you think that people are actually out there trying to build REST APIs, then this is a glaring omission—HATEOAS really is fundamental to Fielding's original conception of REST, especially considering that the "state transfer" in "Representational State Transfer" refers to navigating a state machine using hyperlinks between resources (and not, as many people seem to believe, to transferring resource state over the wire).8 But if you imagine that everyone is just building FIOH APIs and advertising them, with a nudge and a wink, as REST APIs, or slightly more honestly as "RESTful" APIs, then of course HATEOAS is unimportant.
Similarly, you might be surprised to know that there is nothing in Fielding's dissertation about which HTTP verb should map to which CRUD action, even though software developers like to argue endlessly about whether using PUT or PATCH to update a resource is more RESTful. Having a standard mapping of HTTP verbs to CRUD actions is a useful thing, but this standard mapping is part of FIOH and not part of REST.
This is why, rather than saying that nobody understands REST, we should just think of the term "REST" as having been misappropriated. The modern notion of a REST API has historical links to Fielding's REST architecture, but really the two things are separate. The historical link is good to keep in mind as a guide for when to build a RESTful API. Does your API cross organizational and national boundaries the same way that HTTP needs to? Then building a RESTful API with a predictable, uniform interface might be the right approach. If not, it's good to remember that Fielding favored having form follow function. Maybe something like GraphQL or even just JSON-RPC would be a better fit for what you are trying to accomplish.
If you enjoyed this post, more like it come out every four weeks! Follow @TwoBitHistory on Twitter or subscribe to the RSS feed to make sure you know when a new post is out.
Previously on TwoBitHistory…
New post is up! I wrote about how to solve differential equations using an analog computer from the '30s mostly made out of gears. As a bonus there's even some stuff in here about how to aim very large artillery pieces.https://t.co/fwswXymgZa
— TwoBitHistory (@TwoBitHistory) April 6, 2020
-
Roy Fielding. "Architectural Styles and the Design of Network-based Software Architectures," 128. 2000. University of California, Irvine, PhD Dissertation, accessed June 28, 2020, https://www.sciencedirect.com/science/article/pii/S0315086011000279. ↩
-
Fielding, 130. ↩
-
Fielding distinguishes between software architectures and software architecture "styles." REST is an architectural style that has an instantiation in the architecture of HTTP. ↩
-
Fielding, 2. ↩
-
Fielding, 15. ↩
-
Fielding, 82. ↩
-
Paul Krill. "Ruby on Rails 2.0 released for Web Apps," InfoWorld. Dec 7, 2007, accessed June 28, 2020, https://www.infoworld.com/article/2648925/ruby-on-rails-2-0-released-for-web-apps.html ↩
-
Fielding, 109. ↩
The pubs will reopen in a few days. Every day this week we will post a 1970s beer mat from the Scarfolk council archives. Collect them all!

When neither druid nor doctor could reverse the process, the victim became a town mascot, offering rides to children. Records show, however, that he was also secretly employed by the state to violently intimidate seditious citizens and prying outsiders. He was known among council staff as 'The Bouncer'.
The as-yet unsolved Steamroller Murders of Spring 1979, when dozens of people were discovered crushed flat with every bone in their bodies broken, were almost certainly a result of The Bouncer's handiwork.

Add caption

No one is entirely sure what the purpose of this public information poster was. All we know is that when a council worker accidentally posted it on billboards around Scarfolk, the poster below was quickly pasted over it.

Records show that the errant, anonymous worker was soon sold to another council where his job was either to feed the council pets or be fed to the council pets. Documents don't clarify which.

Contents
• 2019: An Introduction - Donna Scott
• The Anxiety Gene - Rhiannon Grist
• The Land of Grunts and Squeaks - Chris Beckett
• For Your Own Good - Ian Whates
• Neom - Lavie Tidhar
• Once You Start - Mike Morgan
• For the Wicked, Only Weeds Will Grow - G. V. Anderson
• Fat Man in the Bardo - Ken MacLeod
• Cyberstar - Val Nolan
• The Little People - Una McCormack
• The Loimaa Protocol - Robert Bagnall
• The Adaptation Point - Kate Macdonald
• The Final Ascent - Ian Creasey
• A Lady of Ganymede, a Sparrow of Io - Dafydd McKimm
• Snapshots - Leo X. Robertson
• Witch of the Weave - Henry Szabranski
• Parasite Art - David Tallerman
• Galena - Liam Hogan
• Ab Initio - Susan Boulton
• Ghosts - Emma Levin
• Concerning the Deprivation of Sleep - Tim Major
• Every Little Star - Fiona Moore
• The Minus-Four Sequence - Andrew Wallace
My short story 'Fat Man in the Bardo', originally published in Shoreline of Infinity 14, and I'm well chuffed to see it here.
(TOC layout copy and pasted from the redoubtable Lavie Tidhar, who as you can see also has a story in it.)
At the end of April, the retail consultant Mary Portas appeared on the BBC’s World at One programme to discuss how physical shopping could continue to function during the coronavirus crisis.
Portas has a bit of form for, shall we say, car-centric ‘solutions’ to high street problems, proposing the quack remedy of free parking as a response to town centre decline, and generally arguing for unfettered access by motor traffic to shopping streets, while simultaneously paying scant attention to benign modes of transport like walking and cycling. So it was perhaps no great surprise to hear her complaining about having to pay car parking charges in London boroughs during the coronavirus pandemic, while singing the praises of department stores that have converted themselves into drive-throughs, a kind of transformation that these hidebound councils are apparently not enlightened enough to adopt.
Here's 'High Streets expert' Mary Portas advocating "luxury drive throughs" (yes, really) for retail, while moaning about current on-street parking charges. There really is going to be a battle for how our streets feel and look in the coming weeks and months pic.twitter.com/IEaugNqqrf
— Mark Treasure (@AsEasyAsRiding) April 28, 2020
I was reminded of this episode by this excellent cartoon from Dave Walker, which manages to capture the Dystopian reality of the Portas worldview in the left panel.
As he so often does, @davewalker has managed to get a very important message, clearly, into a cartoon. Decision Time. pic.twitter.com/jcXda8gjvX
— John Dales

